 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Machine Learning for Automated ICD Coding
Paper and Code
Oct 31, 2018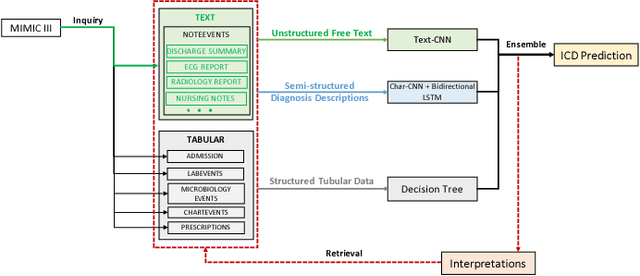
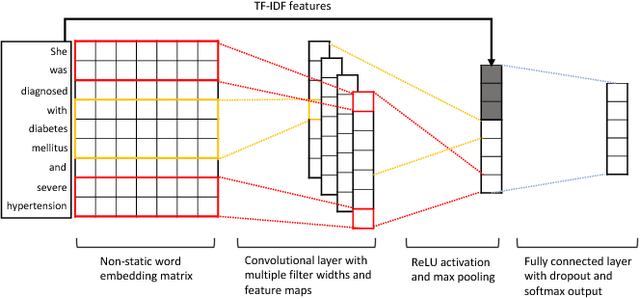

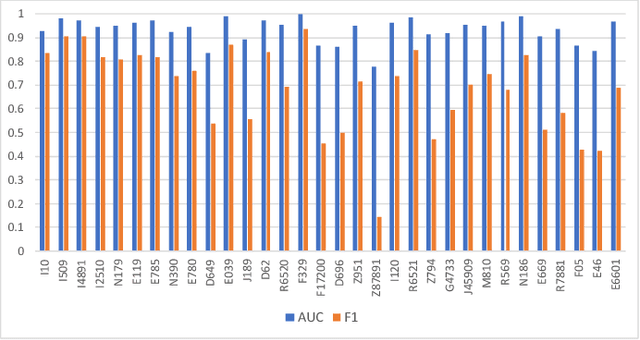
This study presents a multimodal machine learning model to predict ICD-10 diagnostic codes. We developed separate machine learning models that can handle data from different modalities, including unstructured text, semi-structured text and structured tabular data. We further employed an ensemble method to integrate all modality-specific models to generate ICD-10 codes. Key evidence was also extracted to make our prediction more convincing and explainable. We used the Medical Information Mart for Intensive Care III (MIMIC -III) dataset to validate our approach. For ICD code prediction, our best-performing model (micro-F1 = 0.7633, micro-AUC = 0.9541) significantly outperforms other baseline models including TF-IDF (micro-F1 = 0.6721, micro-AUC = 0.7879) and Text-CNN model (micro-F1 = 0.6569, micro-AUC = 0.9235). For interpretability, our approach achieves a Jaccard Similarity Coefficient (JSC) of 0.1806 on text data and 0.3105 on tabular data, where well-trained physicians achieve 0.2780 and 0.5002 respectively.