 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeciphering GunType Hierarchy through Acoustic Analysis of Gunshot Recordings
Jun 25, 2025The escalating rates of gun-related violence and mass shootings represent a significant threat to public safety. Timely and accurate information for law enforcement agencies is crucial in mitigating these incidents. Current commercial gunshot detection systems, while effective, often come with prohibitive costs. This research explores a cost-effective alternative by leveraging acoustic analysis of gunshot recordings, potentially obtainable from ubiquitous devices like cell phones, to not only detect gunshots but also classify the type of firearm used. This paper details a study on deciphering gun type hierarchies using a curated dataset of 3459 recordings. We investigate the fundamental acoustic characteristics of gunshots, including muzzle blasts and shockwaves, which vary based on firearm type, ammunition, and shooting direction. We propose and evaluate machine learning frameworks, including Support Vector Machines (SVMs) as a baseline and a more advanced Convolutional Neural Network (CNN) architecture for joint gunshot detection and gun type classification. Results indicate that our deep learning approach achieves a mean average precision (mAP) of 0.58 on clean labeled data, outperforming the SVM baseline (mAP 0.39). Challenges related to data quality, environmental noise, and the generalization capabilities when using noisy web-sourced data (mAP 0.35) are also discussed. The long-term vision is to develop a highly accurate, real-time system deployable on common recording devices, significantly reducing detection costs and providing critical intelligence to first responders.
Emphasizing Discriminative Features for Dataset Distillation in Complex Scenarios
Oct 22, 2024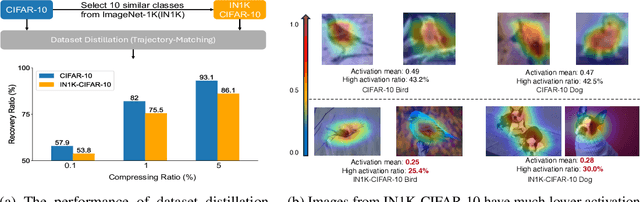
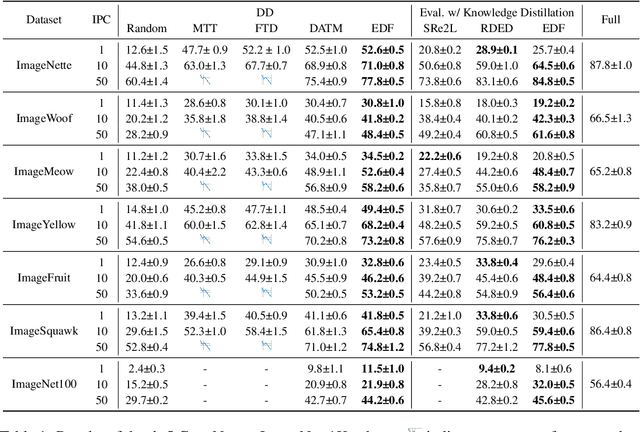
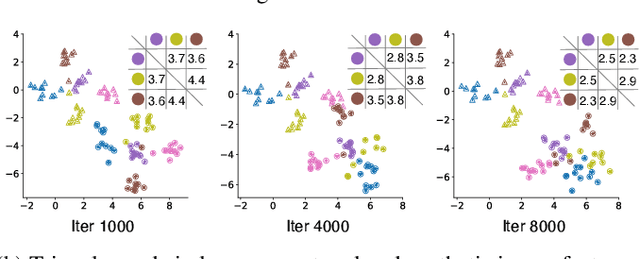

