 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLM-as-a-Judge Inference with the Judgment Distribution
Mar 04, 2025Using language models to scalably approximate human preferences on text quality (LLM-as-a-judge) has become a standard practice applicable to many tasks. A judgment is often extracted from the judge's textual output alone, typically with greedy decoding. However, LLM judges naturally provide distributions over judgment tokens, inviting a breadth of inference methods for extracting fine-grained preferences. We find that taking the mean of the judgment distribution consistently outperforms taking the mode (i.e. greedy decoding) in all evaluation settings (i.e. pointwise, pairwise, and listwise). We further explore novel methods of deriving preferences from judgment distributions, and find that methods incorporating risk aversion often improve performance. Lastly, we analyze LLM-as-a-judge paired with chain-of-thought (CoT) prompting, showing that CoT can collapse the spread of the judgment distribution, often harming performance. Our findings suggest leveraging distributional output can improve LLM-as-a-judge, as opposed to using the text interface alone.
Modeling Future Conversation Turns to Teach LLMs to Ask Clarifying Questions
Oct 17, 2024



Large language models (LLMs) must often respond to highly ambiguous user requests. In such cases, the LLM's best response may be to ask a clarifying question to elicit more information. We observe existing LLMs often respond by presupposing a single interpretation of such ambiguous requests, frustrating users who intended a different interpretation. We speculate this is caused by current preference data labeling practice, where LLM responses are evaluated only on their prior contexts. To address this, we propose to assign preference labels by simulating their expected outcomes in the future turns. This allows LLMs to learn to ask clarifying questions when it can generate responses that are tailored to each user interpretation in future turns. In experiments on open-domain QA, we compare systems that trained using our proposed preference labeling methods against standard methods, which assign preferences based on only prior context. We evaluate systems based on their ability to ask clarifying questions that can recover each user's interpretation and expected answer, and find that our training with our proposed method trains LLMs to ask clarifying questions with a 5% improvement in F1 measured against the answer set from different interpretations of each query
Clarify When Necessary: Resolving Ambiguity Through Interaction with LMs
Nov 16, 2023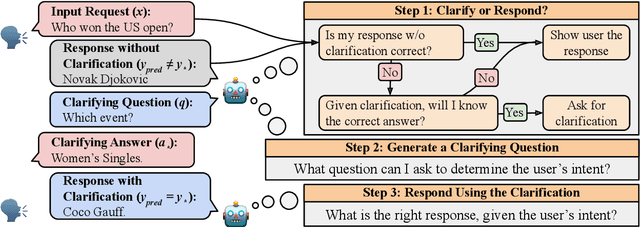

