 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnblocking Fine-Grained Evaluation of Detailed Captions: An Explaining AutoRater and Critic-and-Revise Pipeline
Jun 09, 2025Large Vision-Language Models (VLMs) now generate highly detailed, paragraphlength image captions, yet evaluating their factual accuracy remains challenging. Current methods often miss fine-grained errors, being designed for shorter texts or lacking datasets with verified inaccuracies. We introduce DOCCI-Critique, a benchmark with 1,400 VLM-generated paragraph captions (100 images, 14 VLMs) featuring over 10,216 sentence-level human annotations of factual correctness and explanatory rationales for errors, all within paragraph context. Building on this, we develop VNLI-Critique, a model for automated sentence-level factuality classification and critique generation. We highlight three key applications: (1) VNLI-Critique demonstrates robust generalization, validated by state-of-the-art performance on the M-HalDetect benchmark and strong results in CHOCOLATE claim verification. (2) The VNLI-Critique driven AutoRater for DOCCI-Critique provides reliable VLM rankings, showing excellent alignment with human factuality judgments (e.g., 0.98 Spearman). (3) An innovative Critic-and-Revise pipeline, where critiques from VNLI-Critique guide LLM-based corrections, achieves substantial improvements in caption factuality (e.g., a 46% gain on DetailCaps-4870). Our work offers a crucial benchmark alongside practical tools, designed to significantly elevate the standards for fine-grained evaluation and foster the improvement of VLM image understanding. Project page: https://google.github.io/unblocking-detail-caption
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
May 27, 2024



We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {\it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {\it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
ImageInWords: Unlocking Hyper-Detailed Image Descriptions
May 05, 2024



Despite the longstanding adage "an image is worth a thousand words," creating accurate and hyper-detailed image descriptions for training Vision-Language models remains challenging. Current datasets typically have web-scraped descriptions that are short, low-granularity, and often contain details unrelated to the visual content. As a result, models trained on such data generate descriptions replete with missing information, visual inconsistencies, and hallucinations. To address these issues, we introduce ImageInWords (IIW), a carefully designed human-in-the-loop annotation framework for curating hyper-detailed image descriptions and a new dataset resulting from this process. We validate the framework through evaluations focused on the quality of the dataset and its utility for fine-tuning with considerations for readability, comprehensiveness, specificity, hallucinations, and human-likeness. Our dataset significantly improves across these dimensions compared to recently released datasets (+66%) and GPT-4V outputs (+48%). Furthermore, models fine-tuned with IIW data excel by +31% against prior work along the same human evaluation dimensions. Given our fine-tuned models, we also evaluate text-to-image generation and vision-language reasoning. Our model's descriptions can generate images closest to the original, as judged by both automated and human metrics. We also find our model produces more compositionally rich descriptions, outperforming the best baseline by up to 6% on ARO, SVO-Probes, and Winoground datasets.
DOCCI: Descriptions of Connected and Contrasting Images
Apr 30, 2024



