 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMO Sampler: Enhancing Text Rendering with Overshooting
Nov 28, 2024



Achieving precise alignment between textual instructions and generated images in text-to-image generation is a significant challenge, particularly in rendering written text within images. Sate-of-the-art models like Stable Diffusion 3 (SD3), Flux, and AuraFlow still struggle with accurate text depiction, resulting in misspelled or inconsistent text. We introduce a training-free method with minimal computational overhead that significantly enhances text rendering quality. Specifically, we introduce an overshooting sampler for pretrained rectified flow (RF) models, by alternating between over-simulating the learned ordinary differential equation (ODE) and reintroducing noise. Compared to the Euler sampler, the overshooting sampler effectively introduces an extra Langevin dynamics term that can help correct the compounding error from successive Euler steps and therefore improve the text rendering. However, when the overshooting strength is high, we observe over-smoothing artifacts on the generated images. To address this issue, we propose an Attention Modulated Overshooting sampler (AMO), which adaptively controls the strength of overshooting for each image patch according to their attention score with the text content. AMO demonstrates a 32.3% and 35.9% improvement in text rendering accuracy on SD3 and Flux without compromising overall image quality or increasing inference cost.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
May 27, 2024



We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {\it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {\it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
Inflation with Diffusion: Efficient Temporal Adaptation for Text-to-Video Super-Resolution
Jan 18, 2024



We propose an efficient diffusion-based text-to-video super-resolution (SR) tuning approach that leverages the readily learned capacity of pixel level image diffusion model to capture spatial information for video generation. To accomplish this goal, we design an efficient architecture by inflating the weightings of the text-to-image SR model into our video generation framework. Additionally, we incorporate a temporal adapter to ensure temporal coherence across video frames. We investigate different tuning approaches based on our inflated architecture and report trade-offs between computational costs and super-resolution quality. Empirical evaluation, both quantitative and qualitative, on the Shutterstock video dataset, demonstrates that our approach is able to perform text-to-video SR generation with good visual quality and temporal consistency. To evaluate temporal coherence, we also present visualizations in video format in https://drive.google.com/drive/folders/1YVc-KMSJqOrEUdQWVaI-Yfu8Vsfu_1aO?usp=sharing .
Prompting through Prototype: A Prototype-based Prompt Learning on Pretrained Vision-Language Models
Oct 19, 2022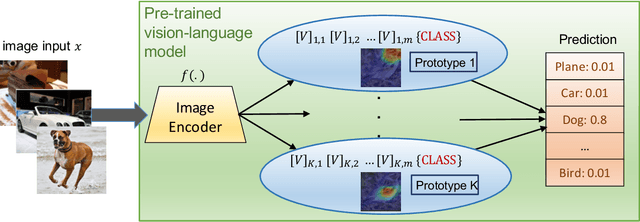


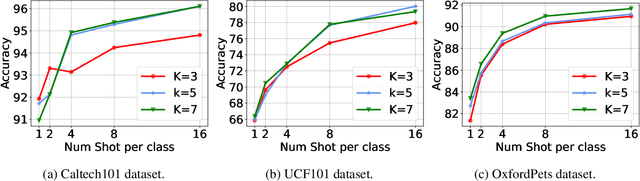
Prompt learning is a new learning paradigm which reformulates downstream tasks as similar pretraining tasks on pretrained models by leveraging textual prompts. Recent works have demonstrated that prompt learning is particularly useful for few-shot learning, where there is limited training data. Depending on the granularity of prompts, those methods can be roughly divided into task-level prompting and instance-level prompting. Task-level prompting methods learn one universal prompt for all input samples, which is efficient but ineffective to capture subtle differences among different classes. Instance-level prompting methods learn a specific prompt for each input, though effective but inefficient. In this work, we develop a novel prototype-based prompt learning method to overcome the above limitations. In particular, we focus on few-shot image recognition tasks on pretrained vision-language models (PVLMs) and develop a method of prompting through prototype (PTP), where we define $K$ image prototypes and $K$ prompt prototypes. In PTP, the image prototype represents a centroid of a certain image cluster in the latent space and a prompt prototype is defined as a soft prompt in the continuous space. The similarity between a query image and an image prototype determines how much this prediction relies on the corresponding prompt prototype. Hence, in PTP, similar images will utilize similar prompting ways. Through extensive experiments on seven real-world benchmarks, we show that PTP is an effective method to leverage the latent knowledge and adaptive to various PVLMs. Moreover, through detailed analysis, we discuss pros and cons for prompt learning and parameter-efficient fine-tuning under the context of few-shot learning.
