 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-LLaMAv2 and MMEVerse: A New Framework and Benchmark for Multimodal Emotion Understanding
Jan 23, 2026Understanding human emotions from multimodal signals poses a significant challenge in affective computing and human-robot interaction. While multimodal large language models (MLLMs) have excelled in general vision-language tasks, their capabilities in emotional reasoning remain limited. The field currently suffers from a scarcity of large-scale datasets with high-quality, descriptive emotion annotations and lacks standardized benchmarks for evaluation. Our preliminary framework, Emotion-LLaMA, pioneered instruction-tuned multimodal learning for emotion reasoning but was restricted by explicit face detectors, implicit fusion strategies, and low-quality training data with limited scale. To address these limitations, we present Emotion-LLaMAv2 and the MMEVerse benchmark, establishing an end-to-end pipeline together with a standardized evaluation setting for emotion recognition and reasoning. Emotion-LLaMAv2 introduces three key advances. First, an end-to-end multiview encoder eliminates external face detection and captures nuanced emotional cues via richer spatial and temporal multiview tokens. Second, a Conv Attention pre-fusion module is designed to enable simultaneous local and global multimodal feature interactions external to the LLM backbone. Third, a perception-to-cognition curriculum instruction tuning scheme within the LLaMA2 backbone unifies emotion recognition and free-form emotion reasoning. To support large-scale training and reproducible evaluation, MMEVerse aggregates twelve publicly available emotion datasets, including IEMOCAP, MELD, DFEW, and MAFW, into a unified multimodal instruction format. The data are re-annotated via a multi-agent pipeline involving Qwen2 Audio, Qwen2.5 VL, and GPT 4o, producing 130k training clips and 36k testing clips across 18 evaluation benchmarks.
Emotion-Qwen: Training Hybrid Experts for Unified Emotion and General Vision-Language Understanding
May 10, 2025Emotion understanding in videos aims to accurately recognize and interpret individuals' emotional states by integrating contextual, visual, textual, and auditory cues. While Large Multimodal Models (LMMs) have demonstrated significant progress in general vision-language (VL) tasks, their performance in emotion-specific scenarios remains limited. Moreover, fine-tuning LMMs on emotion-related tasks often leads to catastrophic forgetting, hindering their ability to generalize across diverse tasks. To address these challenges, we present Emotion-Qwen, a tailored multimodal framework designed to enhance both emotion understanding and general VL reasoning. Emotion-Qwen incorporates a sophisticated Hybrid Compressor based on the Mixture of Experts (MoE) paradigm, which dynamically routes inputs to balance emotion-specific and general-purpose processing. The model is pre-trained in a three-stage pipeline on large-scale general and emotional image datasets to support robust multimodal representations. Furthermore, we construct the Video Emotion Reasoning (VER) dataset, comprising more than 40K bilingual video clips with fine-grained descriptive annotations, to further enrich Emotion-Qwen's emotional reasoning capability. Experimental results demonstrate that Emotion-Qwen achieves state-of-the-art performance on multiple emotion recognition benchmarks, while maintaining competitive results on general VL tasks. Code and models are available at https://anonymous.4open.science/r/Emotion-Qwen-Anonymous.
Why We Feel: Breaking Boundaries in Emotional Reasoning with Multimodal Large Language Models
Apr 10, 2025Most existing emotion analysis emphasizes which emotion arises (e.g., happy, sad, angry) but neglects the deeper why. We propose Emotion Interpretation (EI), focusing on causal factors-whether explicit (e.g., observable objects, interpersonal interactions) or implicit (e.g., cultural context, off-screen events)-that drive emotional responses. Unlike traditional emotion recognition, EI tasks require reasoning about triggers instead of mere labeling. To facilitate EI research, we present EIBench, a large-scale benchmark encompassing 1,615 basic EI samples and 50 complex EI samples featuring multifaceted emotions. Each instance demands rationale-based explanations rather than straightforward categorization. We further propose a Coarse-to-Fine Self-Ask (CFSA) annotation pipeline, which guides Vision-Language Models (VLLMs) through iterative question-answer rounds to yield high-quality labels at scale. Extensive evaluations on open-source and proprietary large language models under four experimental settings reveal consistent performance gaps-especially for more intricate scenarios-underscoring EI's potential to enrich empathetic, context-aware AI applications. Our benchmark and methods are publicly available at: https://github.com/Lum1104/EIBench, offering a foundation for advanced multimodal causal analysis and next-generation affective computing.
HA-VLN: A Benchmark for Human-Aware Navigation in Discrete-Continuous Environments with Dynamic Multi-Human Interactions, Real-World Validation, and an Open Leaderboard
Mar 18, 2025
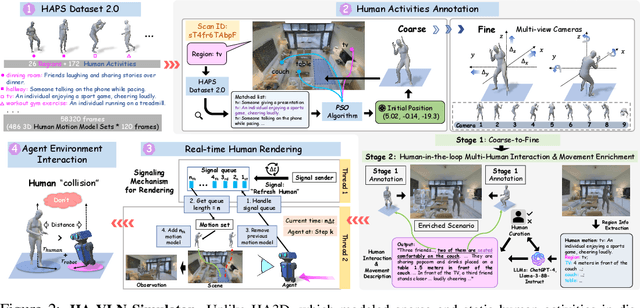
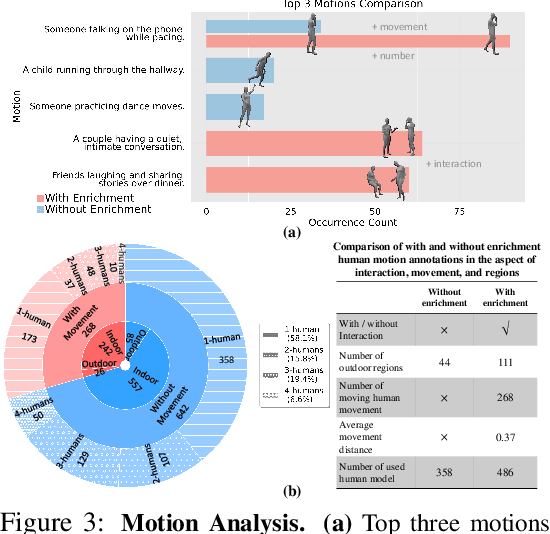

