 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-guided Machine Translation with Global Video Context
Apr 08, 2026Video-guided Multimodal Translation (VMT) has advanced significantly in recent years. However, most existing methods rely on locally aligned video segments paired one-to-one with subtitles, limiting their ability to capture global narrative context across multiple segments in long videos. To overcome this limitation, we propose a globally video-guided multimodal translation framework that leverages a pretrained semantic encoder and vector database-based subtitle retrieval to construct a context set of video segments closely related to the target subtitle semantics. An attention mechanism is employed to focus on highly relevant visual content, while preserving the remaining video features to retain broader contextual information. Furthermore, we design a region-aware cross-modal attention mechanism to enhance semantic alignment during translation. Experiments on a large-scale documentary translation dataset demonstrate that our method significantly outperforms baseline models, highlighting its effectiveness in long-video scenarios.
TopicVD: A Topic-Based Dataset of Video-Guided Multimodal Machine Translation for Documentaries
May 09, 2025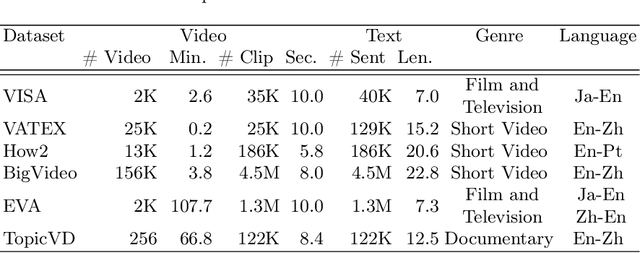
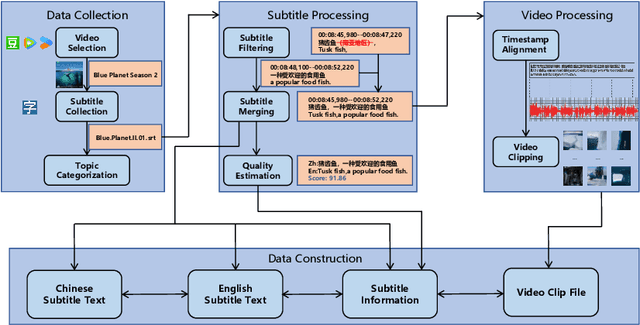
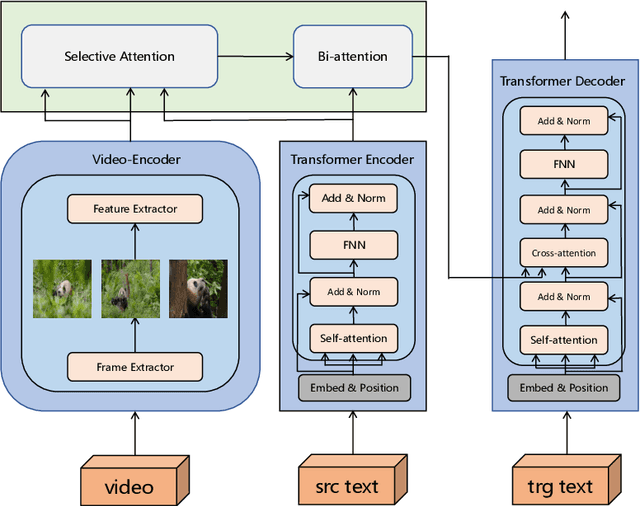
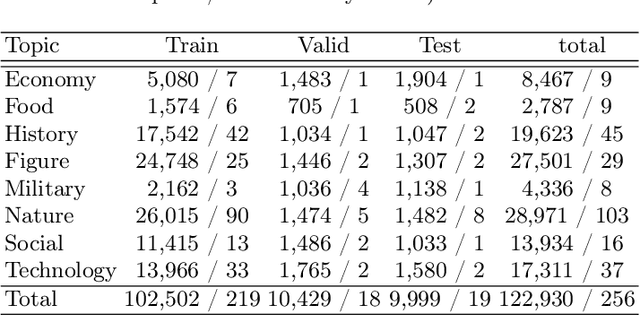
Most existing multimodal machine translation (MMT) datasets are predominantly composed of static images or short video clips, lacking extensive video data across diverse domains and topics. As a result, they fail to meet the demands of real-world MMT tasks, such as documentary translation. In this study, we developed TopicVD, a topic-based dataset for video-supported multimodal machine translation of documentaries, aiming to advance research in this field. We collected video-subtitle pairs from documentaries and categorized them into eight topics, such as economy and nature, to facilitate research on domain adaptation in video-guided MMT. Additionally, we preserved their contextual information to support research on leveraging the global context of documentaries in video-guided MMT. To better capture the shared semantics between text and video, we propose an MMT model based on a cross-modal bidirectional attention module. Extensive experiments on the TopicVD dataset demonstrate that visual information consistently improves the performance of the NMT model in documentary translation. However, the MMT model's performance significantly declines in out-of-domain scenarios, highlighting the need for effective domain adaptation methods. Additionally, experiments demonstrate that global context can effectively improve translation performance. % Dataset and our implementations are available at https://github.com/JinzeLv/TopicVD
