 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKV-CoRE: Benchmarking Data-Dependent Low-Rank Compressibility of KV-Caches in LLMs
Feb 05, 2026Large language models rely on kv-caches to avoid redundant computation during autoregressive decoding, but as context length grows, reading and writing the cache can quickly saturate GPU memory bandwidth. Recent work has explored KV-cache compression, yet most approaches neglect the data-dependent nature of kv-caches and their variation across layers. We introduce KV-CoRE KV-cache Compressibility by Rank Evaluation), an SVD-based method for quantifying the data-dependent low-rank compressibility of kv-caches. KV-CoRE computes the optimal low-rank approximation under the Frobenius norm and, being gradient-free and incremental, enables efficient dataset-level, layer-wise evaluation. Using this method, we analyze multiple models and datasets spanning five English domains and sixteen languages, uncovering systematic patterns that link compressibility to model architecture, training data, and language coverage. As part of this analysis, we employ the Normalized Effective Rank as a metric of compressibility and show that it correlates strongly with performance degradation under compression. Our study establishes a principled evaluation framework and the first large-scale benchmark of kv-cache compressibility in LLMs, offering insights for dynamic, data-aware compression and data-centric model development.
DFlash: Block Diffusion for Flash Speculative Decoding
Feb 05, 2026Autoregressive large language models (LLMs) deliver strong performance but require inherently sequential decoding, leading to high inference latency and poor GPU utilization. Speculative decoding mitigates this bottleneck by using a fast draft model whose outputs are verified in parallel by the target LLM; however, existing methods still rely on autoregressive drafting, which remains sequential and limits practical speedups. Diffusion LLMs offer a promising alternative by enabling parallel generation, but current diffusion models typically underperform compared with autoregressive models. In this paper, we introduce DFlash, a speculative decoding framework that employs a lightweight block diffusion model for parallel drafting. By generating draft tokens in a single forward pass and conditioning the draft model on context features extracted from the target model, DFlash enables efficient drafting with high-quality outputs and higher acceptance rates. Experiments show that DFlash achieves over 6x lossless acceleration across a range of models and tasks, delivering up to 2.5x higher speedup than the state-of-the-art speculative decoding method EAGLE-3.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Q Cache: Visual Attention is Valuable in Less than Half of Decode Layers for Multimodal Large Language Model
Feb 02, 2026Multimodal large language models (MLLMs) are plagued by exorbitant inference costs attributable to the profusion of visual tokens within the vision encoder. The redundant visual tokens engenders a substantial computational load and key-value (KV) cache footprint bottleneck. Existing approaches focus on token-wise optimization, leveraging diverse intricate token pruning techniques to eliminate non-crucial visual tokens. Nevertheless, these methods often unavoidably undermine the integrity of the KV cache, resulting in failures in long-text generation tasks. To this end, we conduct an in-depth investigation towards the attention mechanism of the model from a new perspective, and discern that attention within more than half of all decode layers are semantic similar. Upon this finding, we contend that the attention in certain layers can be streamlined by inheriting the attention from their preceding layers. Consequently, we propose Lazy Attention, an efficient attention mechanism that enables cross-layer sharing of similar attention patterns. It ingeniously reduces layer-wise redundant computation in attention. In Lazy Attention, we develop a novel layer-shared cache, Q Cache, tailored for MLLMs, which facilitates the reuse of queries across adjacent layers. In particular, Q Cache is lightweight and fully compatible with existing inference frameworks, including Flash Attention and KV cache. Additionally, our method is highly flexible as it is orthogonal to existing token-wise techniques and can be deployed independently or combined with token pruning approaches. Empirical evaluations on multiple benchmarks demonstrate that our method can reduce KV cache usage by over 35% and achieve 1.5x throughput improvement, while sacrificing only approximately 1% of performance on various MLLMs. Compared with SOTA token-wise methods, our technique achieves superior accuracy preservation.
