 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInViC: Intent-aware Visual Cues for Medical Visual Question Answering
Mar 17, 2026Medical visual question answering (Med-VQA) aims to answer clinically relevant questions grounded in medical images. However, existing multimodal large language models (MLLMs) often exhibit shortcut answering, producing plausible responses by exploiting language priors or dataset biases while insufficiently attending to visual evidence. This behavior undermines clinical reliability, especially when subtle imaging findings are decisive. We propose a lightweight plug-in framework, termed Intent-aware Visual Cues (InViC), to explicitly enhance image-based answer generation in medical VQA. InViC introduces a Cue Tokens Extraction (CTE) module that distills dense visual tokens into a compact set of K question-conditioned cue tokens, which serve as structured visual intermediaries injected into the LLM decoder to promote intent-aligned visual evidence. To discourage bypassing of visual information, we further design a two-stage fine-tuning strategy with a cue-bottleneck attention mask. In Stage I, we employ an attention mask to block the LLM's direct view of raw visual features, thereby funneling all visual evidence through the cue pathway. In Stage II, standard causal attention is restored to train the LLM to jointly exploit the visual and cue tokens. We evaluate InViC on three public Med-VQA benchmarks (VQA-RAD, SLAKE, and ImageCLEF VQA-Med 2019) across multiple representative MLLMs. InViC consistently improves over zero-shot inference and standard LoRA fine-tuning, demonstrating that intent-aware visual cues with bottlenecked training is a practical and effective strategy for improving trustworthy Med-VQA.
Upper Generalization Bounds for Neural Oscillators
Mar 10, 2026Neural oscillators that originate from the second-order ordinary differential equations (ODEs) have shown competitive performance in learning mappings between dynamic loads and responses of complex nonlinear structural systems. Despite this empirical success, theoretically quantifying the generalization capacities of their neural network architectures remains undeveloped. In this study, the neural oscillator consisting of a second-order ODE followed by a multilayer perceptron (MLP) is considered. Its upper probably approximately correct (PAC) generalization bound for approximating causal and uniformly continuous operators between continuous temporal function spaces and that for approximating the uniformly asymptotically incrementally stable second-order dynamical systems are derived by leveraging the Rademacher complexity framework. The theoretical results show that the estimation errors grow polynomially with respect to both the MLP size and the time length, thereby avoiding the curse of parametric complexity. Furthermore, the derived error bounds demonstrate that constraining the Lipschitz constants of the MLPs via loss function regularization can improve the generalization ability of the neural oscillator. A numerical study considering a Bouc-Wen nonlinear system under stochastic seismic excitation validates the theoretically predicted power laws of the estimation errors with respect to the sample size and time length, and confirms the effectiveness of constraining MLPs' matrix and vector norms in enhancing the performance of the neural oscillator under limited training data.
Rethinking the Efficiency and Effectiveness of Reinforcement Learning for Radiology Report Generation
Mar 04, 2026Radiologists highly desire fully automated AI for radiology report generation (R2G), yet existing approaches fall short in clinical utility. Reinforcement learning (RL) holds potential to address these shortcomings, but its adoption in this task remains underexplored. In this paper, we revisit RL in terms of data efficiency and optimization effectiveness for R2G tasks. First, we explore the impact of data quantity and quality on the performance of RL in medical contexts, revealing that data quality plays a more critical role than quantity. To this end, we propose a diagnostic diversity-based data sampling strategy that enables comparable performance with fewer samples. Second, we observe that the majority of tokens in radiology reports are template-like and diagnostically uninformative, whereas the low frequency of clinically critical tokens heightens the risk of being overlooked during optimization. To tackle this, we introduce Diagnostic Token-weighted Policy Optimization (DiTPO), which directly optimizes for clinical accuracy by using a diagnostic F1 score as the reward signal. Unlike standard RL approaches that treat all tokens equally, DiTPO explicitly models the varying importance of different tokens through rule- or gradient-based mechanisms to prioritize clinically relevant content. Extensive experiments on the MIMIC-CXR, IU-Xray, and CheXpert Plus datasets demonstrate that our framework achieves state-of-the-art (SOTA) performance while requiring substantially fewer training samples in RL. Notably, on MIMIC-CXR, our framework attains an F1 score of 0.516 using only 20% of the RL training samples.
