 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMO Sampler: Enhancing Text Rendering with Overshooting
Nov 28, 2024



Achieving precise alignment between textual instructions and generated images in text-to-image generation is a significant challenge, particularly in rendering written text within images. Sate-of-the-art models like Stable Diffusion 3 (SD3), Flux, and AuraFlow still struggle with accurate text depiction, resulting in misspelled or inconsistent text. We introduce a training-free method with minimal computational overhead that significantly enhances text rendering quality. Specifically, we introduce an overshooting sampler for pretrained rectified flow (RF) models, by alternating between over-simulating the learned ordinary differential equation (ODE) and reintroducing noise. Compared to the Euler sampler, the overshooting sampler effectively introduces an extra Langevin dynamics term that can help correct the compounding error from successive Euler steps and therefore improve the text rendering. However, when the overshooting strength is high, we observe over-smoothing artifacts on the generated images. To address this issue, we propose an Attention Modulated Overshooting sampler (AMO), which adaptively controls the strength of overshooting for each image patch according to their attention score with the text content. AMO demonstrates a 32.3% and 35.9% improvement in text rendering accuracy on SD3 and Flux without compromising overall image quality or increasing inference cost.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Greedy Growing Enables High-Resolution Pixel-Based Diffusion Models
May 27, 2024



We address the long-standing problem of how to learn effective pixel-based image diffusion models at scale, introducing a remarkably simple greedy growing method for stable training of large-scale, high-resolution models. without the needs for cascaded super-resolution components. The key insight stems from careful pre-training of core components, namely, those responsible for text-to-image alignment {\it vs.} high-resolution rendering. We first demonstrate the benefits of scaling a {\it Shallow UNet}, with no down(up)-sampling enc(dec)oder. Scaling its deep core layers is shown to improve alignment, object structure, and composition. Building on this core model, we propose a greedy algorithm that grows the architecture into high-resolution end-to-end models, while preserving the integrity of the pre-trained representation, stabilizing training, and reducing the need for large high-resolution datasets. This enables a single stage model capable of generating high-resolution images without the need of a super-resolution cascade. Our key results rely on public datasets and show that we are able to train non-cascaded models up to 8B parameters with no further regularization schemes. Vermeer, our full pipeline model trained with internal datasets to produce 1024x1024 images, without cascades, is preferred by 44.0% vs. 21.4% human evaluators over SDXL.
Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward
Apr 02, 2024



Preference modeling techniques, such as direct preference optimization (DPO), has shown effective in enhancing the generalization abilities of large language model (LLM). However, in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge. Previous studies have explored using large large multimodal models (LMMs) as reward models to guide preference modeling, but their ability to accurately assess the factuality of generated responses compared to corresponding videos has not been conclusively established. This paper introduces a novel framework that utilizes detailed video captions as a proxy of video content, enabling language models to incorporate this information as supporting evidence for scoring video Question Answering (QA) predictions. Our approach demonstrates robust alignment with OpenAI GPT-4V model's reward mechanism, which directly takes video frames as input. Furthermore, we show that applying this tailored reward through DPO significantly improves the performance of video LMMs on video QA tasks.
Inflation with Diffusion: Efficient Temporal Adaptation for Text-to-Video Super-Resolution
Jan 18, 2024We propose an efficient diffusion-based text-to-video super-resolution (SR) tuning approach that leverages the readily learned capacity of pixel level image diffusion model to capture spatial information for video generation. To accomplish this goal, we design an efficient architecture by inflating the weightings of the text-to-image SR model into our video generation framework. Additionally, we incorporate a temporal adapter to ensure temporal coherence across video frames. We investigate different tuning approaches based on our inflated architecture and report trade-offs between computational costs and super-resolution quality. Empirical evaluation, both quantitative and qualitative, on the Shutterstock video dataset, demonstrates that our approach is able to perform text-to-video SR generation with good visual quality and temporal consistency. To evaluate temporal coherence, we also present visualizations in video format in https://drive.google.com/drive/folders/1YVc-KMSJqOrEUdQWVaI-Yfu8Vsfu_1aO?usp=sharing .
Dataset Bias Mitigation in Multiple-Choice Visual Question Answering and Beyond
Oct 31, 2023Vision-language (VL) understanding tasks evaluate models' comprehension of complex visual scenes through multiple-choice questions. However, we have identified two dataset biases that models can exploit as shortcuts to resolve various VL tasks correctly without proper understanding. The first type of dataset bias is \emph{Unbalanced Matching} bias, where the correct answer overlaps the question and image more than the incorrect answers. The second type of dataset bias is \emph{Distractor Similarity} bias, where incorrect answers are overly dissimilar to the correct answer but significantly similar to other incorrect answers within the same sample. To address these dataset biases, we first propose Adversarial Data Synthesis (ADS) to generate synthetic training and debiased evaluation data. We then introduce Intra-sample Counterfactual Training (ICT) to assist models in utilizing the synthesized training data, particularly the counterfactual data, via focusing on intra-sample differentiation. Extensive experiments demonstrate the effectiveness of ADS and ICT in consistently improving model performance across different benchmarks, even in domain-shifted scenarios.
* EMNLP 2023
Unsupervised Out-of-Domain Detection via Pre-trained Transformers
Jun 02, 2021