Vision-language datasets are vital for both text-to-image (T2I) and image-to-text (I2T) research. However, current datasets lack descriptions with fine-grained detail that would allow for richer associations to be learned by models. To fill the gap, we introduce Descriptions of Connected and Contrasting Images (DOCCI), a dataset with long, human-annotated English descriptions for 15k images that were taken, curated and donated by a single researcher intent on capturing key challenges such as spatial relations, counting, text rendering, world knowledge, and more. We instruct human annotators to create comprehensive descriptions for each image; these average 136 words in length and are crafted to clearly distinguish each image from those that are related or similar. Each description is highly compositional and typically encompasses multiple challenges. Through both quantitative and qualitative analyses, we demonstrate that DOCCI serves as an effective training resource for image-to-text generation -- a PaLI 5B model finetuned on DOCCI shows equal or superior results compared to highly-performant larger models like LLaVA-1.5 7B and InstructBLIP 7B. Furthermore, we show that DOCCI is a useful testbed for text-to-image generation, highlighting the limitations of current text-to-image models in capturing long descriptions and fine details.
Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratings
Apr 25, 2024While text-to-image (T2I) generative models have become ubiquitous, they do not necessarily generate images that align with a given prompt. While previous work has evaluated T2I alignment by proposing metrics, benchmarks, and templates for collecting human judgements, the quality of these components is not systematically measured. Human-rated prompt sets are generally small and the reliability of the ratings -- and thereby the prompt set used to compare models -- is not evaluated. We address this gap by performing an extensive study evaluating auto-eval metrics and human templates. We provide three main contributions: (1) We introduce a comprehensive skills-based benchmark that can discriminate models across different human templates. This skills-based benchmark categorises prompts into sub-skills, allowing a practitioner to pinpoint not only which skills are challenging, but at what level of complexity a skill becomes challenging. (2) We gather human ratings across four templates and four T2I models for a total of >100K annotations. This allows us to understand where differences arise due to inherent ambiguity in the prompt and where they arise due to differences in metric and model quality. (3) Finally, we introduce a new QA-based auto-eval metric that is better correlated with human ratings than existing metrics for our new dataset, across different human templates, and on TIFA160.
Jamp: Controlled Japanese Temporal Inference Dataset for Evaluating Generalization Capacity of Language Models
Jun 19, 2023



Natural Language Inference (NLI) tasks involving temporal inference remain challenging for pre-trained language models (LMs). Although various datasets have been created for this task, they primarily focus on English and do not address the need for resources in other languages. It is unclear whether current LMs realize the generalization capacity for temporal inference across languages. In this paper, we present Jamp, a Japanese NLI benchmark focused on temporal inference. Our dataset includes a range of temporal inference patterns, which enables us to conduct fine-grained analysis. To begin the data annotation process, we create diverse inference templates based on the formal semantics test suites. We then automatically generate diverse NLI examples by using the Japanese case frame dictionary and well-designed templates while controlling the distribution of inference patterns and gold labels. We evaluate the generalization capacities of monolingual/multilingual LMs by splitting our dataset based on tense fragments (i.e., temporal inference patterns). Our findings demonstrate that LMs struggle with specific linguistic phenomena, such as habituality, indicating that there is potential for the development of more effective NLI models across languages.
Propagating Knowledge Updates to LMs Through Distillation
Jun 15, 2023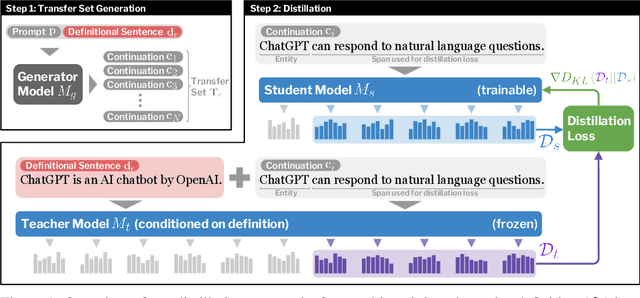
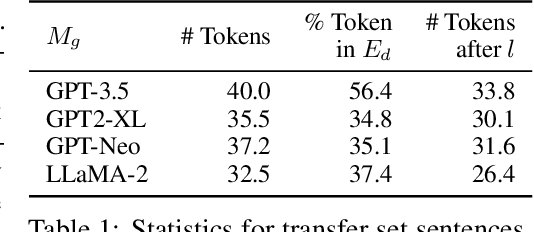
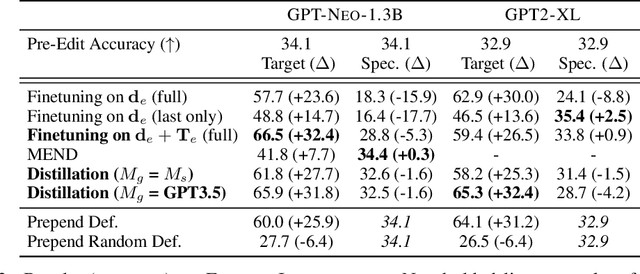
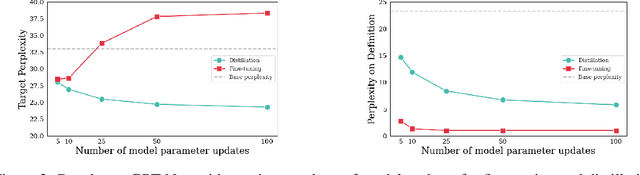
Modern language models have the capacity to store and use immense amounts of knowledge about real-world entities, but it remains unclear how to update their implicit "knowledge bases.'' While prior methods for updating knowledge in LMs successfully inject facts, updated LMs then fail to make inferences based on these injected facts. In this work, we demonstrate that a context distillation-based approach can both impart knowledge about entities and propagate that knowledge to enable broader inferences. Our approach consists of two stages: transfer set generation and distillation on the transfer set. We first generate a transfer set by simply prompting a language model to generate a continuation from the entity definition. Then, we update the model parameters so that the distribution of the LM (the student) matches the distribution of the LM conditioned on the definition (the teacher) on the transfer set. Our experiments demonstrate that this approach is more effective in propagating knowledge updates compared to fine-tuning and other gradient-based knowledge-editing methods without compromising performance in other contexts, even when injecting the definitions of up to 150 entities at once.
Can LMs Learn New Entities from Descriptions? Challenges in Propagating Injected Knowledge
May 02, 2023