SegRap2025: A Benchmark of Gross Tumor Volume and Lymph Node Clinical Target Volume Segmentation for Radiotherapy Planning of Nasopharyngeal Carcinoma
Jan 28, 2026Accurate delineation of Gross Tumor Volume (GTV), Lymph Node Clinical Target Volume (LN CTV), and Organ-at-Risk (OAR) from Computed Tomography (CT) scans is essential for precise radiotherapy planning in Nasopharyngeal Carcinoma (NPC). Building upon SegRap2023, which focused on OAR and GTV segmentation using single-center paired non-contrast CT (ncCT) and contrast-enhanced CT (ceCT) scans, the SegRap2025 challenge aims to enhance the generalizability and robustness of segmentation models across imaging centers and modalities. SegRap2025 comprises two tasks: Task01 addresses GTV segmentation using paired CT from the SegRap2023 dataset, with an additional external testing set to evaluate cross-center generalization, and Task02 focuses on LN CTV segmentation using multi-center training data and an unseen external testing set, where each case contains paired CT scans or a single modality, emphasizing both cross-center and cross-modality robustness. This paper presents the challenge setup and provides a comprehensive analysis of the solutions submitted by ten participating teams. For GTV segmentation task, the top-performing models achieved average Dice Similarity Coefficient (DSC) of 74.61% and 56.79% on the internal and external testing cohorts, respectively. For LN CTV segmentation task, the highest average DSC values reached 60.24%, 60.50%, and 57.23% on paired CT, ceCT-only, and ncCT-only subsets, respectively. SegRap2025 establishes a large-scale multi-center, multi-modality benchmark for evaluating the generalization and robustness in radiotherapy target segmentation, providing valuable insights toward clinically applicable automated radiotherapy planning systems. The benchmark is available at: https://hilab-git.github.io/SegRap2025_Challenge.
V-Loop: Visual Logical Loop Verification for Hallucination Detection in Medical Visual Question Answering
Jan 26, 2026Multimodal Large Language Models (MLLMs) have shown remarkable capability in assisting disease diagnosis in medical visual question answering (VQA). However, their outputs remain vulnerable to hallucinations (i.e., responses that contradict visual facts), posing significant risks in high-stakes medical scenarios. Recent introspective detection methods, particularly uncertainty-based approaches, offer computational efficiency but are fundamentally indirect, as they estimate predictive uncertainty for an image-question pair rather than verifying the factual correctness of a specific answer. To address this limitation, we propose Visual Logical Loop Verification (V-Loop), a training-free and plug-and-play framework for hallucination detection in medical VQA. V-Loop introduces a bidirectional reasoning process that forms a visually grounded logical loop to verify factual correctness. Given an input, the MLLM produces an answer for the primary input pair. V-Loop extracts semantic units from the primary QA pair, generates a verification question by conditioning on the answer unit to re-query the question unit, and enforces visual attention consistency to ensure answering both primary question and verification question rely on the same image evidence. If the verification answer matches the expected semantic content, the logical loop closes, indicating factual grounding; otherwise, the primary answer is flagged as hallucinated. Extensive experiments on multiple medical VQA benchmarks and MLLMs show that V-Loop consistently outperforms existing introspective methods, remains highly efficient, and further boosts uncertainty-based approaches when used in combination.
