 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Single Best Model for Diversity: Learning a Router for Sample Diversity
Apr 02, 2026When posed with prompts that permit a large number of valid answers, comprehensively generating them is the first step towards satisfying a wide range of users. In this paper, we study methods to elicit a comprehensive set of valid responses. To evaluate this, we introduce \textbf{diversity coverage}, a metric that measures the total quality scores assigned to each \textbf{unique} answer in the predicted answer set relative to the best possible answer set with the same number of answers. Using this metric, we evaluate 18 LLMs, finding no single model dominates at generating diverse responses to a wide range of open-ended prompts. Yet, per each prompt, there exists a model that outperforms all other models significantly at generating a diverse answer set. Motivated by this finding, we introduce a router that predicts the best model for each query. On NB-Wildchat, our trained router outperforms the single best model baseline (26.3% vs $23.8%). We further show generalization to an out-of-domain dataset (NB-Curated) as well as different answer-generation prompting strategies. Our work lays foundation for studying generating comprehensive answers when we have access to a suite of models.
SAGE: Steerable Agentic Data Generation for Deep Search with Execution Feedback
Jan 26, 2026Deep search agents, which aim to answer complex questions requiring reasoning across multiple documents, can significantly speed up the information-seeking process. Collecting human annotations for this application is prohibitively expensive due to long and complex exploration trajectories. We propose an agentic pipeline that automatically generates high quality, difficulty-controlled deep search question-answer pairs for a given corpus and a target difficulty level. Our pipeline, SAGE, consists of a data generator which proposes QA pairs and a search agent which attempts to solve the generated question and provide execution feedback for the data generator. The two components interact over multiple rounds to iteratively refine the question-answer pairs until they satisfy the target difficulty level. Our intrinsic evaluation shows SAGE generates questions that require diverse reasoning strategies, while significantly increases the correctness and difficulty of the generated data. Our extrinsic evaluation demonstrates up to 23% relative performance gain on popular deep search benchmarks by training deep search agents with our synthetic data. Additional experiments show that agents trained on our data can adapt from fixed-corpus retrieval to Google Search at inference time, without further training.
Recycled Attention: Efficient inference for long-context language models
Nov 08, 2024Generating long sequences of tokens given a long-context input imposes a heavy computational burden for large language models (LLMs). One of the computational bottleneck comes from computing attention over a long sequence of input at each generation step. In this paper, we propose Recycled Attention, an inference-time method which alternates between full context attention and attention over a subset of input tokens. When performing partial attention, we recycle the attention pattern of a previous token that has performed full attention and attend only to the top K most attended tokens, reducing the cost of data movement and attention computation. Compared to previously proposed inference-time acceleration method which attends only to local context or tokens with high accumulative attention scores, our approach flexibly chooses tokens that are relevant to the current decoding step. We evaluate our methods on RULER, a suite of tasks designed to comprehensively evaluate long-context abilities, and long-context language modeling tasks. Applying our method to off-the-shelf LLMs achieves comparable speedup to baselines which only consider local context while improving the performance by 2x. We further explore two ideas to improve performance-efficiency trade-offs: (1) dynamically decide when to perform recycled or full attention step based on the query similarities and (2) continued pre-training the model with Recycled Attention.
Contrastive Learning to Improve Retrieval for Real-world Fact Checking
Oct 07, 2024



Recent work on fact-checking addresses a realistic setting where models incorporate evidence retrieved from the web to decide the veracity of claims. A bottleneck in this pipeline is in retrieving relevant evidence: traditional methods may surface documents directly related to a claim, but fact-checking complex claims requires more inferences. For instance, a document about how a vaccine was developed is relevant to addressing claims about what it might contain, even if it does not address them directly. We present Contrastive Fact-Checking Reranker (CFR), an improved retriever for this setting. By leveraging the AVeriTeC dataset, which annotates subquestions for claims with human written answers from evidence documents, we fine-tune Contriever with a contrastive objective based on multiple training signals, including distillation from GPT-4, evaluating subquestion answers, and gold labels in the dataset. We evaluate our model on both retrieval and end-to-end veracity judgments about claims. On the AVeriTeC dataset, we find a 6\% improvement in veracity classification accuracy. We also show our gains can be transferred to FEVER, ClaimDecomp, HotpotQA, and a synthetic dataset requiring retrievers to make inferences.
Long-Form Answers to Visual Questions from Blind and Low Vision People
Aug 12, 2024



