 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopicVD: A Topic-Based Dataset of Video-Guided Multimodal Machine Translation for Documentaries
May 09, 2025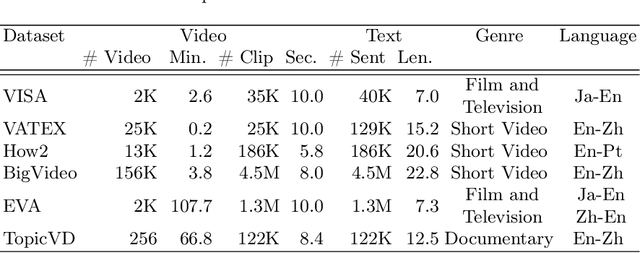
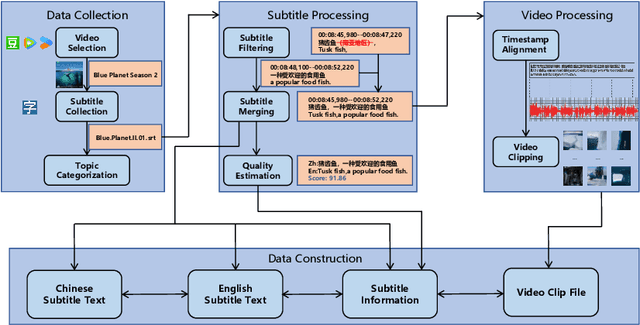
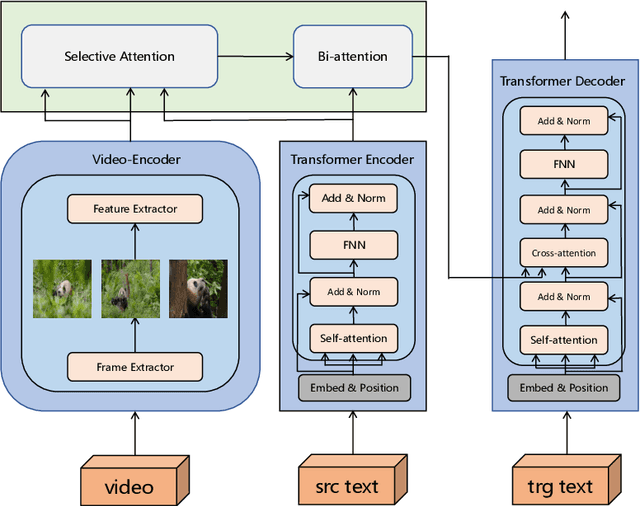
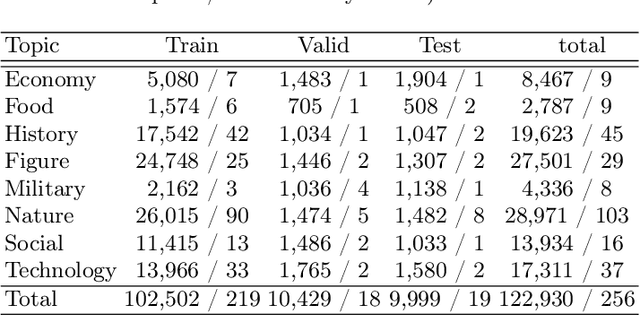
Most existing multimodal machine translation (MMT) datasets are predominantly composed of static images or short video clips, lacking extensive video data across diverse domains and topics. As a result, they fail to meet the demands of real-world MMT tasks, such as documentary translation. In this study, we developed TopicVD, a topic-based dataset for video-supported multimodal machine translation of documentaries, aiming to advance research in this field. We collected video-subtitle pairs from documentaries and categorized them into eight topics, such as economy and nature, to facilitate research on domain adaptation in video-guided MMT. Additionally, we preserved their contextual information to support research on leveraging the global context of documentaries in video-guided MMT. To better capture the shared semantics between text and video, we propose an MMT model based on a cross-modal bidirectional attention module. Extensive experiments on the TopicVD dataset demonstrate that visual information consistently improves the performance of the NMT model in documentary translation. However, the MMT model's performance significantly declines in out-of-domain scenarios, highlighting the need for effective domain adaptation methods. Additionally, experiments demonstrate that global context can effectively improve translation performance. % Dataset and our implementations are available at https://github.com/JinzeLv/TopicVD
C-MTCSD: A Chinese Multi-Turn Conversational Stance Detection Dataset
Apr 14, 2025Stance detection has become an essential tool for analyzing public discussions on social media. Current methods face significant challenges, particularly in Chinese language processing and multi-turn conversational analysis. To address these limitations, we introduce C-MTCSD, the largest Chinese multi-turn conversational stance detection dataset, comprising 24,264 carefully annotated instances from Sina Weibo, which is 4.2 times larger than the only prior Chinese conversational stance detection dataset. Our comprehensive evaluation using both traditional approaches and large language models reveals the complexity of C-MTCSD: even state-of-the-art models achieve only 64.07% F1 score in the challenging zero-shot setting, while performance consistently degrades with increasing conversation depth. Traditional models particularly struggle with implicit stance detection, achieving below 50% F1 score. This work establishes a challenging new benchmark for Chinese stance detection research, highlighting significant opportunities for future improvements.