PAINT: Pathology-Aware Integrated Next-Scale Transformation for Virtual Immunohistochemistry
Jan 22, 2026Virtual immunohistochemistry (IHC) aims to computationally synthesize molecular staining patterns from routine Hematoxylin and Eosin (H\&E) images, offering a cost-effective and tissue-efficient alternative to traditional physical staining. However, this task is particularly challenging: H\&E morphology provides ambiguous cues about protein expression, and similar tissue structures may correspond to distinct molecular states. Most existing methods focus on direct appearance synthesis to implicitly achieve cross-modal generation, often resulting in semantic inconsistencies due to insufficient structural priors. In this paper, we propose Pathology-Aware Integrated Next-Scale Transformation (PAINT), a visual autoregressive framework that reformulates the synthesis process as a structure-first conditional generation task. Unlike direct image translation, PAINT enforces a causal order by resolving molecular details conditioned on a global structural layout. Central to this approach is the introduction of a Spatial Structural Start Map (3S-Map), which grounds the autoregressive initialization in observed morphology, ensuring deterministic, spatially aligned synthesis. Experiments on the IHC4BC and MIST datasets demonstrate that PAINT outperforms state-of-the-art methods in structural fidelity and clinical downstream tasks, validating the potential of structure-guided autoregressive modeling.
FedBiCross: A Bi-Level Optimization Framework to Tackle Non-IID Challenges in Data-Free One-Shot Federated Learning on Medical Data
Jan 05, 2026Data-free knowledge distillation-based one-shot federated learning (OSFL) trains a model in a single communication round without sharing raw data, making OSFL attractive for privacy-sensitive medical applications. However, existing methods aggregate predictions from all clients to form a global teacher. Under non-IID data, conflicting predictions cancel out during averaging, yielding near-uniform soft labels that provide weak supervision for distillation. We propose FedBiCross, a personalized OSFL framework with three stages: (1) clustering clients by model output similarity to form coherent sub-ensembles, (2) bi-level cross-cluster optimization that learns adaptive weights to selectively leverage beneficial cross-cluster knowledge while suppressing negative transfer, and (3) personalized distillation for client-specific adaptation. Experiments on four medical image datasets demonstrate that FedBiCross consistently outperforms state-of-the-art baselines across different non-IID degrees.
ECG-aBcDe: Overcoming Model Dependence, Encoding ECG into a Universal Language for Any LLM
Sep 16, 2025Large Language Models (LLMs) hold significant promise for electrocardiogram (ECG) analysis, yet challenges remain regarding transferability, time-scale information learning, and interpretability. Current methods suffer from model-specific ECG encoders, hindering transfer across LLMs. Furthermore, LLMs struggle to capture crucial time-scale information inherent in ECGs due to Transformer limitations. And their black-box nature limits clinical adoption. To address these limitations, we introduce ECG-aBcDe, a novel ECG encoding method that transforms ECG signals into a universal ECG language readily interpretable by any LLM. By constructing a hybrid dataset of ECG language and natural language, ECG-aBcDe enables direct fine-tuning of pre-trained LLMs without architectural modifications, achieving "construct once, use anywhere" capability. Moreover, the bidirectional convertibility between ECG and ECG language of ECG-aBcDe allows for extracting attention heatmaps from ECG signals, significantly enhancing interpretability. Finally, ECG-aBcDe explicitly represents time-scale information, mitigating Transformer limitations. This work presents a new paradigm for integrating ECG analysis with LLMs. Compared with existing methods, our method achieves competitive performance on ROUGE-L and METEOR. Notably, it delivers significant improvements in the BLEU-4, with improvements of 2.8 times and 3.9 times in in-dataset and cross-dataset evaluations, respectively, reaching scores of 42.58 and 30.76. These results provide strong evidence for the feasibility of the new paradigm.
Unified Start, Personalized End: Progressive Pruning for Efficient 3D Medical Image Segmentation
Sep 11, 20253D medical image segmentation often faces heavy resource and time consumption, limiting its scalability and rapid deployment in clinical environments. Existing efficient segmentation models are typically static and manually designed prior to training, which restricts their adaptability across diverse tasks and makes it difficult to balance performance with resource efficiency. In this paper, we propose PSP-Seg, a progressive pruning framework that enables dynamic and efficient 3D segmentation. PSP-Seg begins with a redundant model and iteratively prunes redundant modules through a combination of block-wise pruning and a functional decoupling loss. We evaluate PSP-Seg on five public datasets, benchmarking it against seven state-of-the-art models and six efficient segmentation models. Results demonstrate that the lightweight variant, PSP-Seg-S, achieves performance on par with nnU-Net while reducing GPU memory usage by 42-45%, training time by 29-48%, and parameter number by 83-87% across all datasets. These findings underscore PSP-Seg's potential as a cost-effective yet high-performing alternative for widespread clinical application.
