 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-World Evaluation for Retrieving Diverse Perspectives
Sep 26, 2024
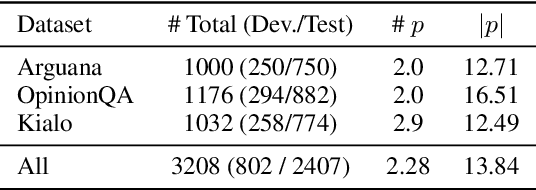


We study retrieving a set of documents that covers various perspectives on a complex and contentious question (e.g., will ChatGPT do more harm than good?). We curate a Benchmark for Retrieval Diversity for Subjective questions (BERDS), where each example consists of a question and diverse perspectives associated with the question, sourced from survey questions and debate websites. On this data, retrievers paired with a corpus are evaluated to surface a document set that contains diverse perspectives. Our framing diverges from most retrieval tasks in that document relevancy cannot be decided by simple string matches to references. Instead, we build a language model based automatic evaluator that decides whether each retrieved document contains a perspective. This allows us to evaluate the performance of three different types of corpus (Wikipedia, web snapshot, and corpus constructed on the fly with retrieved pages from the search engine) paired with retrievers. Retrieving diverse documents remains challenging, with the outputs from existing retrievers covering all perspectives on only 33.74% of the examples. We further study the impact of query expansion and diversity-focused reranking approaches and analyze retriever sycophancy. Together, we lay the foundation for future studies in retrieval diversity handling complex queries.
CaLMQA: Exploring culturally specific long-form question answering across 23 languages
Jun 25, 2024



Large language models (LLMs) are commonly used for long-form question answering, which requires them to generate paragraph-length answers to complex questions. While long-form QA has been well-studied in English via many different datasets and evaluation metrics, this research has not been extended to cover most other languages. To bridge this gap, we introduce CaLMQA, a collection of 2.6K complex questions spanning 23 languages, including under-resourced, rarely-studied languages such as Fijian and Kirundi. Our dataset includes both naturally-occurring questions collected from community web forums as well as questions written by native speakers, whom we hire for this purpose. Our process yields diverse, complex questions that reflect cultural topics (e.g. traditions, laws, news) and the language usage of native speakers. We conduct automatic evaluation across a suite of open- and closed-source models using our novel metric CaLMScore, which detects incorrect language and token repetitions in answers, and observe that the quality of LLM-generated answers degrades significantly for some low-resource languages. We perform human evaluation on a subset of models and see that model performance is significantly worse for culturally specific questions than for culturally agnostic questions. Our findings highlight the need for further research in LLM multilingual capabilities and non-English LFQA evaluation.
Understanding Retrieval Augmentation for Long-Form Question Answering
Oct 18, 2023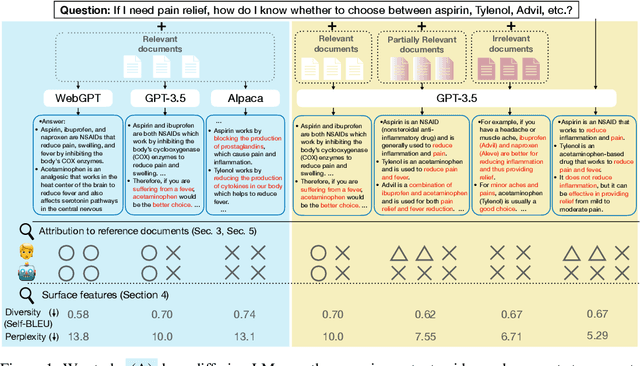
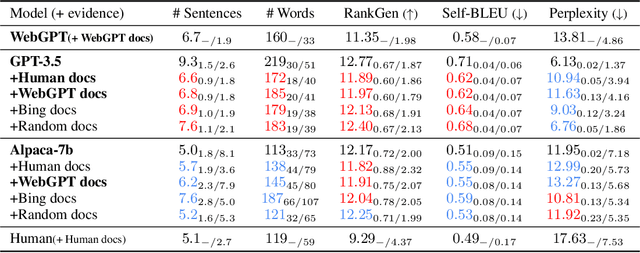