A General Pseudonymization Framework for Cloud-Based LLMs: Replacing Privacy Information in Controlled Text Generation
Feb 21, 2025An increasing number of companies have begun providing services that leverage cloud-based large language models (LLMs), such as ChatGPT. However, this development raises substantial privacy concerns, as users' prompts are transmitted to and processed by the model providers. Among the various privacy protection methods for LLMs, those implemented during the pre-training and fine-tuning phrases fail to mitigate the privacy risks associated with the remote use of cloud-based LLMs by users. On the other hand, methods applied during the inference phrase are primarily effective in scenarios where the LLM's inference does not rely on privacy-sensitive information. In this paper, we outline the process of remote user interaction with LLMs and, for the first time, propose a detailed definition of a general pseudonymization framework applicable to cloud-based LLMs. The experimental results demonstrate that the proposed framework strikes an optimal balance between privacy protection and utility. The code for our method is available to the public at https://github.com/Mebymeby/Pseudonymization-Framework.
Multi-intent Aware Contrastive Learning for Sequential Recommendation
Sep 13, 2024Intent is a significant latent factor influencing user-item interaction sequences. Prevalent sequence recommendation models that utilize contrastive learning predominantly rely on single-intent representations to direct the training process. However, this paradigm oversimplifies real-world recommendation scenarios, attempting to encapsulate the diversity of intents within the single-intent level representation. SR models considering multi-intent information in their framework are more likely to reflect real-life recommendation scenarios accurately.
Exploring the Necessity of Visual Modality in Multimodal Machine Translation using Authentic Datasets
Apr 09, 2024