Denoising Enhanced Distantly Supervised Ultrafine Entity Typing
Oct 18, 2022
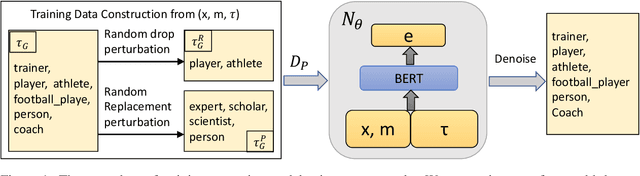
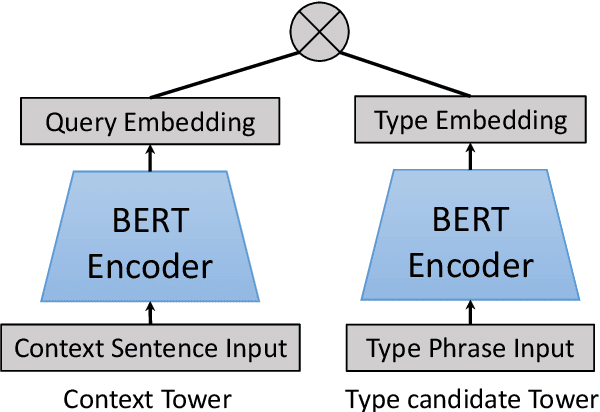
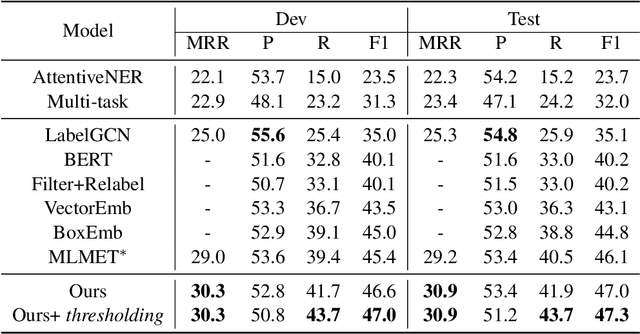
Recently, the task of distantly supervised (DS) ultra-fine entity typing has received significant attention. However, DS data is noisy and often suffers from missing or wrong labeling issues resulting in low precision and low recall. This paper proposes a novel ultra-fine entity typing model with denoising capability. Specifically, we build a noise model to estimate the unknown labeling noise distribution over input contexts and noisy type labels. With the noise model, more trustworthy labels can be recovered by subtracting the estimated noise from the input. Furthermore, we propose an entity typing model, which adopts a bi-encoder architecture, is trained on the denoised data. Finally, the noise model and entity typing model are trained iteratively to enhance each other. We conduct extensive experiments on the Ultra-Fine entity typing dataset as well as OntoNotes dataset and demonstrate that our approach significantly outperforms other baseline methods.
Decomposing User-APP Graph into Subgraphs for Effective APP and User Embedding Learning
Oct 13, 2022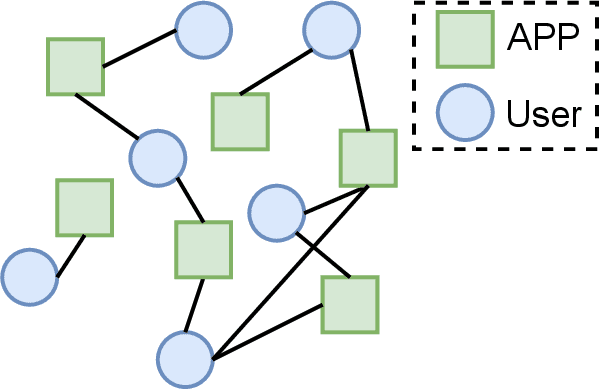
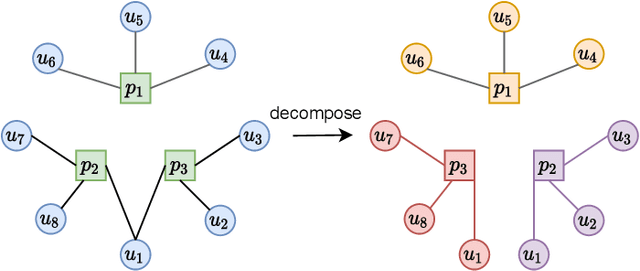
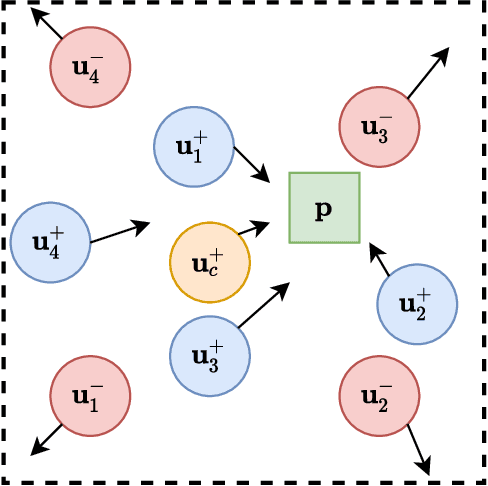
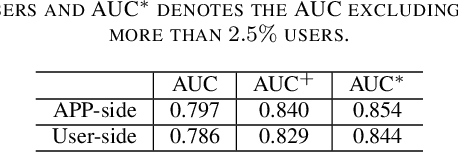
APP-installation information is helpful to describe the user's characteristics. The users with similar APPs installed might share several common interests and behave similarly in some scenarios. In this work, we learn a user embedding vector based on each user's APP-installation information. Since the user APP-installation embedding is learnable without dependency on the historical intra-APP behavioral data of the user, it complements the intra-APP embedding learned within each specific APP. Thus, they considerably help improve the effectiveness of the personalized advertising in each APP, and they are particularly beneficial for the cold start of the new users in the APP. In this paper, we formulate the APP-installation user embedding learning into a bipartite graph embedding problem. The main challenge in learning an effective APP-installation user embedding is the