Dataset distillation has demonstrated strong performance on simple datasets like CIFAR, MNIST, and TinyImageNet but struggles to achieve similar results in more complex scenarios. In this paper, we propose EDF (emphasizes the discriminative features), a dataset distillation method that enhances key discriminative regions in synthetic images using Grad-CAM activation maps. Our approach is inspired by a key observation: in simple datasets, high-activation areas typically occupy most of the image, whereas in complex scenarios, the size of these areas is much smaller. Unlike previous methods that treat all pixels equally when synthesizing images, EDF uses Grad-CAM activation maps to enhance high-activation areas. From a supervision perspective, we downplay supervision signals that have lower losses, as they contain common patterns. Additionally, to help the DD community better explore complex scenarios, we build the Complex Dataset Distillation (Comp-DD) benchmark by meticulously selecting sixteen subsets, eight easy and eight hard, from ImageNet-1K. In particular, EDF consistently outperforms SOTA results in complex scenarios, such as ImageNet-1K subsets. Hopefully, more researchers will be inspired and encouraged to improve the practicality and efficacy of DD. Our code and benchmark will be made public at https://github.com/NUS-HPC-AI-Lab/EDF.
Combo: Co-speech holistic 3D human motion generation and efficient customizable adaptation in harmony
Aug 18, 2024



In this paper, we propose a novel framework, Combo, for harmonious co-speech holistic 3D human motion generation and efficient customizable adaption. In particular, we identify that one fundamental challenge as the multiple-input-multiple-output (MIMO) nature of the generative model of interest. More concretely, on the input end, the model typically consumes both speech signals and character guidance (e.g., identity and emotion), which not only poses challenge on learning capacity but also hinders further adaptation to varying guidance; on the output end, holistic human motions mainly consist of facial expressions and body movements, which are inherently correlated but non-trivial to coordinate in current data-driven generation process. In response to the above challenge, we propose tailored designs to both ends. For the former, we propose to pre-train on data regarding a fixed identity with neutral emotion, and defer the incorporation of customizable conditions (identity and emotion) to fine-tuning stage, which is boosted by our novel X-Adapter for parameter-efficient fine-tuning. For the latter, we propose a simple yet effective transformer design, DU-Trans, which first divides into two branches to learn individual features of face expression and body movements, and then unites those to learn a joint bi-directional distribution and directly predicts combined coefficients. Evaluated on BEAT2 and SHOW datasets, Combo is highly effective in generating high-quality motions but also efficient in transferring identity and emotion. Project website: \href{https://xc-csc101.github.io/combo/}{Combo}.
SHIELD: LLM-Driven Schema Induction for Predictive Analytics in EV Battery Supply Chain Disruptions
Aug 09, 2024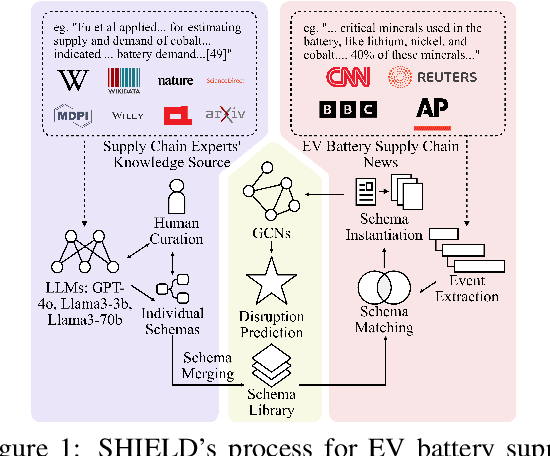

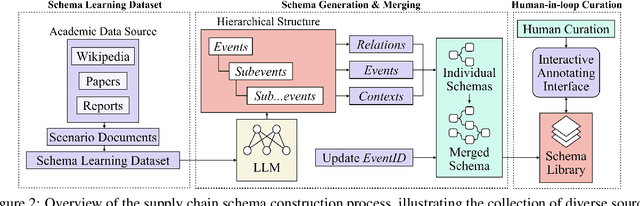
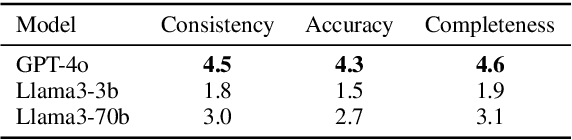
The electric vehicle (EV) battery supply chain's vulnerability to disruptions necessitates advanced predictive analytics. We present SHIELD (Schema-based Hierarchical Induction for EV supply chain Disruption), a system integrating Large Language Models (LLMs) with domain expertise for EV battery supply chain risk assessment. SHIELD combines: (1) LLM-driven schema learning to construct a comprehensive knowledge library, (2) a disruption analysis system utilizing fine-tuned language models for event extraction, multi-dimensional similarity matching for schema matching, and Graph Convolutional Networks (GCNs) with logical constraints for prediction, and (3) an interactive interface for visualizing results and incorporating expert feedback to enhance decision-making. Evaluated on 12,070 paragraphs from 365 sources (2022-2023), SHIELD outperforms baseline GCNs and LLM+prompt methods (e.g., GPT-4o) in disruption prediction. These results demonstrate SHIELD's effectiveness in combining LLM capabilities with domain expertise for enhanced supply chain risk assessment.
Open-Vocabulary 3D Semantic Segmentation with Text-to-Image Diffusion Models
Jul 18, 2024