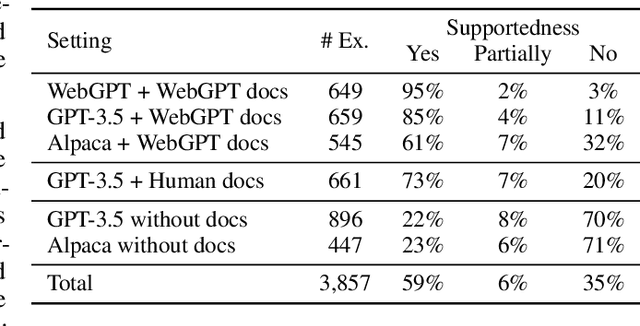
We present a study of retrieval-augmented language models (LMs) on long-form question answering. We analyze how retrieval augmentation impacts different LMs, by comparing answers generated from models while using the same evidence documents, and how differing quality of retrieval document set impacts the answers generated from the same LM. We study various attributes of generated answers (e.g., fluency, length, variance) with an emphasis on the attribution of generated long-form answers to in-context evidence documents. We collect human annotations of answer attribution and evaluate methods for automatically judging attribution. Our study provides new insights on how retrieval augmentation impacts long, knowledge-rich text generation of LMs. We further identify attribution patterns for long text generation and analyze the main culprits of attribution errors. Together, our analysis reveals how retrieval augmentation impacts long knowledge-rich text generation and provide directions for future work.
Continually Improving Extractive QA via Human Feedback
May 21, 2023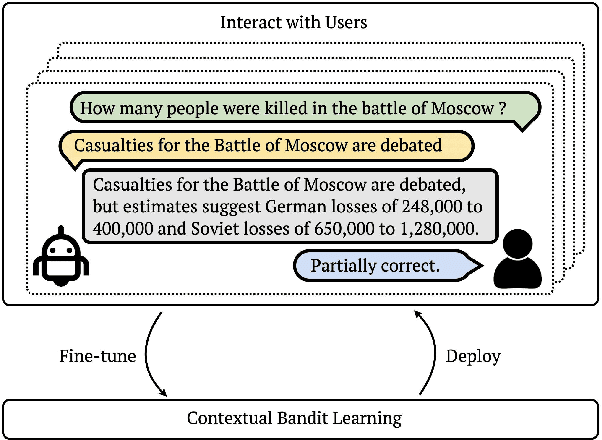

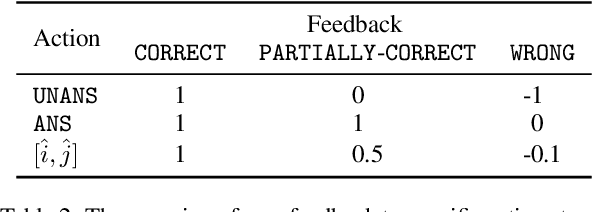
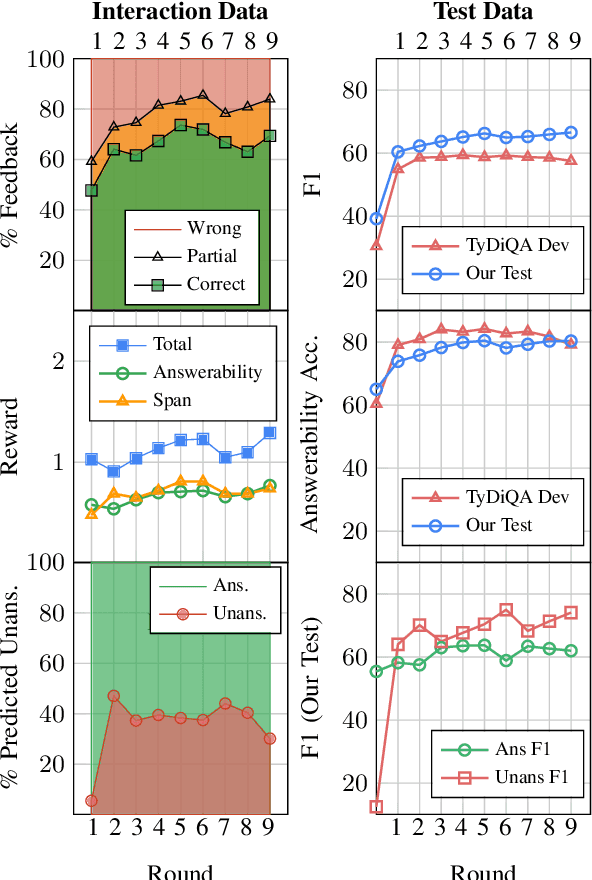
We study continually improving an extractive question answering (QA) system via human user feedback. We design and deploy an iterative approach, where information-seeking users ask questions, receive model-predicted answers, and provide feedback. We conduct experiments involving thousands of user interactions under diverse setups to broaden the understanding of learning from feedback over time. Our experiments show effective improvement from user feedback of extractive QA models over time across different data regimes, including significant potential for domain adaptation.
Rich Knowledge Sources Bring Complex Knowledge Conflicts: Recalibrating Models to Reflect Conflicting Evidence
Oct 25, 2022