Toward Robust Medical Fairness: Debiased Dual-Modal Alignment via Text-Guided Attribute-Disentangled Prompt Learning for Vision-Language Models
Aug 26, 2025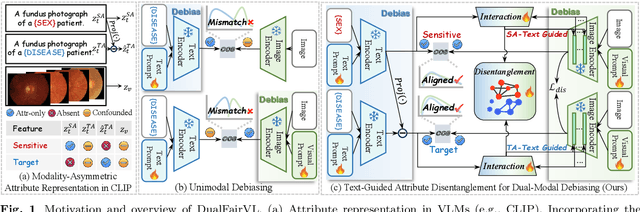
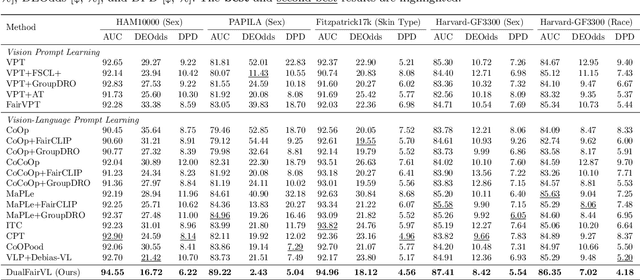
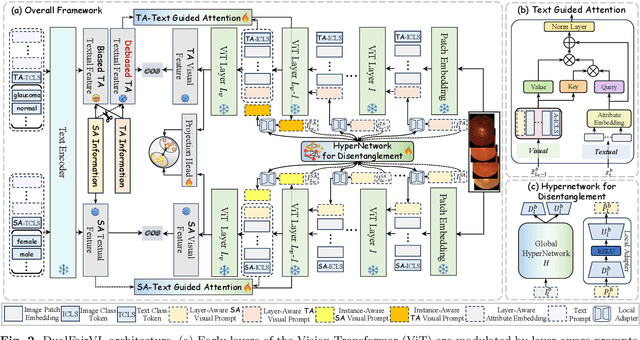
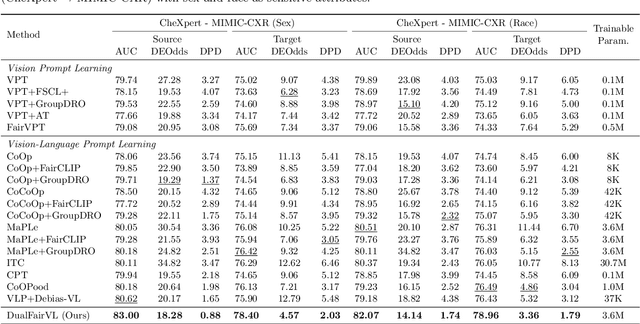
Ensuring fairness across demographic groups in medical diagnosis is essential for equitable healthcare, particularly under distribution shifts caused by variations in imaging equipment and clinical practice. Vision-language models (VLMs) exhibit strong generalization, and text prompts encode identity attributes, enabling explicit identification and removal of sensitive directions. However, existing debiasing approaches typically address vision and text modalities independently, leaving residual cross-modal misalignment and fairness gaps. To address this challenge, we propose DualFairVL, a multimodal prompt-learning framework that jointly debiases and aligns cross-modal representations. DualFairVL employs a parallel dual-branch architecture that separates sensitive and target attributes, enabling disentangled yet aligned representations across modalities. Approximately orthogonal text anchors are constructed via linear projections, guiding cross-attention mechanisms to produce fused features. A hypernetwork further disentangles attribute-related information and generates instance-aware visual prompts, which encode dual-modal cues for fairness and robustness. Prototype-based regularization is applied in the visual branch to enforce separation of sensitive features and strengthen alignment with textual anchors. Extensive experiments on eight medical imaging datasets across four modalities show that DualFairVL achieves state-of-the-art fairness and accuracy under both in- and out-of-distribution settings, outperforming full fine-tuning and parameter-efficient baselines with only 3.6M trainable parameters. Code will be released upon publication.