In this paper, we investigate the use of diffusion models which are pre-trained on large-scale image-caption pairs for open-vocabulary 3D semantic understanding. We propose a novel method, namely Diff2Scene, which leverages frozen representations from text-image generative models, along with salient-aware and geometric-aware masks, for open-vocabulary 3D semantic segmentation and visual grounding tasks. Diff2Scene gets rid of any labeled 3D data and effectively identifies objects, appearances, materials, locations and their compositions in 3D scenes. We show that it outperforms competitive baselines and achieves significant improvements over state-of-the-art methods. In particular, Diff2Scene improves the state-of-the-art method on ScanNet200 by 12%.
Multimodal Reranking for Knowledge-Intensive Visual Question Answering
Jul 17, 2024



Knowledge-intensive visual question answering requires models to effectively use external knowledge to help answer visual questions. A typical pipeline includes a knowledge retriever and an answer generator. However, a retriever that utilizes local information, such as an image patch, may not provide reliable question-candidate relevance scores. Besides, the two-tower architecture also limits the relevance score modeling of a retriever to select top candidates for answer generator reasoning. In this paper, we introduce an additional module, a multi-modal reranker, to improve the ranking quality of knowledge candidates for answer generation. Our reranking module takes multi-modal information from both candidates and questions and performs cross-item interaction for better relevance score modeling. Experiments on OK-VQA and A-OKVQA show that multi-modal reranker from distant supervision provides consistent improvements. We also find a training-testing discrepancy with reranking in answer generation, where performance improves if training knowledge candidates are similar to or noisier than those used in testing.
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Jun 17, 2024

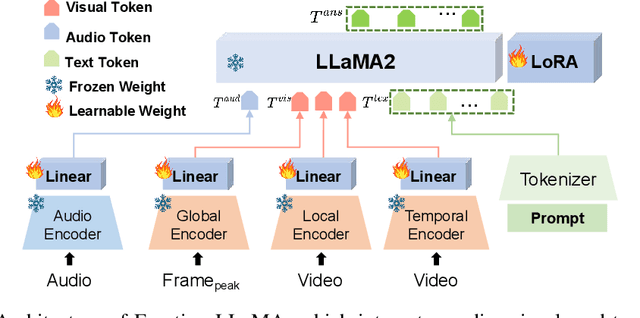

Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
Learning Visual-Semantic Subspace Representations for Propositional Reasoning
May 25, 2024



Learning representations that capture rich semantic relationships and accommodate propositional calculus poses a significant challenge. Existing approaches are either contrastive, lacking theoretical guarantees, or fall short in effectively representing the partial orders inherent to rich visual-semantic hierarchies. In this paper, we propose a novel approach for learning visual representations that not only conform to a specified semantic structure but also facilitate probabilistic propositional reasoning. Our approach is based on a new nuclear norm-based loss. We show that its minimum encodes the spectral geometry of the semantics in a subspace lattice, where logical propositions can be represented by projection operators.
Direct Preference Optimization of Video Large Multimodal Models from Language Model Reward
Apr 02, 2024