Vision language models can now generate long-form answers to questions about images - long-form visual question answers (LFVQA). We contribute VizWiz-LF, a dataset of long-form answers to visual questions posed by blind and low vision (BLV) users. VizWiz-LF contains 4.2k long-form answers to 600 visual questions, collected from human expert describers and six VQA models. We develop and annotate functional roles of sentences of LFVQA and demonstrate that long-form answers contain information beyond the question answer such as explanations and suggestions. We further conduct automatic and human evaluations with BLV and sighted people to evaluate long-form answers. BLV people perceive both human-written and generated long-form answers to be plausible, but generated answers often hallucinate incorrect visual details, especially for unanswerable visual questions (e.g., blurry or irrelevant images). To reduce hallucinations, we evaluate the ability of VQA models to abstain from answering unanswerable questions across multiple prompting strategies.
KIWI: A Dataset of Knowledge-Intensive Writing Instructions for Answering Research Questions
Mar 06, 2024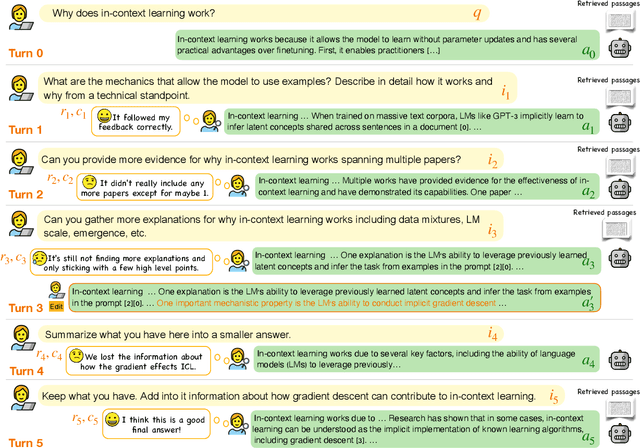

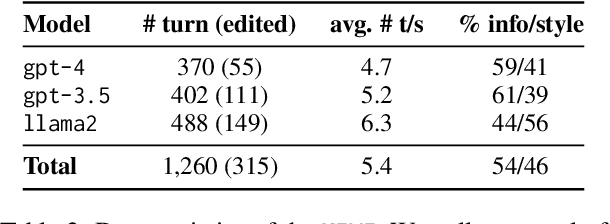
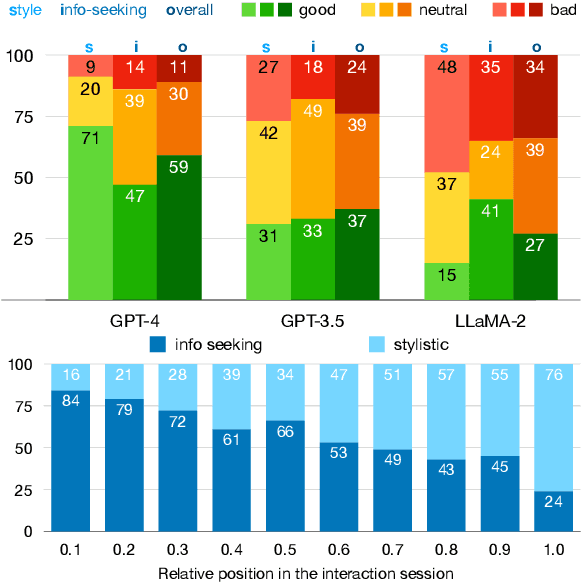
Large language models (LLMs) adapted to follow user instructions are now widely deployed as conversational agents. In this work, we examine one increasingly common instruction-following task: providing writing assistance to compose a long-form answer. To evaluate the capabilities of current LLMs on this task, we construct KIWI, a dataset of knowledge-intensive writing instructions in the scientific domain. Given a research question, an initial model-generated answer and a set of relevant papers, an expert annotator iteratively issues instructions for the model to revise and improve its answer. We collect 1,260 interaction turns from 234 interaction sessions with three state-of-the-art LLMs. Each turn includes a user instruction, a model response, and a human evaluation of the model response. Through a detailed analysis of the collected responses, we find that all models struggle to incorporate new information into an existing answer, and to perform precise and unambiguous edits. Further, we find that models struggle to judge whether their outputs successfully followed user instructions, with accuracy at least 10 points short of human agreement. Our findings indicate that KIWI will be a valuable resource to measure progress and improve LLMs' instruction-following capabilities for knowledge intensive writing tasks.
Understanding Retrieval Augmentation for Long-Form Question Answering
Oct 18, 2023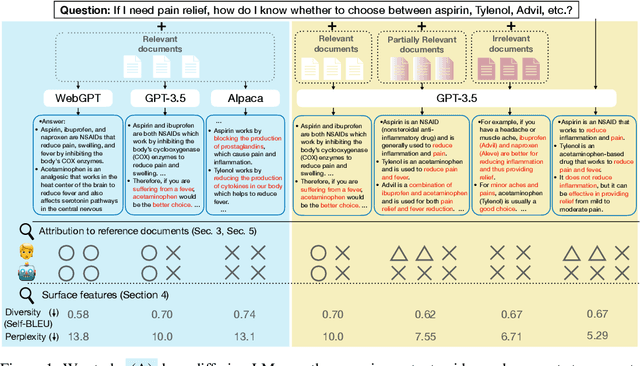
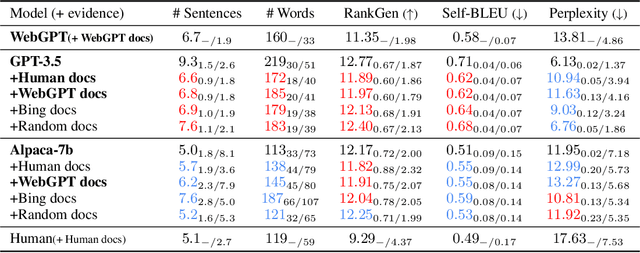

