 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropagating Knowledge Updates to LMs Through Distillation
Paper and Code
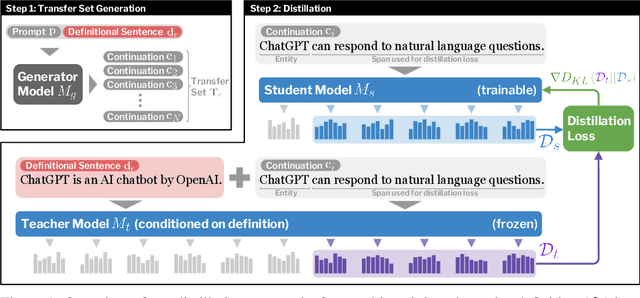
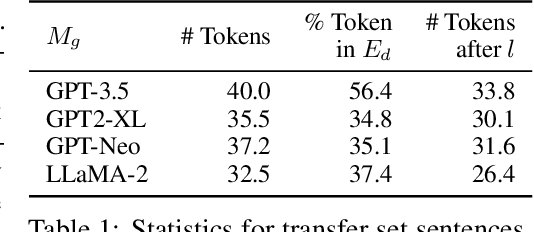
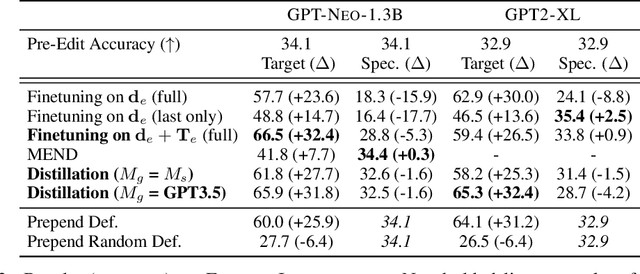
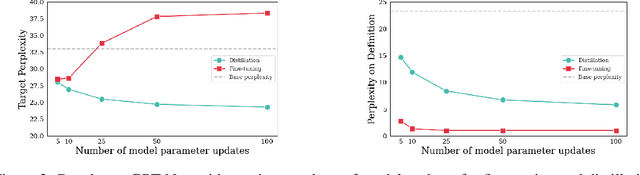
Modern language models have the capacity to store and use immense amounts of knowledge about real-world entities, but it remains unclear how to update their implicit "knowledge bases.'' While prior methods for updating knowledge in LMs successfully inject facts, updated LMs then fail to make inferences based on these injected facts. In this work, we demonstrate that a context distillation-based approach can both impart knowledge about entities and propagate that knowledge to enable broader inferences. Our approach consists of two stages: transfer set generation and distillation on the transfer set. We first generate a transfer set by simply prompting a language model to generate a continuation from the entity definition. Then, we update the model parameters so that the distribution of the LM (the student) matches the distribution of the LM conditioned on the definition (the teacher) on the transfer set. Our experiments demonstrate that this approach is more effective in propagating knowledge updates compared to fine-tuning and other gradient-based knowledge-editing methods without compromising performance in other contexts, even when injecting the definitions of up to 150 entities at once.