Preference modeling techniques, such as direct preference optimization (DPO), has shown effective in enhancing the generalization abilities of large language model (LLM). However, in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge. Previous studies have explored using large large multimodal models (LMMs) as reward models to guide preference modeling, but their ability to accurately assess the factuality of generated responses compared to corresponding videos has not been conclusively established. This paper introduces a novel framework that utilizes detailed video captions as a proxy of video content, enabling language models to incorporate this information as supporting evidence for scoring video Question Answering (QA) predictions. Our approach demonstrates robust alignment with OpenAI GPT-4V model's reward mechanism, which directly takes video frames as input. Furthermore, we show that applying this tailored reward through DPO significantly improves the performance of video LMMs on video QA tasks.
Hyperbolic vs Euclidean Embeddings in Few-Shot Learning: Two Sides of the Same Coin
Sep 18, 2023
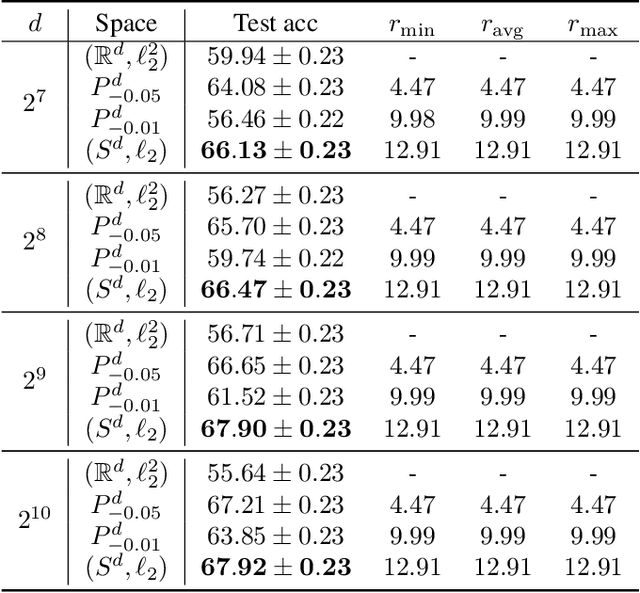

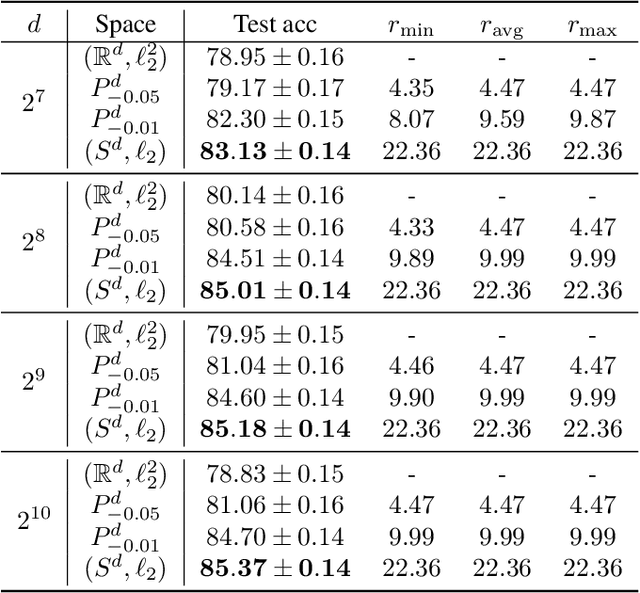
Recent research in representation learning has shown that hierarchical data lends itself to low-dimensional and highly informative representations in hyperbolic space. However, even if hyperbolic embeddings have gathered attention in image recognition, their optimization is prone to numerical hurdles. Further, it remains unclear which applications stand to benefit the most from the implicit bias imposed by hyperbolicity, when compared to traditional Euclidean features. In this paper, we focus on prototypical hyperbolic neural networks. In particular, the tendency of hyperbolic embeddings to converge to the boundary of the Poincar\'e ball in high dimensions and the effect this has on few-shot classification. We show that the best few-shot results are attained for hyperbolic embeddings at a common hyperbolic radius. In contrast to prior benchmark results, we demonstrate that better performance can be achieved by a fixed-radius encoder equipped with the Euclidean metric, regardless of the embedding dimension.