Question answering models can use rich knowledge sources -- up to one hundred retrieved passages and parametric knowledge in the large-scale language model (LM). Prior work assumes information in such knowledge sources is consistent with each other, paying little attention to how models blend information stored in their LM parameters with that from retrieved evidence documents. In this paper, we simulate knowledge conflicts (i.e., where parametric knowledge suggests one answer and different passages suggest different answers) and examine model behaviors. We find retrieval performance heavily impacts which sources models rely on, and current models mostly rely on non-parametric knowledge in their best-performing settings. We discover a troubling trend that contradictions among knowledge sources affect model confidence only marginally. To address this issue, we present a new calibration study, where models are discouraged from presenting any single answer when presented with multiple conflicting answer candidates in retrieved evidences.
Predict and Use Latent Patterns for Short-Text Conversation
Oct 27, 2020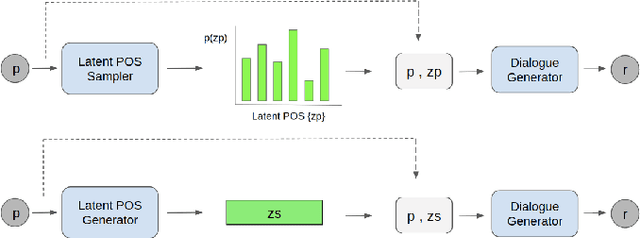
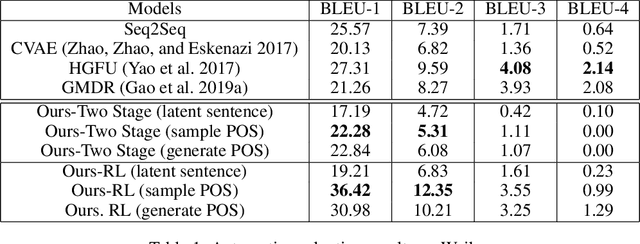

Many neural network models nowadays have achieved promising performances in Chit-chat settings. The majority of them rely on an encoder for understanding the post and a decoder for generating the response. Without given assigned semantics, the models lack the fine-grained control over responses as the semantic mapping between posts and responses is hidden on the fly within the end-to-end manners. Some previous works utilize sampled latent words as a controllable semantic form to drive the generated response around the work, but few works attempt to use more complex semantic forms to guide the generation. In this paper, we propose to use more detailed semantic forms, including latent responses and part-of-speech sequences sampled from the corresponding distributions, as the controllable semantics to guide the generation. Our experimental results show that the richer semantics are not only able to provide informative and diverse responses, but also increase the overall performance of response quality, including fluency and coherence.