Vision-and-Language Navigation (VLN) systems often focus on either discrete (panoramic) or continuous (free-motion) paradigms alone, overlooking the complexities of human-populated, dynamic environments. We introduce a unified Human-Aware VLN (HA-VLN) benchmark that merges these paradigms under explicit social-awareness constraints. Our contributions include: 1. A standardized task definition that balances discrete-continuous navigation with personal-space requirements; 2. An enhanced human motion dataset (HAPS 2.0) and upgraded simulators capturing realistic multi-human interactions, outdoor contexts, and refined motion-language alignment; 3. Extensive benchmarking on 16,844 human-centric instructions, revealing how multi-human dynamics and partial observability pose substantial challenges for leading VLN agents; 4. Real-world robot tests validating sim-to-real transfer in crowded indoor spaces; and 5. A public leaderboard supporting transparent comparisons across discrete and continuous tasks. Empirical results show improved navigation success and fewer collisions when social context is integrated, underscoring the need for human-centric design. By releasing all datasets, simulators, agent code, and evaluation tools, we aim to advance safer, more capable, and socially responsible VLN research.
Multimodal Multi-turn Conversation Stance Detection: A Challenge Dataset and Effective Model
Sep 01, 2024



Stance detection, which aims to identify public opinion towards specific targets using social media data, is an important yet challenging task. With the proliferation of diverse multimodal social media content including text, and images multimodal stance detection (MSD) has become a crucial research area. However, existing MSD studies have focused on modeling stance within individual text-image pairs, overlooking the multi-party conversational contexts that naturally occur on social media. This limitation stems from a lack of datasets that authentically capture such conversational scenarios, hindering progress in conversational MSD. To address this, we introduce a new multimodal multi-turn conversational stance detection dataset (called MmMtCSD). To derive stances from this challenging dataset, we propose a novel multimodal large language model stance detection framework (MLLM-SD), that learns joint stance representations from textual and visual modalities. Experiments on MmMtCSD show state-of-the-art performance of our proposed MLLM-SD approach for multimodal stance detection. We believe that MmMtCSD will contribute to advancing real-world applications of stance detection research.
SZTU-CMU at MER2024: Improving Emotion-LLaMA with Conv-Attention for Multimodal Emotion Recognition
Aug 21, 2024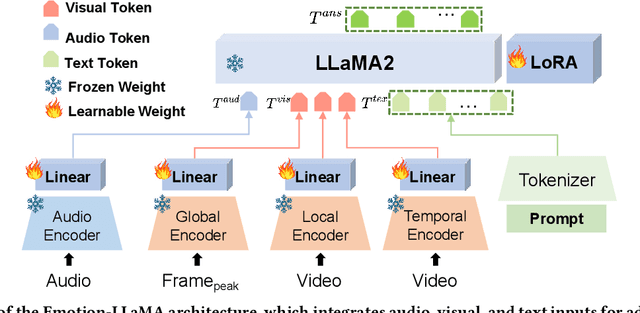



