 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMO Sampler: Enhancing Text Rendering with Overshooting
Nov 28, 2024



Achieving precise alignment between textual instructions and generated images in text-to-image generation is a significant challenge, particularly in rendering written text within images. Sate-of-the-art models like Stable Diffusion 3 (SD3), Flux, and AuraFlow still struggle with accurate text depiction, resulting in misspelled or inconsistent text. We introduce a training-free method with minimal computational overhead that significantly enhances text rendering quality. Specifically, we introduce an overshooting sampler for pretrained rectified flow (RF) models, by alternating between over-simulating the learned ordinary differential equation (ODE) and reintroducing noise. Compared to the Euler sampler, the overshooting sampler effectively introduces an extra Langevin dynamics term that can help correct the compounding error from successive Euler steps and therefore improve the text rendering. However, when the overshooting strength is high, we observe over-smoothing artifacts on the generated images. To address this issue, we propose an Attention Modulated Overshooting sampler (AMO), which adaptively controls the strength of overshooting for each image patch according to their attention score with the text content. AMO demonstrates a 32.3% and 35.9% improvement in text rendering accuracy on SD3 and Flux without compromising overall image quality or increasing inference cost.
AdaFlow: Imitation Learning with Variance-Adaptive Flow-Based Policies
Feb 06, 2024



Diffusion-based imitation learning improves Behavioral Cloning (BC) on multi-modal decision-making, but comes at the cost of significantly slower inference due to the recursion in the diffusion process. It urges us to design efficient policy generators while keeping the ability to generate diverse actions. To address this challenge, we propose AdaFlow, an imitation learning framework based on flow-based generative modeling. AdaFlow represents the policy with state-conditioned ordinary differential equations (ODEs), which are known as probability flows. We reveal an intriguing connection between the conditional variance of their training loss and the discretization error of the ODEs. With this insight, we propose a variance-adaptive ODE solver that can adjust its step size in the inference stage, making AdaFlow an adaptive decision-maker, offering rapid inference without sacrificing diversity. Interestingly, it automatically reduces to a one-step generator when the action distribution is uni-modal. Our comprehensive empirical evaluation shows that AdaFlow achieves high performance across all dimensions, including success rate, behavioral diversity, and inference speed. The code is available at https://github.com/hxixixh/AdaFlow
Mix and Localize: Localizing Sound Sources in Mixtures
Nov 28, 2022



We present a method for simultaneously localizing multiple sound sources within a visual scene. This task requires a model to both group a sound mixture into individual sources, and to associate them with a visual signal. Our method jointly solves both tasks at once, using a formulation inspired by the contrastive random walk of Jabri et al. We create a graph in which images and separated sounds correspond to nodes, and train a random walker to transition between nodes from different modalities with high return probability. The transition probabilities for this walk are determined by an audio-visual similarity metric that is learned by our model. We show through experiments with musical instruments and human speech that our model can successfully localize multiple sounds, outperforming other self-supervised methods. Project site: https://hxixixh.github.io/mix-and-localize
Structure from Silence: Learning Scene Structure from Ambient Sound
Nov 10, 2021


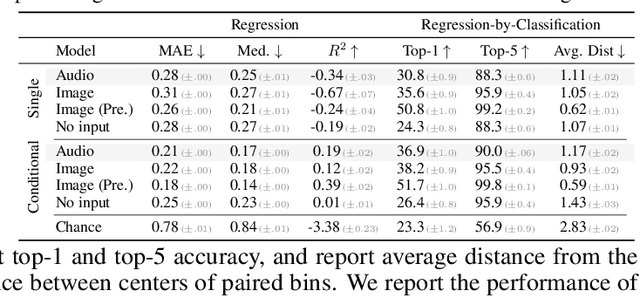
From whirling ceiling fans to ticking clocks, the sounds that we hear subtly vary as we move through a scene. We ask whether these ambient sounds convey information about 3D scene structure and, if so, whether they provide a useful learning signal for multimodal models. To study this, we collect a dataset of paired audio and RGB-D recordings from a variety of quiet indoor scenes. We then train models that estimate the distance to nearby walls, given only audio as input. We also use these recordings to learn multimodal representations through self-supervision, by training a network to associate images with their corresponding sounds. These results suggest that ambient sound conveys a surprising amount of information about scene structure, and that it is a useful signal for learning multimodal features.
A Sparsity Inducing Nuclear-Norm Estimator (SpINNEr) for Matrix-Variate Regression in Brain Connectivity Analysis
Jan 30, 2020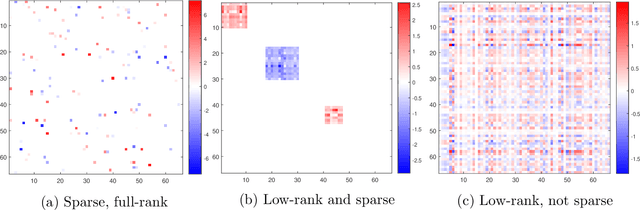
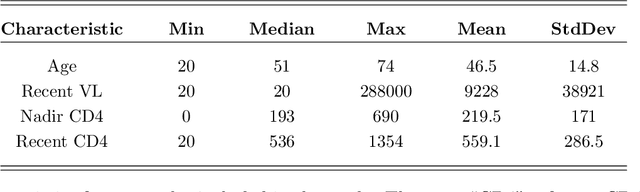

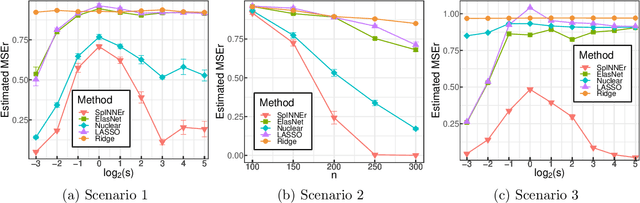
Classical scalar-response regression methods treat covariates as a vector and estimate a corresponding vector of regression coefficients. In medical applications, however, regressors are often in a form of multi-dimensional arrays. For example, one may be interested in using MRI imaging to identify which brain regions are associated with a health outcome. Vectorizing the two-dimensional image arrays is an unsatisfactory approach since it destroys the inherent spatial structure of the images and can be computationally challenging. We present an alternative approach - regularized matrix regression - where the matrix of regression coefficients is defined as a solution to the specific optimization problem. The method, called SParsity Inducing Nuclear Norm EstimatoR (SpINNEr), simultaneously imposes two penalty types on the regression coefficient matrix---the nuclear norm and the lasso norm---to encourage a low rank matrix solution that also has entry-wise sparsity. A specific implementation of the alternating direction method of multipliers (ADMM) is used to build a fast and efficient numerical solver. Our simulations show that SpINNEr outperforms other methods in estimation accuracy when the response-related entries (representing the brain's functional connectivity) are arranged in well-connected communities. SpINNEr is applied to investigate associations between HIV-related outcomes and functional connectivity in the human brain.