A General Pseudonymization Framework for Cloud-Based LLMs: Replacing Privacy Information in Controlled Text Generation
Feb 21, 2025An increasing number of companies have begun providing services that leverage cloud-based large language models (LLMs), such as ChatGPT. However, this development raises substantial privacy concerns, as users' prompts are transmitted to and processed by the model providers. Among the various privacy protection methods for LLMs, those implemented during the pre-training and fine-tuning phrases fail to mitigate the privacy risks associated with the remote use of cloud-based LLMs by users. On the other hand, methods applied during the inference phrase are primarily effective in scenarios where the LLM's inference does not rely on privacy-sensitive information. In this paper, we outline the process of remote user interaction with LLMs and, for the first time, propose a detailed definition of a general pseudonymization framework applicable to cloud-based LLMs. The experimental results demonstrate that the proposed framework strikes an optimal balance between privacy protection and utility. The code for our method is available to the public at https://github.com/Mebymeby/Pseudonymization-Framework.
Stain-aware Domain Alignment for Imbalance Blood Cell Classification
Dec 04, 2024



Blood cell identification is critical for hematological analysis as it aids physicians in diagnosing various blood-related diseases. In real-world scenarios, blood cell image datasets often present the issues of domain shift and data imbalance, posing challenges for accurate blood cell identification. To address these issues, we propose a novel blood cell classification method termed SADA via stain-aware domain alignment. The primary objective of this work is to mine domain-invariant features in the presence of domain shifts and data imbalances. To accomplish this objective, we propose a stain-based augmentation approach and a local alignment constraint to learn domain-invariant features. Furthermore, we propose a domain-invariant supervised contrastive learning strategy to capture discriminative features. We decouple the training process into two stages of domain-invariant feature learning and classification training, alleviating the problem of data imbalance. Experiment results on four public blood cell datasets and a private real dataset collected from the Third Affiliated Hospital of Sun Yat-sen University demonstrate that SADA can achieve a new state-of-the-art baseline, which is superior to the existing cutting-edge methods with a big margin. The source code can be available at the URL (\url{https://github.com/AnoK3111/SADA}).
Multi-intent Aware Contrastive Learning for Sequential Recommendation
Sep 13, 2024Intent is a significant latent factor influencing user-item interaction sequences. Prevalent sequence recommendation models that utilize contrastive learning predominantly rely on single-intent representations to direct the training process. However, this paradigm oversimplifies real-world recommendation scenarios, attempting to encapsulate the diversity of intents within the single-intent level representation. SR models considering multi-intent information in their framework are more likely to reflect real-life recommendation scenarios accurately.
Multimodal Multi-turn Conversation Stance Detection: A Challenge Dataset and Effective Model
Sep 01, 2024



Stance detection, which aims to identify public opinion towards specific targets using social media data, is an important yet challenging task. With the proliferation of diverse multimodal social media content including text, and images multimodal stance detection (MSD) has become a crucial research area. However, existing MSD studies have focused on modeling stance within individual text-image pairs, overlooking the multi-party conversational contexts that naturally occur on social media. This limitation stems from a lack of datasets that authentically capture such conversational scenarios, hindering progress in conversational MSD. To address this, we introduce a new multimodal multi-turn conversational stance detection dataset (called MmMtCSD). To derive stances from this challenging dataset, we propose a novel multimodal large language model stance detection framework (MLLM-SD), that learns joint stance representations from textual and visual modalities. Experiments on MmMtCSD show state-of-the-art performance of our proposed MLLM-SD approach for multimodal stance detection. We believe that MmMtCSD will contribute to advancing real-world applications of stance detection research.