imbalanced data distribution. In this case, graph learning tends to be dominated by the popular APPs, which billions of users have installed. In other words, some niche/specialized APPs might have a marginal influence on graph learning. To effectively exploit the valuable information from the niche APPs, we decompose the APP-installation graph into a set of subgraphs. Each subgraph contains only one APP node and the users who install the APP. For each mini-batch, we only sample the users from the same subgraph in the training process. Thus, each APP can be involved in the training process in a more balanced manner. After integrating the learned APP-installation user embedding into our online personal advertising platform, we obtained a considerable boost in CTR, CVR, and revenue.
Boost CTR Prediction for New Advertisements via Modeling Visual Content
Sep 23, 2022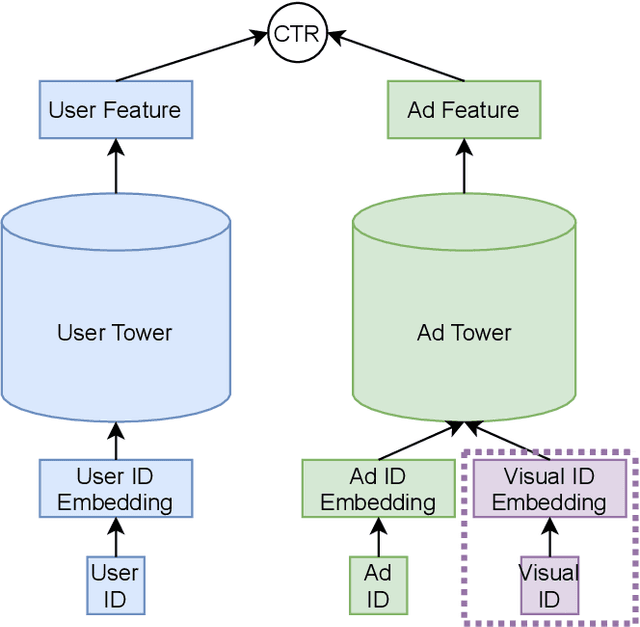
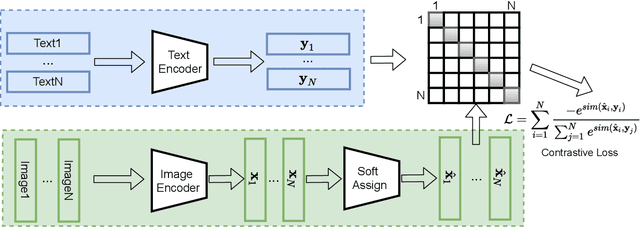
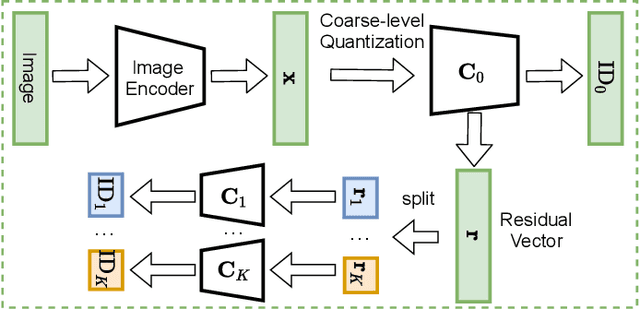
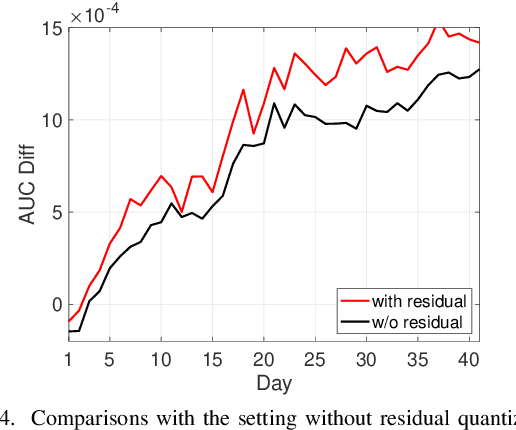
Existing advertisements click-through rate (CTR) prediction models are mainly dependent on behavior ID features, which are learned based on the historical user-ad interactions. Nevertheless, behavior ID features relying on historical user behaviors are not feasible to describe new ads without previous interactions with users. To overcome the limitations of behavior ID features in modeling new ads, we exploit the visual content in ads to boost the performance of CTR prediction models. Specifically, we map each ad into a set of visual IDs based on its visual content. These visual IDs are further used for generating the visual embedding for enhancing CTR prediction models. We formulate the learning of visual IDs into a supervised quantization problem. Due to a lack of class labels for commercial images in advertisements, we exploit image textual descriptions as the supervision to optimize the image extractor for generating effective visual IDs. Meanwhile, since the hard quantization is non-differentiable, we soften the quantization operation to make it support the end-to-end network training. After mapping each image into visual IDs, we learn the embedding for each visual ID based on the historical user-ad interactions accumulated in the past. Since the