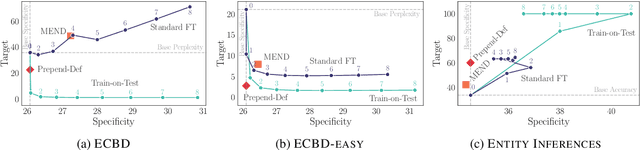
Pre-trained language models (LMs) are used for knowledge intensive tasks like question answering, but their knowledge gets continuously outdated as the world changes. Prior work has studied targeted updates to LMs, injecting individual facts and evaluating whether the model learns these facts while not changing predictions on other contexts. We take a step forward and study LMs' abilities to make inferences based on injected facts (or propagate those facts): for example, after learning that something is a TV show, does an LM predict that you can watch it? We study this with two cloze-style tasks: an existing dataset of real-world sentences about novel entities (ECBD) as well as a new controlled benchmark with manually designed templates requiring varying levels of inference about injected knowledge. Surprisingly, we find that existing methods for updating knowledge (gradient-based fine-tuning and modifications of this approach) show little propagation of injected knowledge. These methods improve performance on cloze instances only when there is lexical overlap between injected facts and target inferences. Yet, prepending entity definitions in an LM's context improves performance across all settings, suggesting that there is substantial headroom for parameter-updating approaches for knowledge injection.
Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting
Dec 13, 2022



Text-guided image editing can have a transformative impact in supporting creative applications. A key challenge is to generate edits that are faithful to input text prompts, while consistent with input images. We present Imagen Editor, a cascaded diffusion model built, by fine-tuning Imagen on text-guided image inpainting. Imagen Editor's edits are faithful to the text prompts, which is accomplished by using object detectors to propose inpainting masks during training. In addition, Imagen Editor captures fine details in the input image by conditioning the cascaded pipeline on the original high resolution image. To improve qualitative and quantitative evaluation, we introduce EditBench, a systematic benchmark for text-guided image inpainting. EditBench evaluates inpainting edits on natural and generated images exploring objects, attributes, and scenes. Through extensive human evaluation on EditBench, we find that object-masking during training leads to across-the-board improvements in text-image alignment -- such that Imagen Editor is preferred over DALL-E 2 and Stable Diffusion -- and, as a cohort, these models are better at object-rendering than text-rendering, and handle material/color/size attributes better than count/shape attributes.