DATTA: Towards Diversity Adaptive Test-Time Adaptation in Dynamic Wild World
Aug 15, 2024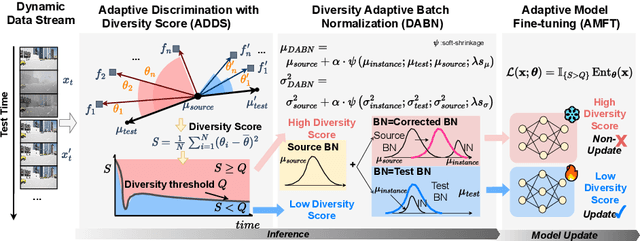
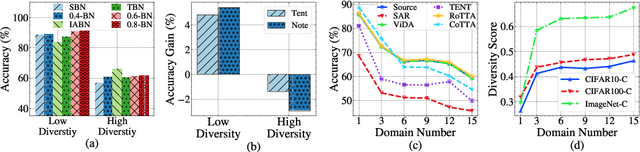
Test-time adaptation (TTA) effectively addresses distribution shifts between training and testing data by adjusting models on test samples, which is crucial for improving model inference in real-world applications. However, traditional TTA methods typically follow a fixed pattern to address the dynamic data patterns (low-diversity or high-diversity patterns) often leading to performance degradation and consequently a decline in Quality of Experience (QoE). The primary issues we observed are:Different scenarios require different normalization methods (e.g., Instance Normalization is optimal in mixed domains but not in static domains). Model fine-tuning can potentially harm the model and waste time.Hence, it is crucial to design strategies for effectively measuring and managing distribution diversity to minimize its negative impact on model performance. Based on these observations, this paper proposes a new general method, named Diversity Adaptive Test-Time Adaptation (DATTA), aimed at improving QoE. DATTA dynamically selects the best batch normalization methods and fine-tuning strategies by leveraging the Diversity Score to differentiate between high and low diversity score batches. It features three key components: Diversity Discrimination (DD) to assess batch diversity, Diversity Adaptive Batch Normalization (DABN) to tailor normalization methods based on DD insights, and Diversity Adaptive Fine-Tuning (DAFT) to selectively fine-tune the model. Experimental results show that our method achieves up to a 21% increase in accuracy compared to state-of-the-art methodologies, indicating that our method maintains good model performance while demonstrating its robustness. Our code will be released soon.
Exploring the Necessity of Visual Modality in Multimodal Machine Translation using Authentic Datasets
Apr 09, 2024



Recent research in the field of multimodal machine translation (MMT) has indicated that the visual modality is either dispensable or offers only marginal advantages. However, most of these conclusions are drawn from the analysis of experimental results based on a limited set of bilingual sentence-image pairs, such as Multi30k. In these kinds of datasets, the content of one bilingual parallel sentence pair must be well represented by a manually annotated image, which is different from the real-world translation scenario. In this work, we adhere to the universal multimodal machine translation framework proposed by Tang et al. (2022). This approach allows us to delve into the impact of the visual modality on translation efficacy by leveraging real-world translation datasets. Through a comprehensive exploration via probing tasks, we find that the visual modality proves advantageous for the majority of authentic translation datasets. Notably, the translation performance primarily hinges on the alignment and coherence between textual and visual contents. Furthermore, our results suggest that visual information serves a supplementary role in multimodal translation and can be substituted.
Investigating Chain-of-thought with ChatGPT for Stance Detection on Social Media
Apr 06, 2023Stance detection predicts attitudes towards targets in texts and has gained attention with the rise of social media. Traditional approaches include conventional machine learning, early deep neural networks, and pre-trained fine-tuning models. However, with the evolution of very large pre-trained language models (VLPLMs) like ChatGPT (GPT-3.5), traditional methods face deployment challenges. The parameter-free Chain-of-Thought (CoT) approach, not requiring backpropagation training, has emerged as a promising alternative. This paper examines CoT's effectiveness in stance detection tasks, demonstrating its superior accuracy and discussing associated challenges.