 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Exemplification in Long-form Question Answering via Retrieval
Paper and Code
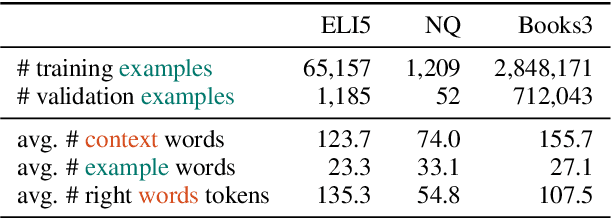
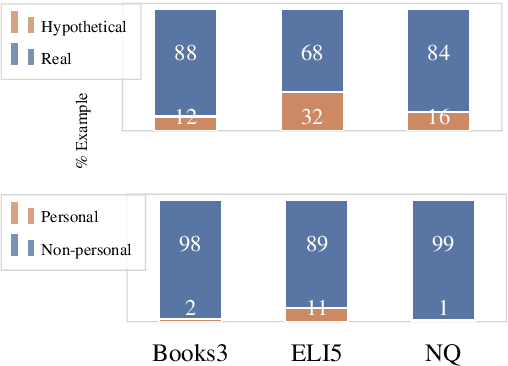
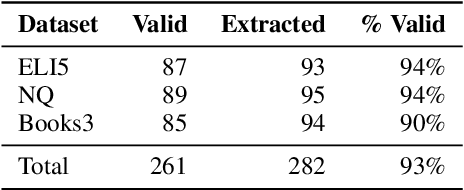
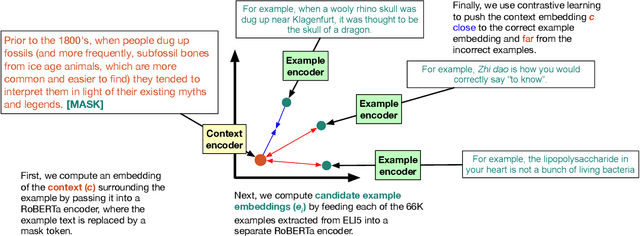
Exemplification is a process by which writers explain or clarify a concept by providing an example. While common in all forms of writing, exemplification is particularly useful in the task of long-form question answering (LFQA), where a complicated answer can be made more understandable through simple examples. In this paper, we provide the first computational study of exemplification in QA, performing a fine-grained annotation of different types of examples (e.g., hypotheticals, anecdotes) in three corpora. We show that not only do state-of-the-art LFQA models struggle to generate relevant examples, but also that standard evaluation metrics such as ROUGE are insufficient to judge exemplification quality. We propose to treat exemplification as a \emph{retrieval} problem in which a partially-written answer is used to query a large set of human-written examples extracted from a corpus. Our approach allows a reliable ranking-type automatic metrics that correlates well with human evaluation. A human evaluation shows that our model's retrieved examples are more relevant than examples generated from a state-of-the-art LFQA model.