 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Retrieval Augmentation for Long-Form Question Answering
Oct 18, 2023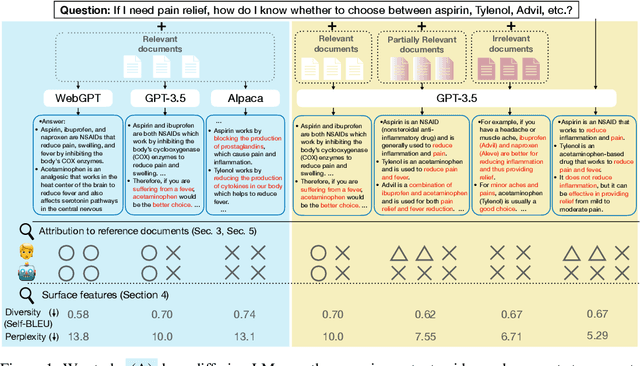
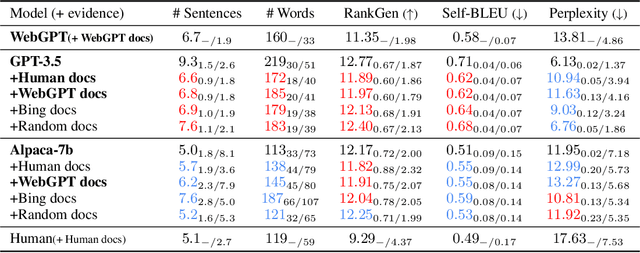

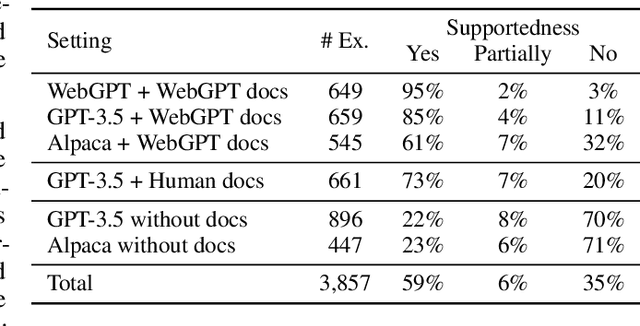
We present a study of retrieval-augmented language models (LMs) on long-form question answering. We analyze how retrieval augmentation impacts different LMs, by comparing answers generated from models while using the same evidence documents, and how differing quality of retrieval document set impacts the answers generated from the same LM. We study various attributes of generated answers (e.g., fluency, length, variance) with an emphasis on the attribution of generated long-form answers to in-context evidence documents. We collect human annotations of answer attribution and evaluate methods for automatically judging attribution. Our study provides new insights on how retrieval augmentation impacts long, knowledge-rich text generation of LMs. We further identify attribution patterns for long text generation and analyze the main culprits of attribution errors. Together, our analysis reveals how retrieval augmentation impacts long knowledge-rich text generation and provide directions for future work.