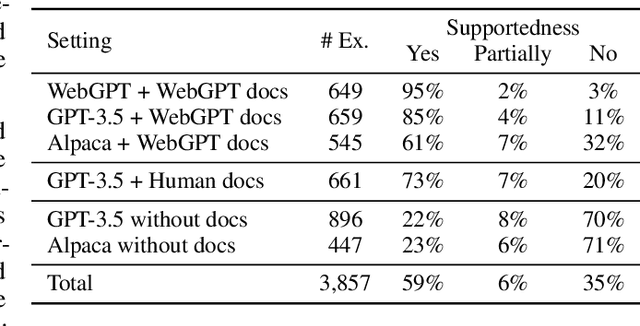
We present a study of retrieval-augmented language models (LMs) on long-form question answering. We analyze how retrieval augmentation impacts different LMs, by comparing answers generated from models while using the same evidence documents, and how differing quality of retrieval document set impacts the answers generated from the same LM. We study various attributes of generated answers (e.g., fluency, length, variance) with an emphasis on the attribution of generated long-form answers to in-context evidence documents. We collect human annotations of answer attribution and evaluate methods for automatically judging attribution. Our study provides new insights on how retrieval augmentation impacts long, knowledge-rich text generation of LMs. We further identify attribution patterns for long text generation and analyze the main culprits of attribution errors. Together, our analysis reveals how retrieval augmentation impacts long knowledge-rich text generation and provide directions for future work.
RECOMP: Improving Retrieval-Augmented LMs with Compression and Selective Augmentation
Oct 06, 2023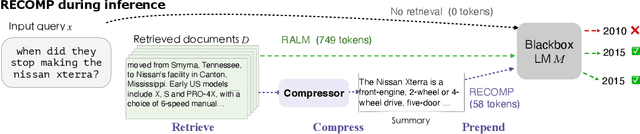
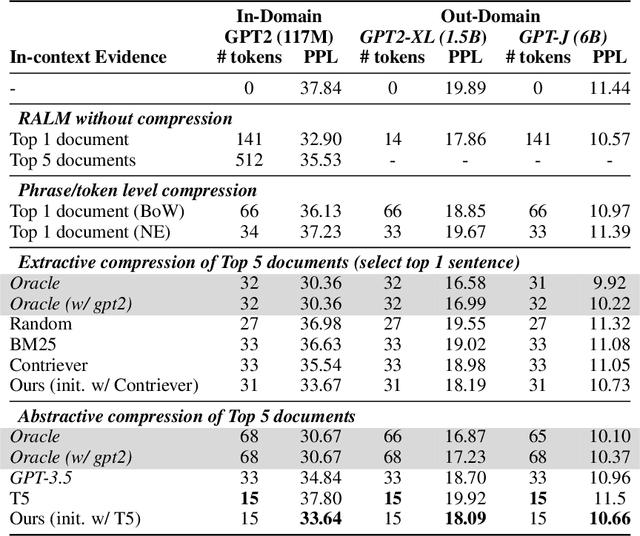
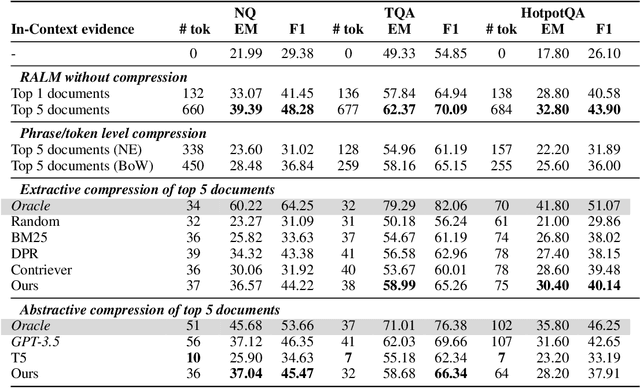