Recent research in the field of multimodal machine translation (MMT) has indicated that the visual modality is either dispensable or offers only marginal advantages. However, most of these conclusions are drawn from the analysis of experimental results based on a limited set of bilingual sentence-image pairs, such as Multi30k. In these kinds of datasets, the content of one bilingual parallel sentence pair must be well represented by a manually annotated image, which is different from the real-world translation scenario. In this work, we adhere to the universal multimodal machine translation framework proposed by Tang et al. (2022). This approach allows us to delve into the impact of the visual modality on translation efficacy by leveraging real-world translation datasets. Through a comprehensive exploration via probing tasks, we find that the visual modality proves advantageous for the majority of authentic translation datasets. Notably, the translation performance primarily hinges on the alignment and coherence between textual and visual contents. Furthermore, our results suggest that visual information serves a supplementary role in multimodal translation and can be substituted.
Multimodal Neural Machine Translation with Search Engine Based Image Retrieval
Jul 26, 2022
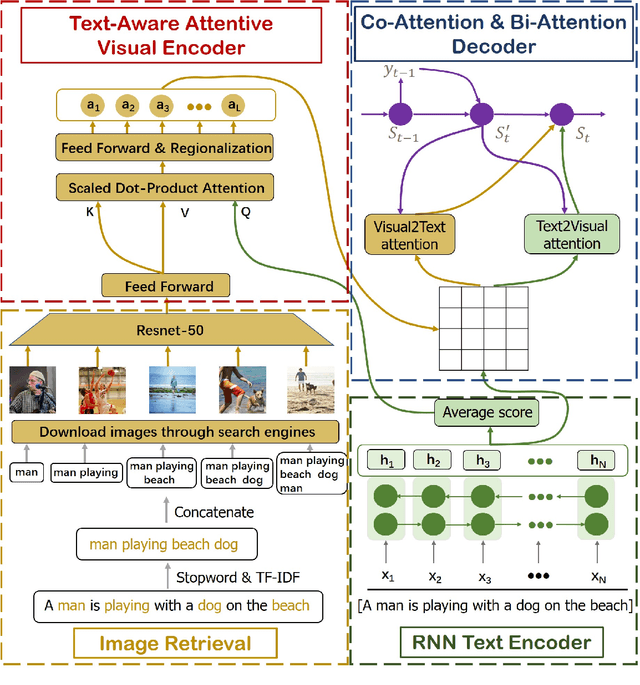

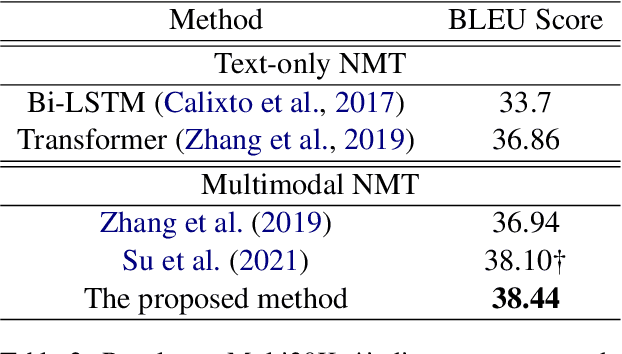
Recently, numbers of works shows that the performance of neural machine translation (NMT) can be improved to a certain extent with using visual information. However, most of these conclusions are drawn from the analysis of experimental results based on a limited set of bilingual sentence-image pairs, such as Multi30K. In these kinds of datasets, the content of one bilingual parallel sentence pair must be well represented by a manually annotated image, which is different with the actual translation situation. Some previous works are proposed to addressed the problem by retrieving images from exiting sentence-image pairs with topic model. However, because of the limited collection of sentence-image pairs they used, their image retrieval method is difficult to deal with the out-of-vocabulary words, and can hardly prove that visual information enhance NMT rather than the co-occurrence of images and sentences. In this paper, we propose an open-vocabulary image retrieval methods to collect descriptive images for bilingual parallel corpus using image search engine. Next, we propose text-aware attentive visual encoder to filter incorrectly collected noise images. Experiment results on Multi30K and other two translation datasets show that our proposed method achieves significant improvements over strong baselines.
Collecting Indicators of Compromise from Unstructured Text of Cybersecurity Articles using Neural-Based Sequence Labelling