Can LLMs Estimate Student Struggles? Human-AI Difficulty Alignment with Proficiency Simulation for Item Difficulty Prediction
Dec 21, 2025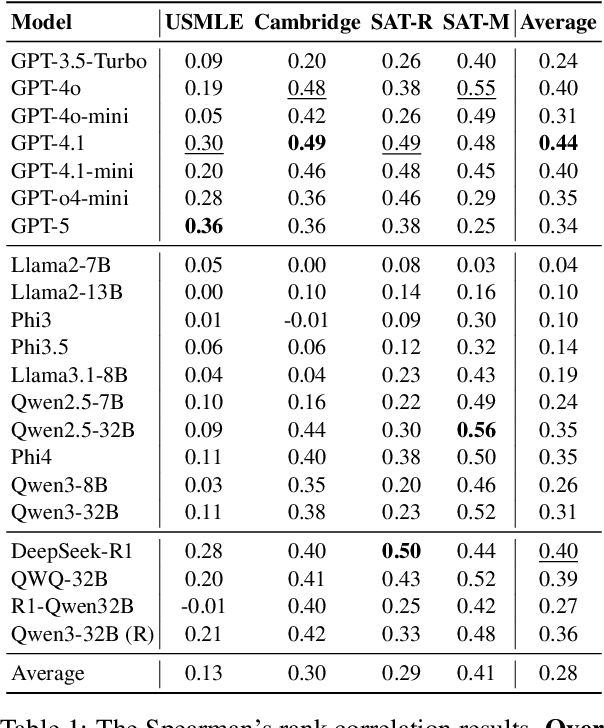
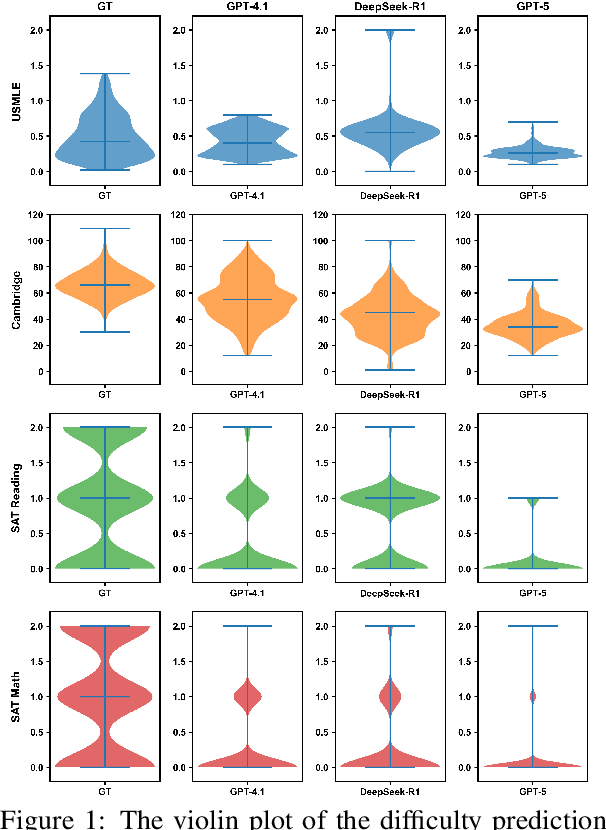
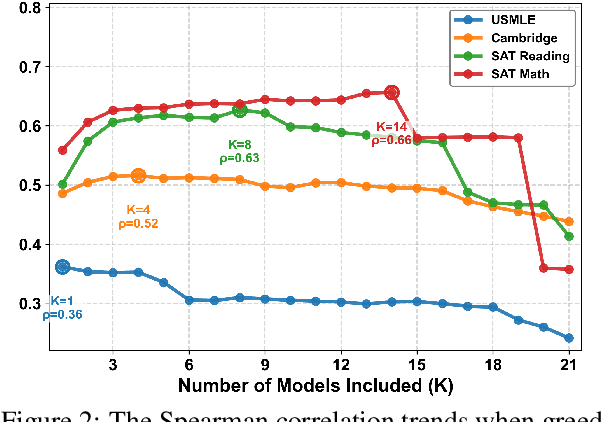
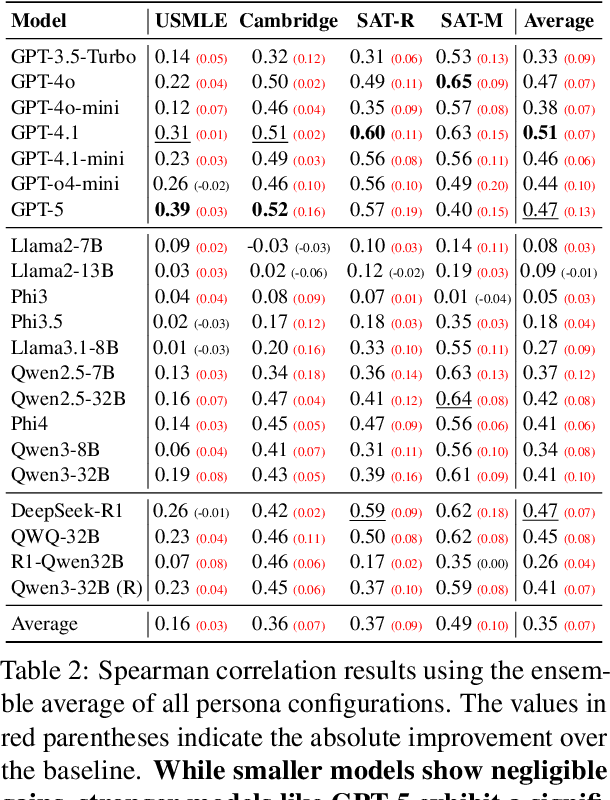
Accurate estimation of item (question or task) difficulty is critical for educational assessment but suffers from the cold start problem. While Large Language Models demonstrate superhuman problem-solving capabilities, it remains an open question whether they can perceive the cognitive struggles of human learners. In this work, we present a large-scale empirical analysis of Human-AI Difficulty Alignment for over 20 models across diverse domains such as medical knowledge and mathematical reasoning. Our findings reveal a systematic misalignment where scaling up model size is not reliably helpful; instead of aligning with humans, models converge toward a shared machine consensus. We observe that high performance often impedes accurate difficulty estimation, as models struggle to simulate the capability limitations of students even when being explicitly prompted to adopt specific proficiency levels. Furthermore, we identify a critical lack of introspection, as models fail to predict their own limitations. These results suggest that general problem-solving capability does not imply an understanding of human cognitive struggles, highlighting the challenge of using current models for automated difficulty prediction.
AutoSynth: Automated Workflow Optimization for High-Quality Synthetic Dataset Generation via Monte Carlo Tree Search
Nov 12, 2025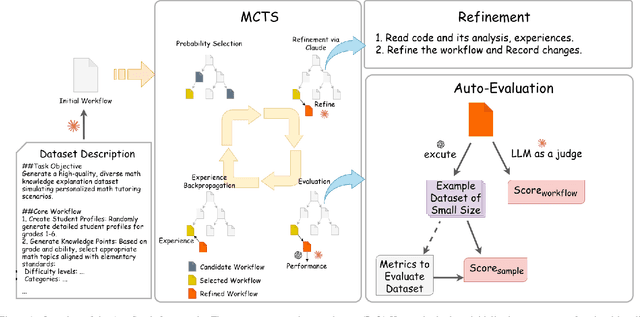