Retrieving documents and prepending them in-context at inference time improves performance of language model (LMs) on a wide range of tasks. However, these documents, often spanning hundreds of words, make inference substantially more expensive. We propose compressing the retrieved documents into textual summaries prior to in-context integration. This not only reduces the computational costs but also relieves the burden of LMs to identify relevant information in long retrieved documents. We present two compressors -- an extractive compressor which selects useful sentences from retrieved documents and an abstractive compressor which generates summaries by synthesizing information from multiple documents. Both compressors are trained to improve LMs' performance on end tasks when the generated summaries are prepended to the LMs' input, while keeping the summary concise.If the retrieved documents are irrelevant to the input or offer no additional information to LM, our compressor can return an empty string, implementing selective augmentation.We evaluate our approach on language modeling task and open domain question answering task. We achieve a compression rate of as low as 6% with minimal loss in performance for both tasks, significantly outperforming the off-the-shelf summarization models. We show that our compressors trained for one LM can transfer to other LMs on the language modeling task and provide summaries largely faithful to the retrieved documents.
Concise Answers to Complex Questions: Summarization of Long-form Answers
May 30, 2023

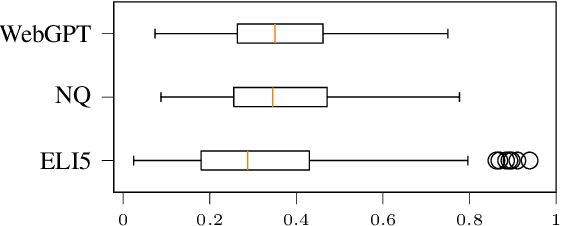
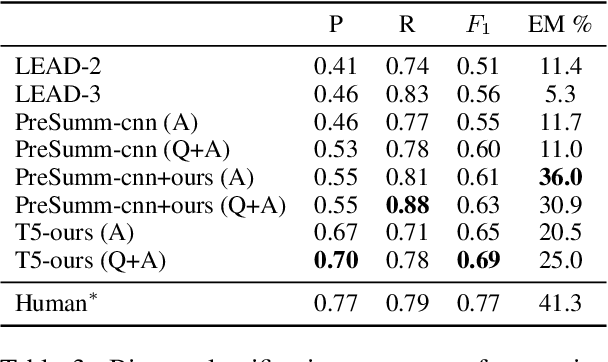
Long-form question answering systems provide rich information by presenting paragraph-level answers, often containing optional background or auxiliary information. While such comprehensive answers are helpful, not all information is required to answer the question (e.g. users with domain knowledge do not need an explanation of background). Can we provide a concise version of the answer by summarizing it, while still addressing the question? We conduct a user study on summarized answers generated from state-of-the-art models and our newly proposed extract-and-decontextualize approach. We find a large proportion of long-form answers (over 90%) in the ELI5 domain can be adequately summarized by at least one system, while complex and implicit answers are challenging to compress. We observe that decontextualization improves the quality of the extractive summary, exemplifying its potential in the summarization task. To promote future work, we provide an extractive summarization dataset covering 1K long-form answers and our user study annotations. Together, we present the first study on summarizing long-form answers, taking a step forward for QA agents that can provide answers at multiple granularities.
A Critical Evaluation of Evaluations for Long-form Question Answering
May 29, 2023


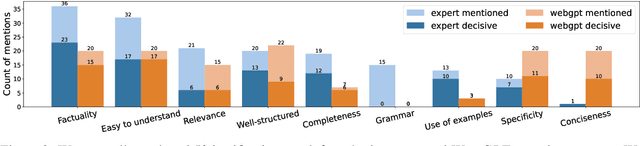
Long-form question answering (LFQA) enables answering a wide range of questions, but its flexibility poses enormous challenges for evaluation. We perform the first targeted study of the evaluation of long-form answers, covering both human and automatic evaluation practices. We hire domain experts in seven areas to provide preference judgments over pairs of answers, along with free-form justifications for their choices. We present a careful analysis of experts' evaluation, which focuses on new aspects such as the comprehensiveness of the answer. Next, we examine automatic text generation metrics, finding that no existing metrics are predictive of human preference judgments. However, some metrics correlate with fine-grained aspects of answers (e.g., coherence). We encourage future work to move away from a single "overall score" of the answer and adopt a multi-faceted evaluation, targeting aspects such as factuality and completeness. We publicly release all of our annotations and code to spur future work into LFQA evaluation.