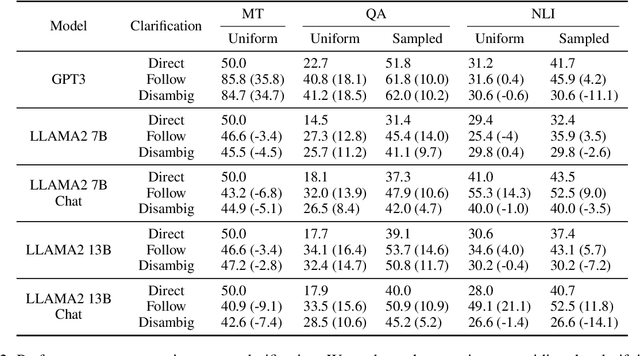

Resolving ambiguities through interaction is a hallmark of natural language, and modeling this behavior is a core challenge in crafting AI assistants. In this work, we study such behavior in LMs by proposing a task-agnostic framework for resolving ambiguity by asking users clarifying questions. Our framework breaks down this objective into three subtasks: (1) determining when clarification is needed, (2) determining what clarifying question to ask, and (3) responding accurately with the new information gathered through clarification. We evaluate systems across three NLP applications: question answering, machine translation and natural language inference. For the first subtask, we present a novel uncertainty estimation approach, intent-sim, that determines the utility of querying for clarification by estimating the entropy over user intents. Our method consistently outperforms existing uncertainty estimation approaches at identifying predictions that will benefit from clarification. When only allowed to ask for clarification on 10% of examples, our system is able to double the performance gains over randomly selecting examples to clarify. Furthermore, we find that intent-sim is robust, demonstrating improvements across a wide range of NLP tasks and LMs. Together, our work lays foundation for studying clarifying interactions with LMs.
Propagating Knowledge Updates to LMs Through Distillation
Jun 15, 2023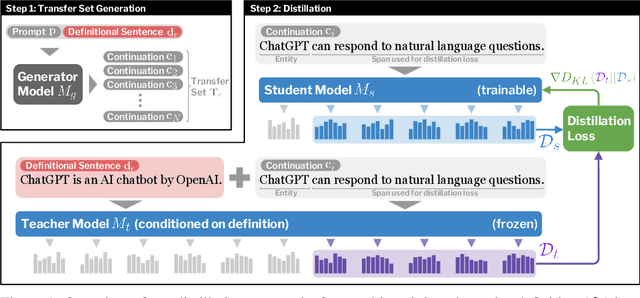
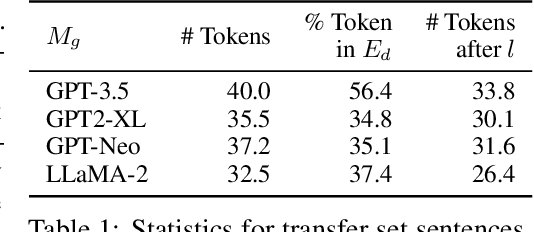
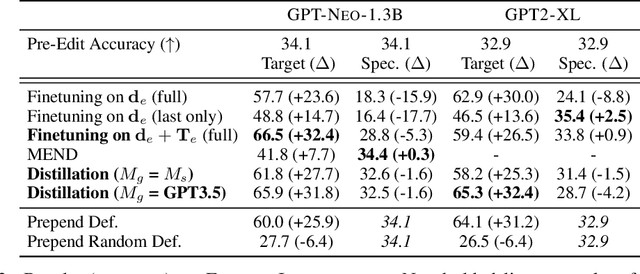
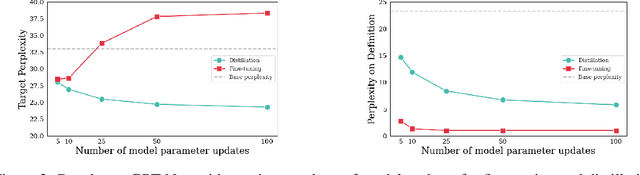
Modern language models have the capacity to store and use immense amounts of knowledge about real-world entities, but it remains unclear how to update their implicit "knowledge bases.'' While prior methods for updating knowledge in LMs successfully inject facts, updated LMs then fail to make inferences based on these injected facts. In this work, we demonstrate that a context distillation-based approach can both impart knowledge about entities and propagate that knowledge to enable broader inferences. Our approach consists of two stages: transfer set generation and distillation on the transfer set. We first generate a transfer set by simply prompting a language model to generate a continuation from the entity definition. Then, we update the model parameters so that the distribution of the LM (the student) matches the distribution of the LM conditioned on the definition (the teacher) on the transfer set. Our experiments demonstrate that this approach is more effective in propagating knowledge updates compared to fine-tuning and other gradient-based knowledge-editing methods without compromising performance in other contexts, even when injecting the definitions of up to 150 entities at once.
Selectively Answering Ambiguous Questions
May 24, 2023Trustworthy language models should abstain from answering questions when they do not know the answer. However, the answer to a question can be unknown for a variety of reasons. Prior research has focused on the case in which the question is clear and the answer is unambiguous but possibly unknown. However, the answer to a question can also be unclear due to uncertainty of the questioner's intent or context. We investigate question answering from this perspective, focusing on answering a subset of questions with a high degree of accuracy, from a set of questions in which many are inherently ambiguous. In this setting, we find that the most reliable approach to calibration involves quantifying repetition within a set of sampled model outputs, rather than the model's likelihood or self-verification as used in prior work. % We find this to be the case across different types of uncertainty, varying model scales and both with or without instruction tuning. Our results suggest that sampling-based confidence scores help calibrate answers to relatively unambiguous questions, with more dramatic improvements on ambiguous questions.
Mitigating Temporal Misalignment by Discarding Outdated Facts
May 24, 2023
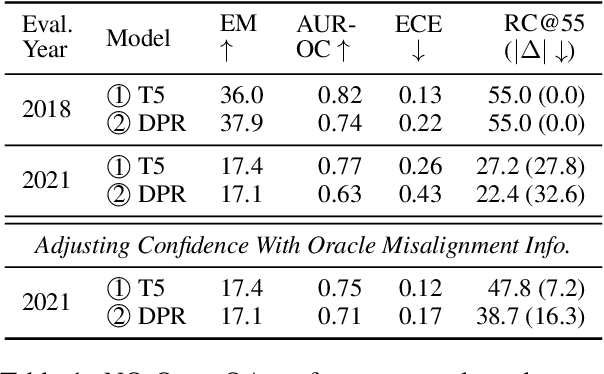
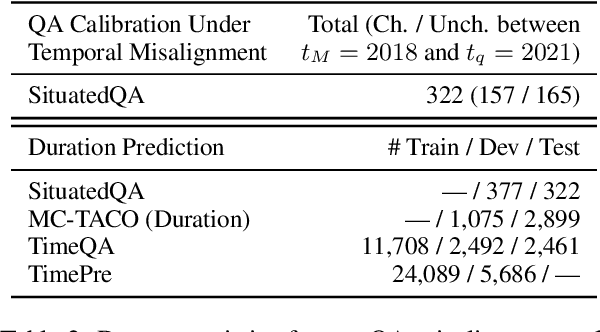