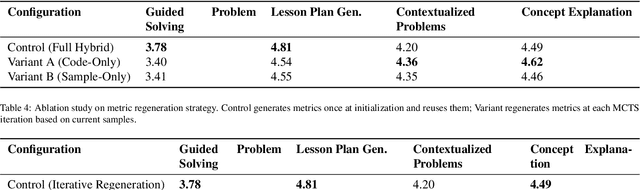
Supervised fine-tuning (SFT) of large language models (LLMs) for specialized tasks requires high-quality datasets, but manual curation is prohibitively expensive. Synthetic data generation offers scalability, but its effectiveness relies on complex, multi-stage workflows, integrating prompt engineering and model orchestration. Existing automated workflow methods face a cold start problem: they require labeled datasets for reward modeling, which is especially problematic for subjective, open-ended tasks with no objective ground truth. We introduce AutoSynth, a framework that automates workflow discovery and optimization without reference datasets by reframing the problem as a Monte Carlo Tree Search guided by a novel dataset-free hybrid reward. This reward enables meta-learning through two LLM-as-judge components: one evaluates sample quality using dynamically generated task-specific metrics, and another assesses workflow code and prompt quality. Experiments on subjective educational tasks show that while expert-designed workflows achieve higher human preference rates (96-99% win rates vs. AutoSynth's 40-51%), models trained on AutoSynth-generated data dramatically outperform baselines (40-51% vs. 2-5%) and match or surpass expert workflows on certain metrics, suggesting discovery of quality dimensions beyond human intuition. These results are achieved while reducing human effort from 5-7 hours to just 30 minutes (>90% reduction). AutoSynth tackles the cold start issue in data-centric AI, offering a scalable, cost-effective method for subjective LLM tasks. Code: https://github.com/bisz9918-maker/AutoSynth.