Deployed real-world machine learning applications are often subject to uncontrolled and even potentially malicious inputs. Those out-of-domain inputs can lead to unpredictable outputs and sometimes catastrophic safety issues. Prior studies on out-of-domain detection require in-domain task labels and are limited to supervised classification scenarios. Our work tackles the problem of detecting out-of-domain samples with only unsupervised in-domain data. We utilize the latent representations of pre-trained transformers and propose a simple yet effective method to transform features across all layers to construct out-of-domain detectors efficiently. Two domain-specific fine-tuning approaches are further proposed to boost detection accuracy. Our empirical evaluations of related methods on two datasets validate that our method greatly improves out-of-domain detection ability in a more general scenario.
A Heterogeneous Graphical Model to Understand User-Level Sentiments in Social Media
Dec 17, 2019
Social Media has seen a tremendous growth in the last decade and is continuing to grow at a rapid pace. With such adoption, it is increasingly becoming a rich source of data for opinion mining and sentiment analysis. The detection and analysis of sentiment in social media is thus a valuable topic and attracts a lot of research efforts. Most of the earlier efforts focus on supervised learning approaches to solve this problem, which require expensive human annotations and therefore limits their practical use. In our work, we propose a semi-supervised approach to predict user-level sentiments for specific topics. We define and utilize a heterogeneous graph built from the social networks of the users with the knowledge that connected users in social networks typically share similar sentiments. Compared with the previous works, we have several novelties: (1) we incorporate the influences/authoritativeness of the users into the model, 2) we include comment-based and like-based user-user links to the graph, 3) we superimpose multiple heterogeneous graphs into one thereby allowing multiple types of links to exist between two users.
Unsupervised Pseudo-Labeling for Extractive Summarization on Electronic Health Records
Nov 26, 2018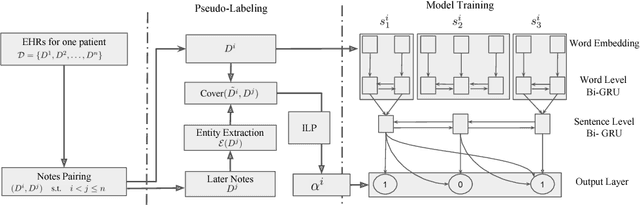

Extractive summarization is very useful for physicians to better manage and digest Electronic Health Records (EHRs). However, the training of a supervised model requires disease-specific medical background and is thus very expensive. We studied how to utilize the intrinsic correlation between multiple EHRs to generate pseudo-labels and train a supervised model with no external annotation. Experiments on real-patient data validate that our model is effective in summarizing crucial disease-specific information for patients.
Multimodal Machine Learning for Automated ICD Coding
Oct 31, 2018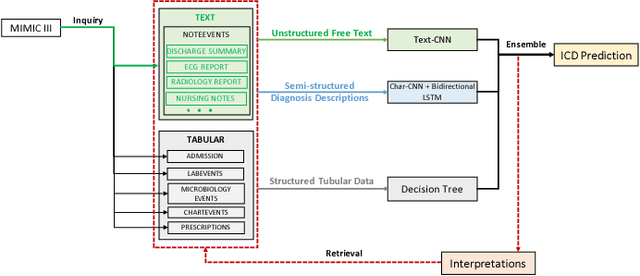
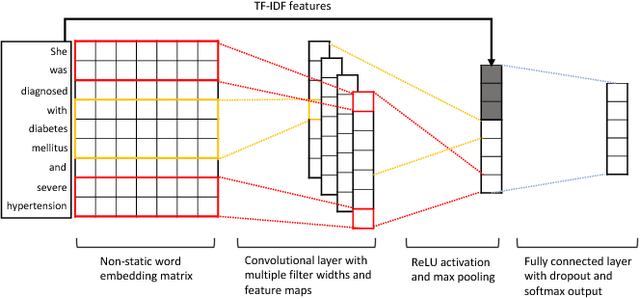

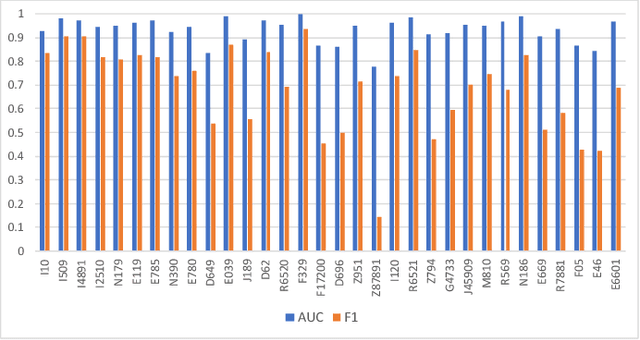
This study presents a multimodal machine learning model to predict ICD-10 diagnostic codes. We developed separate machine learning models that can handle data from different modalities, including unstructured text, semi-structured text and structured tabular data. We further employed an ensemble method to integrate all modality-specific models to generate ICD-10 codes. Key evidence was also extracted to make our prediction more convincing and explainable. We used the Medical Information Mart for Intensive Care III (MIMIC -III) dataset to validate our approach. For ICD code prediction, our best-performing model (micro-F1 = 0.7633, micro-AUC = 0.9541) significantly outperforms other baseline models including TF-IDF (micro-F1 = 0.6721, micro-AUC = 0.7879) and Text-CNN model (micro-F1 = 0.6569, micro-AUC = 0.9235). For interpretability, our approach achieves a Jaccard Similarity Coefficient (JSC) of 0.1806 on text data and 0.3105 on tabular data, where well-trained physicians achieve 0.2780 and 0.5002 respectively.