 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollecting Indicators of Compromise from Unstructured Text of Cybersecurity Articles using Neural-Based Sequence Labelling
Jul 04, 2019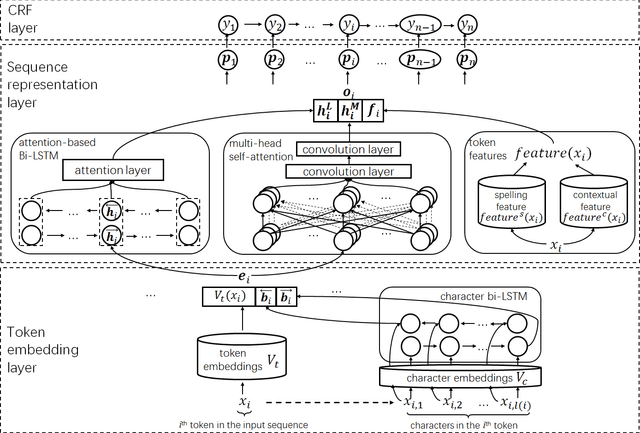
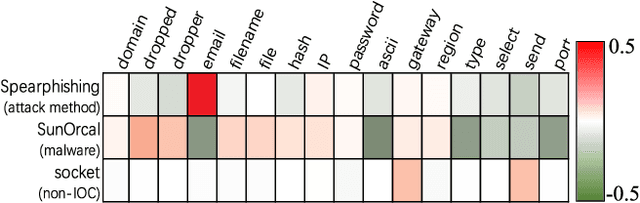
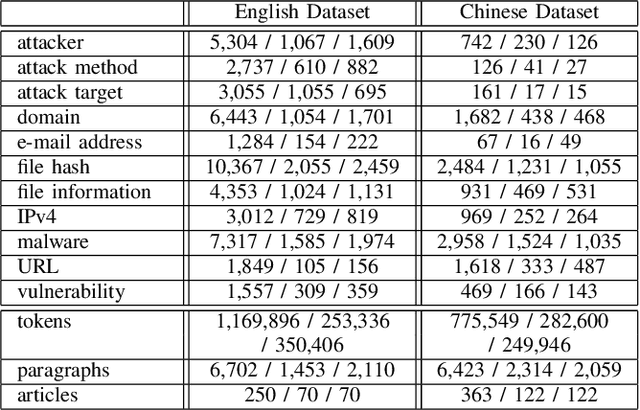

Indicators of Compromise (IOCs) are artifacts observed on a network or in an operating system that can be utilized to indicate a computer intrusion and detect cyber-attacks in an early stage. Thus, they exert an important role in the field of cybersecurity. However, state-of-the-art IOCs detection systems rely heavily on hand-crafted features with expert knowledge of cybersecurity, and require large-scale manually annotated corpora to train an IOC classifier. In this paper, we propose using an end-to-end neural-based sequence labelling model to identify IOCs automatically from cybersecurity articles without expert knowledge of cybersecurity. By using a multi-head self-attention module and contextual features, we find that the proposed model is capable of gathering contextual information from texts of cybersecurity articles and performs better in the task of IOC identification. Experiments show that the proposed model outperforms other sequence labelling models, achieving the average F1-score of 89.0% on English cybersecurity article test set, and approximately the average F1-score of 81.8% on Chinese test set.
Automatic Identification of Indicators of Compromise using Neural-Based Sequence Labelling
Oct 24, 2018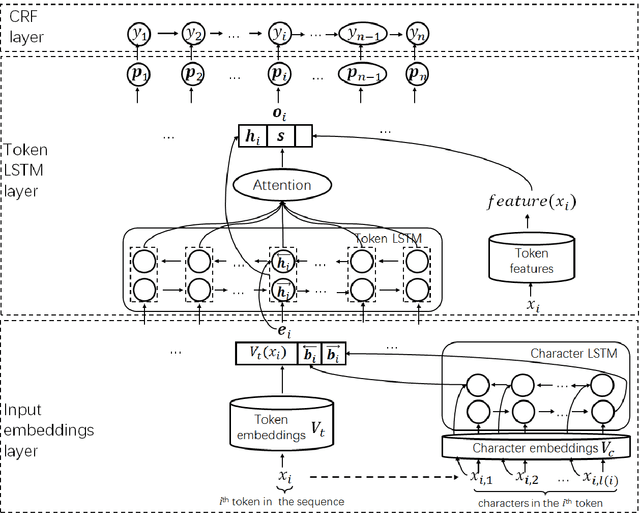
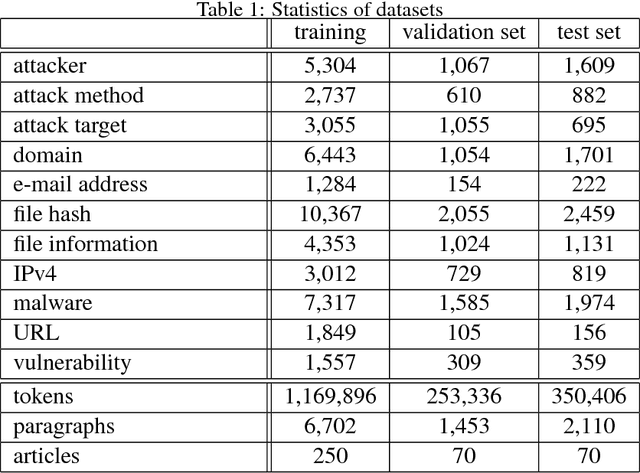

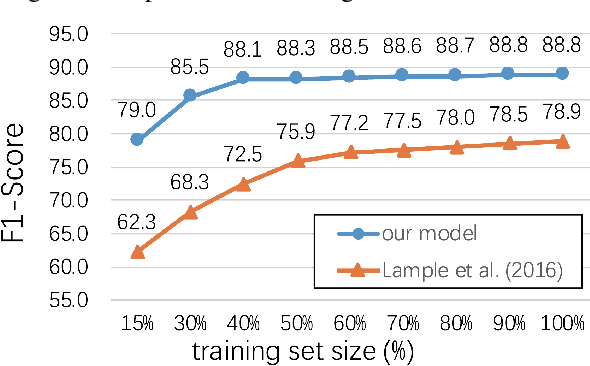
Indicators of Compromise (IOCs) are artifacts observed on a network or in an operating system that can be utilized to indicate a computer intrusion and detect cyber-attacks in an early stage. Thus, they exert an important role in the field of cybersecurity. However, state-of-the-art IOCs detection systems rely heavily on hand-crafted features with expert knowledge of cybersecurity, and require a large amount of supervised training corpora to train an IOC classifier. In this paper, we propose using a neural-based sequence labelling model to identify IOCs automatically from reports on cybersecurity without expert knowledge of cybersecurity. Our work is the first to apply an end-to-end sequence labelling to the task in IOCs identification. By using an attention mechanism and several token spelling features, we find that the proposed model is capable of identifying the low frequency IOCs from long sentences contained in cybersecurity reports. Experiments show that the proposed model outperforms other sequence labelling models, achieving over 88% average F1-score.