Revisiting Cross-Architecture Distillation: Adaptive Dual-Teacher Transfer for Lightweight Video Models
Nov 12, 2025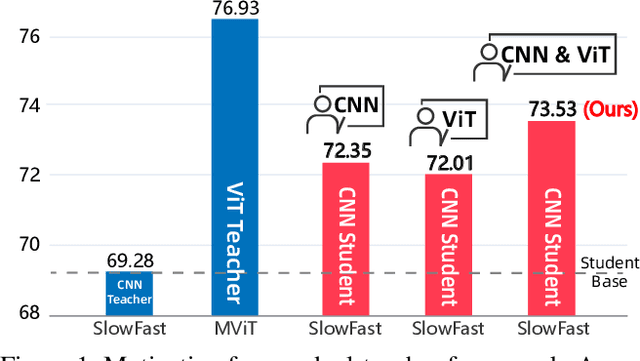

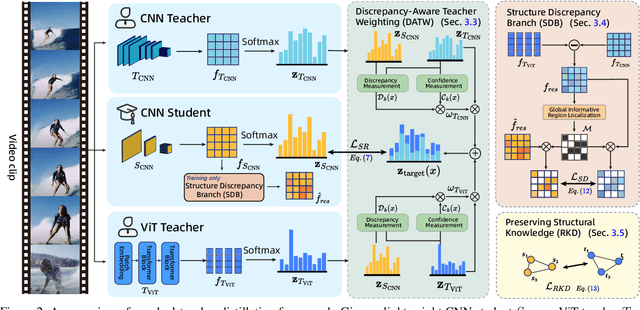

Vision Transformers (ViTs) have achieved strong performance in video action recognition, but their high computational cost limits their practicality. Lightweight CNNs are more efficient but suffer from accuracy gaps. Cross-Architecture Knowledge Distillation (CAKD) addresses this by transferring knowledge from ViTs to CNNs, yet existing methods often struggle with architectural mismatch and overlook the value of stronger homogeneous CNN teachers. To tackle these challenges, we propose a Dual-Teacher Knowledge Distillation framework that leverages both a heterogeneous ViT teacher and a homogeneous CNN teacher to collaboratively guide a lightweight CNN student. We introduce two key components: (1) Discrepancy-Aware Teacher Weighting, which dynamically fuses the predictions from ViT and CNN teachers by assigning adaptive weights based on teacher confidence and prediction discrepancy with the student, enabling more informative and effective supervision; and (2) a Structure Discrepancy-Aware Distillation strategy, where the student learns the residual features between ViT and CNN teachers via a lightweight auxiliary branch, focusing on transferable architectural differences without mimicking all of ViT's high-dimensional patterns. Extensive experiments on benchmarks including HMDB51, EPIC-KITCHENS-100, and Kinetics-400 demonstrate that our method consistently outperforms state-of-the-art distillation approaches, achieving notable performance improvements with a maximum accuracy gain of 5.95% on HMDB51.