visual ID embedding depends only on the visual content, it generalizes well to new ads. Meanwhile, the visual ID embedding complements the ad behavior ID embedding. Thus, it can considerably boost the performance of the CTR prediction models previously relying on behavior ID features for both new ads and ads that have accumulated rich user behaviors. After incorporating the visual ID embedding in the CTR prediction model of Baidu online advertising, the average CTR of ads improves by 1.46%, and the total charge increases by 1.10%.
Tree-based Text-Vision BERT for Video Search in Baidu Video Advertising
Sep 19, 2022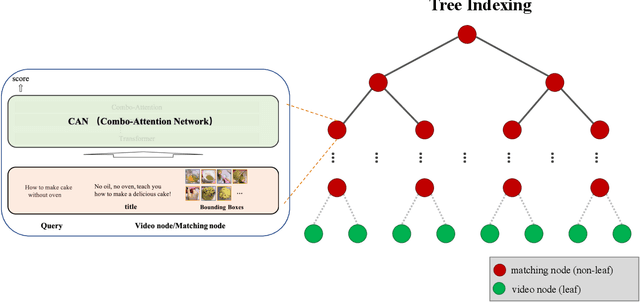
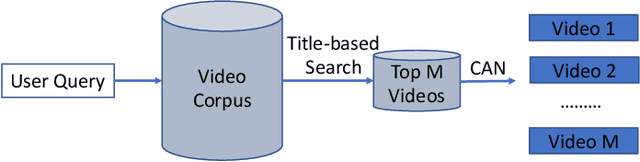
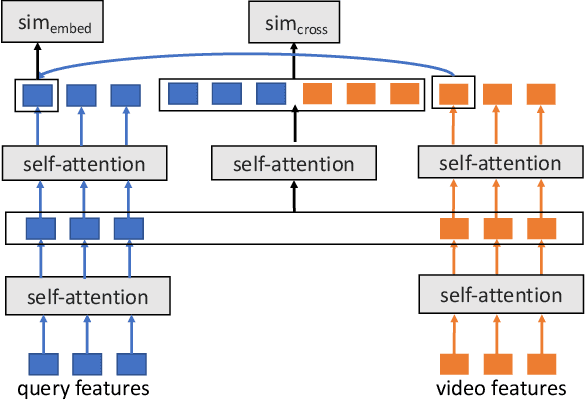

The advancement of the communication technology and the popularity of the smart phones foster the booming of video ads. Baidu, as one of the leading search engine companies in the world, receives billions of search queries per day. How to pair the video ads with the user search is the core task of Baidu video advertising. Due to the modality gap, the query-to-video retrieval is much more challenging than traditional query-to-document retrieval and image-to-image search. Traditionally, the query-to-video retrieval is tackled by the query-to-title retrieval, which is not reliable when the quality of tiles are not high. With the rapid progress achieved in computer vision and natural language processing in recent years, content-based search methods becomes promising for the query-to-video retrieval. Benefited from pretraining on large-scale datasets, some visionBERT methods based on cross-modal attention have achieved excellent performance in many vision-language tasks not only in academia but also in industry. Nevertheless, the expensive computation cost of cross-modal attention makes it impractical for large-scale search in industrial applications. In this work, we present a tree-based combo-attention network (TCAN) which has been recently launched in Baidu's dynamic video advertising platform. It provides a practical solution to deploy the heavy cross-modal attention for the large-scale query-to-video search. After launching tree-based combo-attention network, click-through rate gets improved by 2.29\% and conversion rate get improved by 2.63\%.