Jul 04, 2019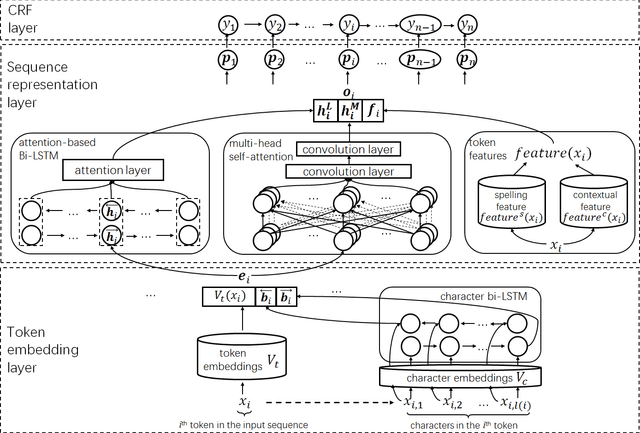
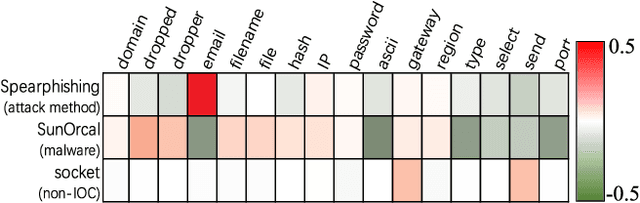
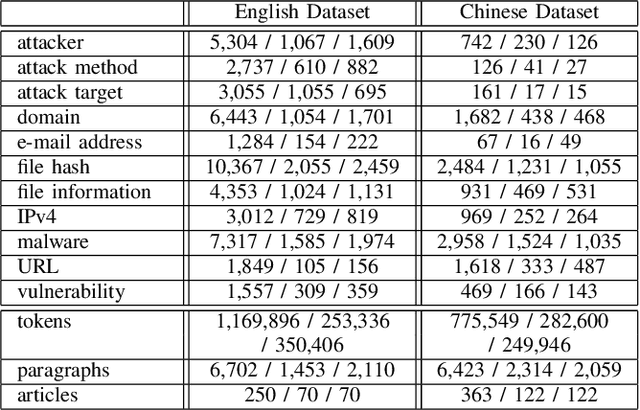

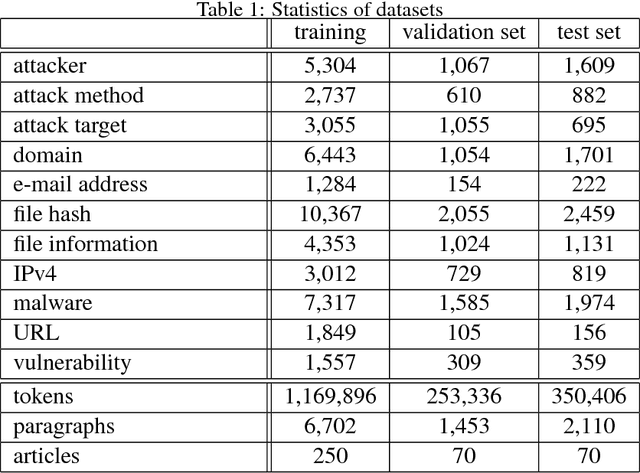
Indicators of Compromise (IOCs) are artifacts observed on a network or in an operating system that can be utilized to indicate a computer intrusion and detect cyber-attacks in an early stage. Thus, they exert an important role in the field of cybersecurity. However, state-of-the-art IOCs detection systems rely heavily on hand-crafted features with expert knowledge of cybersecurity, and require large-scale manually annotated corpora to train an IOC classifier. In this paper, we propose using an end-to-end neural-based sequence labelling model to identify IOCs automatically from cybersecurity articles without expert knowledge of cybersecurity. By using a multi-head self-attention module and contextual features, we find that the proposed model is capable of gathering contextual information from texts of cybersecurity articles and performs better in the task of IOC identification. Experiments show that the proposed model outperforms other sequence labelling models, achieving the average F1-score of 89.0% on English cybersecurity article test set, and approximately the average F1-score of 81.8% on Chinese test set.
Automatic Identification of Indicators of Compromise using Neural-Based Sequence Labelling
Oct 24, 2018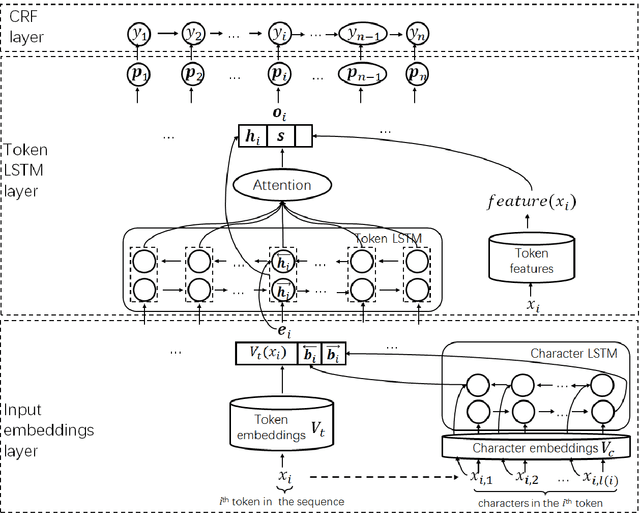

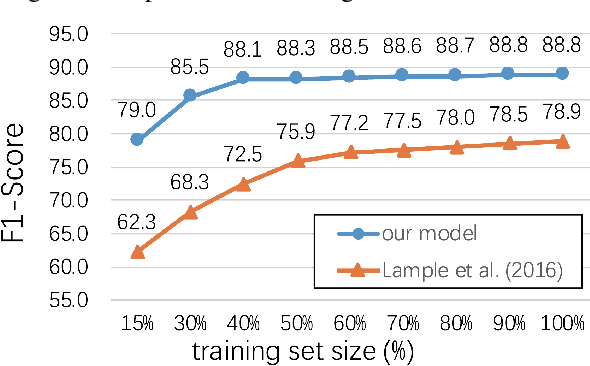
Indicators of Compromise (IOCs) are artifacts observed on a network or in an operating system that can be utilized to indicate a computer intrusion and detect cyber-attacks in an early stage. Thus, they exert an important role in the field of cybersecurity. However, state-of-the-art IOCs detection systems rely heavily on hand-crafted features with expert knowledge of cybersecurity, and require a large amount of supervised training corpora to train an IOC classifier. In this paper, we propose using a neural-based sequence labelling model to identify IOCs automatically from reports on cybersecurity without expert knowledge of cybersecurity. Our work is the first to apply an end-to-end sequence labelling to the task in IOCs identification. By using an attention mechanism and several token spelling features, we find that the proposed model is capable of identifying the low frequency IOCs from long sentences contained in cybersecurity reports. Experiments show that the proposed model outperforms other sequence labelling models, achieving over 88% average F1-score.