This paper presents our winning approach for the MER-NOISE and MER-OV tracks of the MER2024 Challenge on multimodal emotion recognition. Our system leverages the advanced emotional understanding capabilities of Emotion-LLaMA to generate high-quality annotations for unlabeled samples, addressing the challenge of limited labeled data. To enhance multimodal fusion while mitigating modality-specific noise, we introduce Conv-Attention, a lightweight and efficient hybrid framework. Extensive experimentation vali-dates the effectiveness of our approach. In the MER-NOISE track, our system achieves a state-of-the-art weighted average F-score of 85.30%, surpassing the second and third-place teams by 1.47% and 1.65%, respectively. For the MER-OV track, our utilization of Emotion-LLaMA for open-vocabulary annotation yields an 8.52% improvement in average accuracy and recall compared to GPT-4V, securing the highest score among all participating large multimodal models. The code and model for Emotion-LLaMA are available at https://github.com/ZebangCheng/Emotion-LLaMA.
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Jun 17, 2024

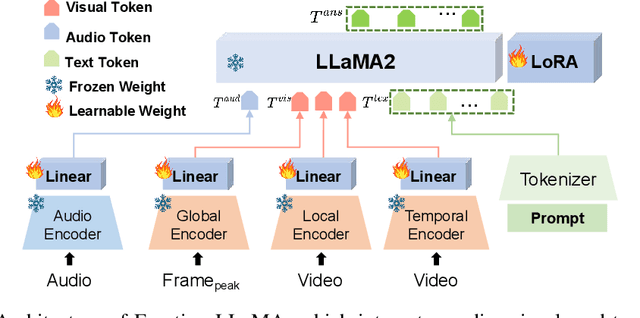

Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
Dataset Growth
May 28, 2024



Deep learning benefits from the growing abundance of available data. Meanwhile, efficiently dealing with the growing data scale has become a challenge. Data publicly available are from different sources with various qualities, and it is impractical to do manual cleaning against noise and redundancy given today's data scale. There are existing techniques for cleaning/selecting the collected data. However, these methods are mainly proposed for offline settings that target one of the cleanness and redundancy problems. In practice, data are growing exponentially with both problems. This leads to repeated data curation with sub-optimal efficiency. To tackle this challenge, we propose InfoGrowth, an efficient online algorithm for data cleaning and selection, resulting in a growing dataset that keeps up to date with awareness of cleanliness and diversity. InfoGrowth can improve data quality/efficiency on both single-modal and multi-modal tasks, with an efficient and scalable design. Its framework makes it practical for real-world data engines.
MIPS at SemEval-2024 Task 3: Multimodal Emotion-Cause Pair Extraction in Conversations with Multimodal Language Models
Apr 11, 2024



This paper presents our winning submission to Subtask 2 of SemEval 2024 Task 3 on multimodal emotion cause analysis in conversations. We propose a novel Multimodal Emotion Recognition and Multimodal Emotion Cause Extraction (MER-MCE) framework that integrates text, audio, and visual modalities using specialized emotion encoders. Our approach sets itself apart from top-performing teams by leveraging modality-specific features for enhanced emotion understanding and causality inference. Experimental evaluation demonstrates the advantages of our multimodal approach, with our submission achieving a competitive weighted F1 score of 0.3435, ranking third with a margin of only 0.0339 behind the 1st team and 0.0025 behind the 2nd team. Project: https://github.com/MIPS-COLT/MER-MCE.git