While large language models are able to retain vast amounts of world knowledge seen during pretraining, such knowledge is prone to going out of date and is nontrivial to update. Furthermore, these models are often used under temporal misalignment, tasked with answering questions about the present, despite having only been trained on data collected in the past. To mitigate the effects of temporal misalignment, we propose fact duration prediction: the task of predicting how long a given fact will remain true. In our experiments, we demonstrate how identifying facts that are prone to rapid change can help models avoid from reciting outdated information and identify which predictions require seeking out up-to-date knowledge sources. We also show how modeling fact duration improves calibration for knowledge-intensive tasks, such as open-retrieval question answering, under temporal misalignment by discarding volatile facts. Our data and code will be released publicly at https://github.com/mikejqzhang/mitigating_misalignment.
Can LMs Learn New Entities from Descriptions? Challenges in Propagating Injected Knowledge
May 02, 2023


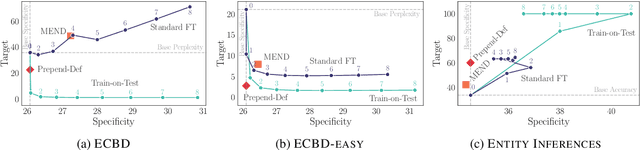
Pre-trained language models (LMs) are used for knowledge intensive tasks like question answering, but their knowledge gets continuously outdated as the world changes. Prior work has studied targeted updates to LMs, injecting individual facts and evaluating whether the model learns these facts while not changing predictions on other contexts. We take a step forward and study LMs' abilities to make inferences based on injected facts (or propagate those facts): for example, after learning that something is a TV show, does an LM predict that you can watch it? We study this with two cloze-style tasks: an existing dataset of real-world sentences about novel entities (ECBD) as well as a new controlled benchmark with manually designed templates requiring varying levels of inference about injected knowledge. Surprisingly, we find that existing methods for updating knowledge (gradient-based fine-tuning and modifications of this approach) show little propagation of injected knowledge. These methods improve performance on cloze instances only when there is lexical overlap between injected facts and target inferences. Yet, prepending entity definitions in an LM's context improves performance across all settings, suggesting that there is substantial headroom for parameter-updating approaches for knowledge injection.
DIFFQG: Generating Questions to Summarize Factual Changes
Mar 01, 2023
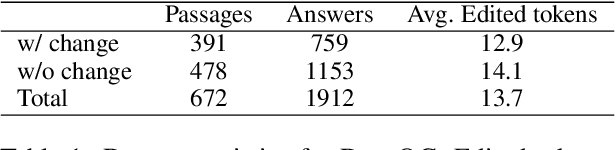
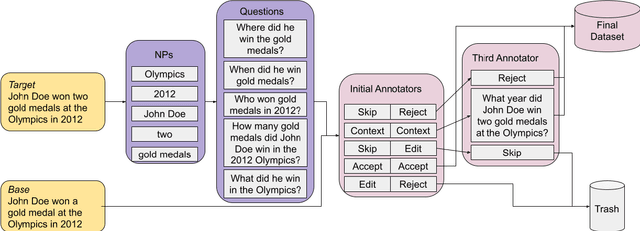
Identifying the difference between two versions of the same article is useful to update knowledge bases and to understand how articles evolve. Paired texts occur naturally in diverse situations: reporters write similar news stories and maintainers of authoritative websites must keep their information up to date. We propose representing factual changes between paired documents as question-answer pairs, where the answer to the same question differs between two versions. We find that question-answer pairs can flexibly and concisely capture the updated contents. Provided with paired documents, annotators identify questions that are answered by one passage but answered differently or cannot be answered by the other. We release DIFFQG which consists of 759 QA pairs and 1153 examples of paired passages with no factual change. These questions are intended to be both unambiguous and information-seeking and involve complex edits, pushing beyond the capabilities of current question generation and factual change detection systems. Our dataset summarizes the changes between two versions of the document as questions and answers, studying automatic update summarization in a novel way.
Rich Knowledge Sources Bring Complex Knowledge Conflicts: Recalibrating Models to Reflect Conflicting Evidence
Oct 25, 2022



