 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpdating Parametric Knowledge with Context Distillation Retains Post-Training Capabilities
Feb 17, 2026Post-training endows pretrained LLMs with a variety of desirable skills, including instruction-following, reasoning, and others. However, these post-trained LLMs only encode knowledge up to a cut-off date, necessitating continual adaptation. Unfortunately, existing solutions cannot simultaneously learn new knowledge from an adaptation document corpora and mitigate the forgetting of earlier learned capabilities. To address this, we introduce Distillation via Split Contexts (DiSC), a simple context-distillation based approach for continual knowledge adaptation. \methodname~derives student and teacher distributions by conditioning on distinct segments of the training example and minimizes the KL divergence between the shared tokens. This allows us to efficiently apply context-distillation without requiring explicit generation steps during training. We run experiments on four post-trained models and two adaptation domains. Compared to prior finetuning and distillation methods for continual adaptation, DiSC consistently reports the best trade-off between learning new knowledge and mitigating forgetting of previously learned skills like instruction-following, reasoning, and factual knowledge.
Propagating Knowledge Updates to LMs Through Distillation
Jun 15, 2023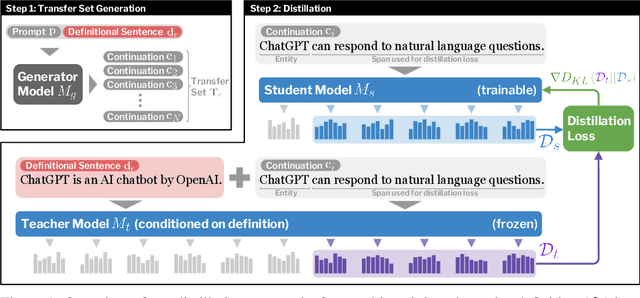
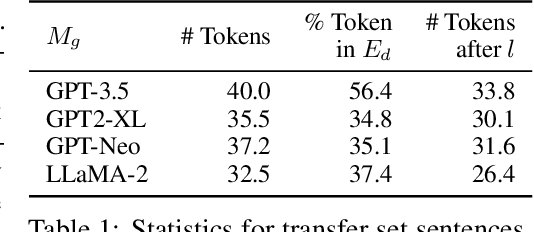
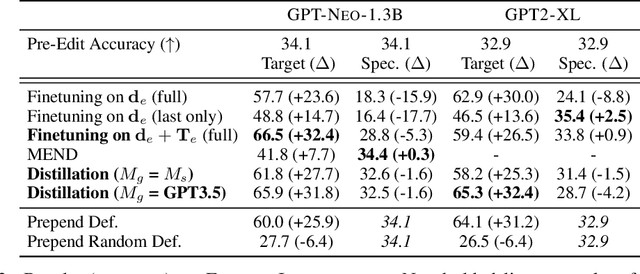
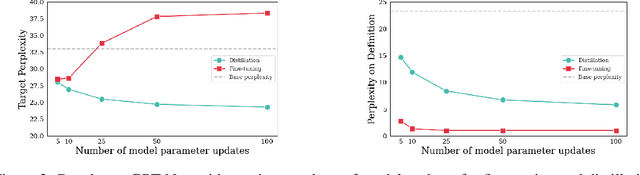
Modern language models have the capacity to store and use immense amounts of knowledge about real-world entities, but it remains unclear how to update their implicit "knowledge bases.'' While prior methods for updating knowledge in LMs successfully inject facts, updated LMs then fail to make inferences based on these injected facts. In this work, we demonstrate that a context distillation-based approach can both impart knowledge about entities and propagate that knowledge to enable broader inferences. Our approach consists of two stages: transfer set generation and distillation on the transfer set. We first generate a transfer set by simply prompting a language model to generate a continuation from the entity definition. Then, we update the model parameters so that the distribution of the LM (the student) matches the distribution of the LM conditioned on the definition (the teacher) on the transfer set. Our experiments demonstrate that this approach is more effective in propagating knowledge updates compared to fine-tuning and other gradient-based knowledge-editing methods without compromising performance in other contexts, even when injecting the definitions of up to 150 entities at once.
Can LMs Learn New Entities from Descriptions? Challenges in Propagating Injected Knowledge
May 02, 2023


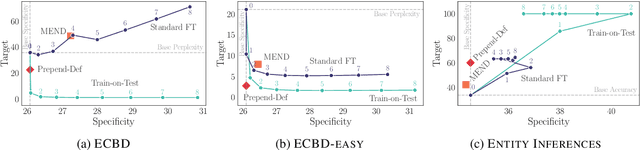
Pre-trained language models (LMs) are used for knowledge intensive tasks like question answering, but their knowledge gets continuously outdated as the world changes. Prior work has studied targeted updates to LMs, injecting individual facts and evaluating whether the model learns these facts while not changing predictions on other contexts. We take a step forward and study LMs' abilities to make inferences based on injected facts (or propagate those facts): for example, after learning that something is a TV show, does an LM predict that you can watch it? We study this with two cloze-style tasks: an existing dataset of real-world sentences about novel entities (ECBD) as well as a new controlled benchmark with manually designed templates requiring varying levels of inference about injected knowledge. Surprisingly, we find that existing methods for updating knowledge (gradient-based fine-tuning and modifications of this approach) show little propagation of injected knowledge. These methods improve performance on cloze instances only when there is lexical overlap between injected facts and target inferences. Yet, prepending entity definitions in an LM's context improves performance across all settings, suggesting that there is substantial headroom for parameter-updating approaches for knowledge injection.