DeKeyNLU: Enhancing Natural Language to SQL Generation through Task Decomposition and Keyword Extraction
Sep 18, 2025



Natural Language to SQL (NL2SQL) provides a new model-centric paradigm that simplifies database access for non-technical users by converting natural language queries into SQL commands. Recent advancements, particularly those integrating Retrieval-Augmented Generation (RAG) and Chain-of-Thought (CoT) reasoning, have made significant strides in enhancing NL2SQL performance. However, challenges such as inaccurate task decomposition and keyword extraction by LLMs remain major bottlenecks, often leading to errors in SQL generation. While existing datasets aim to mitigate these issues by fine-tuning models, they struggle with over-fragmentation of tasks and lack of domain-specific keyword annotations, limiting their effectiveness. To address these limitations, we present DeKeyNLU, a novel dataset which contains 1,500 meticulously annotated QA pairs aimed at refining task decomposition and enhancing keyword extraction precision for the RAG pipeline. Fine-tuned with DeKeyNLU, we propose DeKeySQL, a RAG-based NL2SQL pipeline that employs three distinct modules for user question understanding, entity retrieval, and generation to improve SQL generation accuracy. We benchmarked multiple model configurations within DeKeySQL RAG pipeline. Experimental results demonstrate that fine-tuning with DeKeyNLU significantly improves SQL generation accuracy on both BIRD (62.31% to 69.10%) and Spider (84.2% to 88.7%) dev datasets.
Arce: Augmented Roberta with Contextualized Elucidations for Ner in Automated Rule Checking
Aug 10, 2025Accurate information extraction from specialized texts is a critical challenge, particularly for named entity recognition (NER) in the architecture, engineering, and construction (AEC) domain to support automated rule checking (ARC). The performance of standard pre-trained models is often constrained by the domain gap, as they struggle to interpret the specialized terminology and complex relational contexts inherent in AEC texts. Although this issue can be mitigated by further pre-training on large, human-curated domain corpora, as exemplified by methods like ARCBERT, this approach is both labor-intensive and cost-prohibitive. Consequently, leveraging large language models (LLMs) for automated knowledge generation has emerged as a promising alternative. However, the optimal strategy for generating knowledge that can genuinely enhance smaller, efficient models remains an open question. To address this, we propose ARCE (augmented RoBERTa with contextualized elucidations), a novel approach that systematically explores and optimizes this generation process. ARCE employs an LLM to first generate a corpus of simple, direct explanations, which we term Cote, and then uses this corpus to incrementally pre-train a RoBERTa model prior to its fine-tuning on the downstream task. Our extensive experiments show that ARCE establishes a new state-of-the-art on a benchmark AEC dataset, achieving a Macro-F1 score of 77.20%. This result also reveals a key finding: simple, explanation-based knowledge proves surprisingly more effective than complex, role-based rationales for this task. The code is publicly available at:https://github.com/nxcc-lab/ARCE.
VisR-Bench: An Empirical Study on Visual Retrieval-Augmented Generation for Multilingual Long Document Understanding
Aug 10, 2025Most organizational data in this world are stored as documents, and visual retrieval plays a crucial role in unlocking the collective intelligence from all these documents. However, existing benchmarks focus on English-only document retrieval or only consider multilingual question-answering on a single-page image. To bridge this gap, we introduce VisR-Bench, a multilingual benchmark designed for question-driven multimodal retrieval in long documents. Our benchmark comprises over 35K high-quality QA pairs across 1.2K documents, enabling fine-grained evaluation of multimodal retrieval. VisR-Bench spans sixteen languages with three question types (figures, text, and tables), offering diverse linguistic and question coverage. Unlike prior datasets, we include queries without explicit answers, preventing models from relying on superficial keyword matching. We evaluate various retrieval models, including text-based methods, multimodal encoders, and MLLMs, providing insights into their strengths and limitations. Our results show that while MLLMs significantly outperform text-based and multimodal encoder models, they still struggle with structured tables and low-resource languages, highlighting key challenges in multilingual visual retrieval.