Question answering models can use rich knowledge sources -- up to one hundred retrieved passages and parametric knowledge in the large-scale language model (LM). Prior work assumes information in such knowledge sources is consistent with each other, paying little attention to how models blend information stored in their LM parameters with that from retrieved evidence documents. In this paper, we simulate knowledge conflicts (i.e., where parametric knowledge suggests one answer and different passages suggest different answers) and examine model behaviors. We find retrieval performance heavily impacts which sources models rely on, and current models mostly rely on non-parametric knowledge in their best-performing settings. We discover a troubling trend that contradictions among knowledge sources affect model confidence only marginally. To address this issue, we present a new calibration study, where models are discouraged from presenting any single answer when presented with multiple conflicting answer candidates in retrieved evidences.
Entity Cloze By Date: What LMs Know About Unseen Entities
May 05, 2022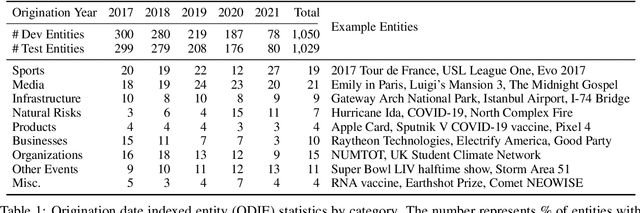

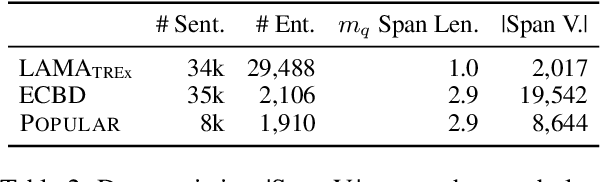
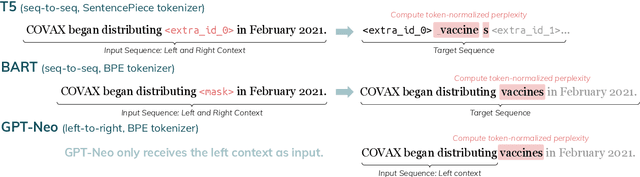
Language models (LMs) are typically trained once on a large-scale corpus and used for years without being updated. However, in a dynamic world, new entities constantly arise. We propose a framework to analyze what LMs can infer about new entities that did not exist when the LMs were pretrained. We derive a dataset of entities indexed by their origination date and paired with their English Wikipedia articles, from which we can find sentences about each entity. We evaluate LMs' perplexity on masked spans within these sentences. We show that models more informed about the entities, such as those with access to a textual definition of them, achieve lower perplexity on this benchmark. Our experimental results demonstrate that making inferences about new entities remains difficult for LMs. Given its wide coverage on entity knowledge and temporal indexing, our dataset can be used to evaluate LMs and techniques designed to modify or extend their knowledge. Our automatic data collection pipeline can be easily used to continually update our benchmark.