Optimal Placement of Public Electric Vehicle Charging Stations Using Deep Reinforcement Learning
Aug 17, 2021
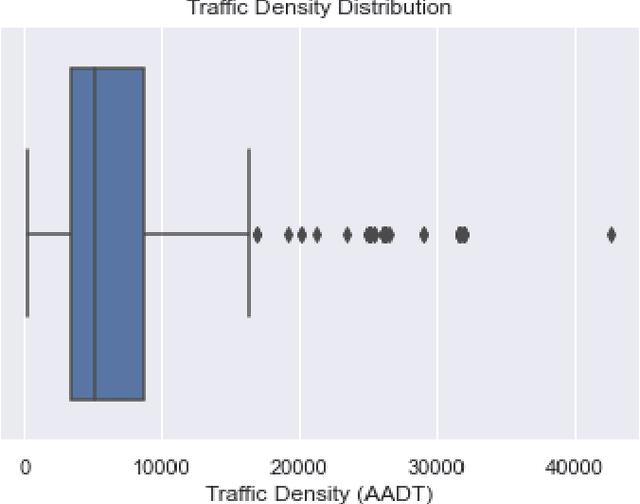
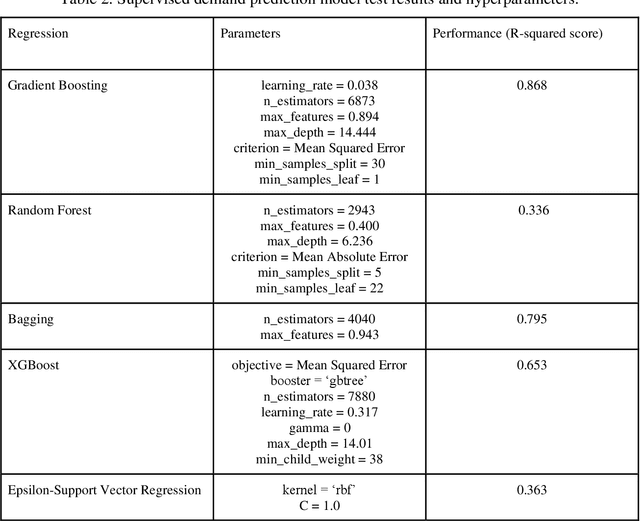
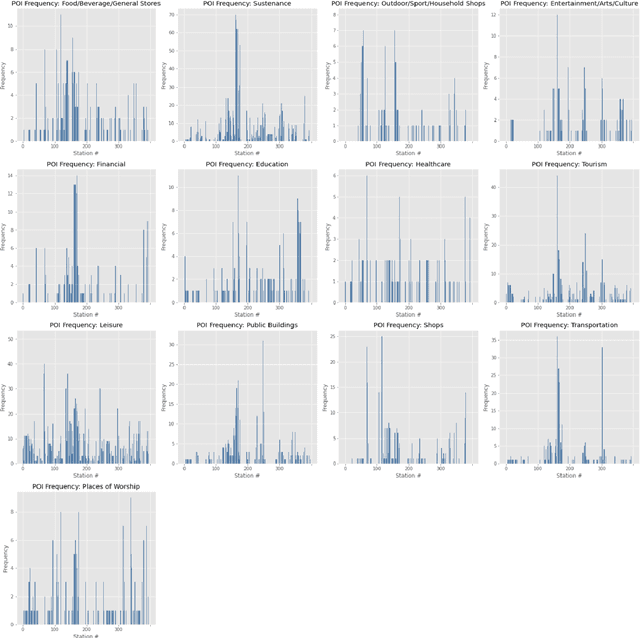
The placement of charging stations in areas with developing charging infrastructure is a critical component of the future success of electric vehicles (EVs). In Albany County in New York, the expected rise in the EV population requires additional charging stations to maintain a sufficient level of efficiency across the charging infrastructure. A novel application of Reinforcement Learning (RL) is able to find optimal locations for new charging stations given the predicted charging demand and current charging locations. The most important factors that influence charging demand prediction include the conterminous traffic density, EV registrations, and proximity to certain types of public buildings. The proposed RL framework can be refined and applied to cities across the world to optimize charging station placement.