 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Medical Vision-and-Language Applications and Their Techniques
Nov 19, 2024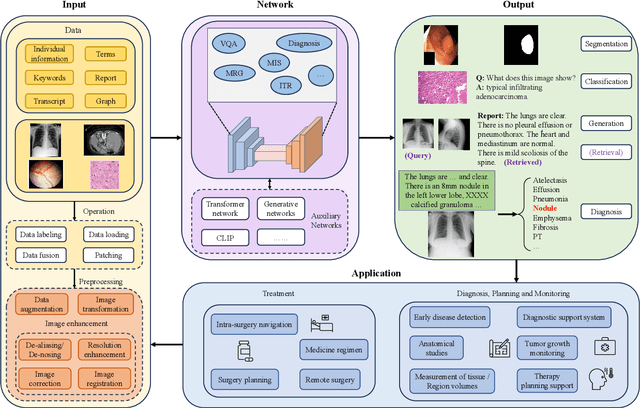
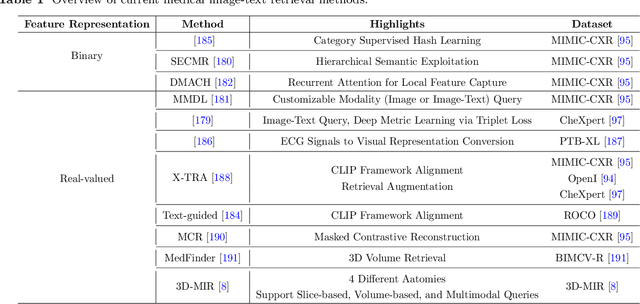
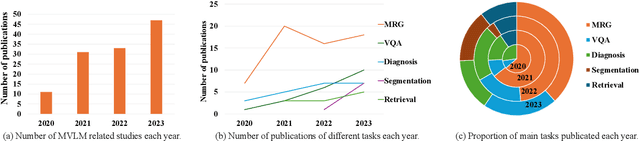
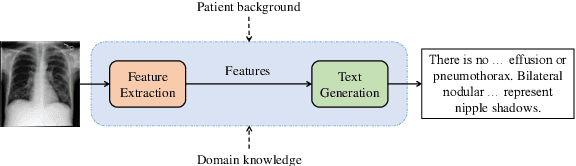
Medical vision-and-language models (MVLMs) have attracted substantial interest due to their capability to offer a natural language interface for interpreting complex medical data. Their applications are versatile and have the potential to improve diagnostic accuracy and decision-making for individual patients while also contributing to enhanced public health monitoring, disease surveillance, and policy-making through more efficient analysis of large data sets. MVLMS integrate natural language processing with medical images to enable a more comprehensive and contextual understanding of medical images alongside their corresponding textual information. Unlike general vision-and-language models trained on diverse, non-specialized datasets, MVLMs are purpose-built for the medical domain, automatically extracting and interpreting critical information from medical images and textual reports to support clinical decision-making. Popular clinical applications of MVLMs include automated medical report generation, medical visual question answering, medical multimodal segmentation, diagnosis and prognosis and medical image-text retrieval. Here, we provide a comprehensive overview of MVLMs and the various medical tasks to which they have been applied. We conduct a detailed analysis of various vision-and-language model architectures, focusing on their distinct strategies for cross-modal integration/exploitation of medical visual and textual features. We also examine the datasets used for these tasks and compare the performance of different models based on standardized evaluation metrics. Furthermore, we highlight potential challenges and summarize future research trends and directions. The full collection of papers and codes is available at: https://github.com/YtongXie/Medical-Vision-and-Language-Tasks-and-Methodologies-A-Survey.