 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Random Masking: A Dual-Stream Approach for Rotation-Invariant Point Cloud Masked Autoencoders
Sep 18, 2025Existing rotation-invariant point cloud masked autoencoders (MAE) rely on random masking strategies that overlook geometric structure and semantic coherence. Random masking treats patches independently, failing to capture spatial relationships consistent across orientations and overlooking semantic object parts that maintain identity regardless of rotation. We propose a dual-stream masking approach combining 3D Spatial Grid Masking and Progressive Semantic Masking to address these fundamental limitations. Grid masking creates structured patterns through coordinate sorting to capture geometric relationships that persist across different orientations, while semantic masking uses attention-driven clustering to discover semantically meaningful parts and maintain their coherence during masking. These complementary streams are orchestrated via curriculum learning with dynamic weighting, progressing from geometric understanding to semantic discovery. Designed as plug-and-play components, our strategies integrate into existing rotation-invariant frameworks without architectural changes, ensuring broad compatibility across different approaches. Comprehensive experiments on ModelNet40, ScanObjectNN, and OmniObject3D demonstrate consistent improvements across various rotation scenarios, showing substantial performance gains over the baseline rotation-invariant methods.
LLM-Enhanced Rapid-Reflex Async-Reflect Embodied Agent for Real-Time Decision-Making in Dynamically Changing Environments
Jun 08, 2025In the realm of embodied intelligence, the evolution of large language models (LLMs) has markedly enhanced agent decision making. Consequently, researchers have begun exploring agent performance in dynamically changing high-risk scenarios, i.e., fire, flood, and wind scenarios in the HAZARD benchmark. Under these extreme conditions, the delay in decision making emerges as a crucial yet insufficiently studied issue. We propose a Time Conversion Mechanism (TCM) that translates inference delays in decision-making into equivalent simulation frames, thus aligning cognitive and physical costs under a single FPS-based metric. By extending HAZARD with Respond Latency (RL) and Latency-to-Action Ratio (LAR), we deliver a fully latency-aware evaluation protocol. Moreover, we present the Rapid-Reflex Async-Reflect Agent (RRARA), which couples a lightweight LLM-guided feedback module with a rule-based agent to enable immediate reactive behaviors and asynchronous reflective refinements in situ. Experiments on HAZARD show that RRARA substantially outperforms existing baselines in latency-sensitive scenarios.
HFBRI-MAE: Handcrafted Feature Based Rotation-Invariant Masked Autoencoder for 3D Point Cloud Analysis
Apr 19, 2025Self-supervised learning (SSL) has demonstrated remarkable success in 3D point cloud analysis, particularly through masked autoencoders (MAEs). However, existing MAE-based methods lack rotation invariance, leading to significant performance degradation when processing arbitrarily rotated point clouds in real-world scenarios. To address this limitation, we introduce Handcrafted Feature-Based Rotation-Invariant Masked Autoencoder (HFBRI-MAE), a novel framework that refines the MAE design with rotation-invariant handcrafted features to ensure stable feature learning across different orientations. By leveraging both rotation-invariant local and global features for token embedding and position embedding, HFBRI-MAE effectively eliminates rotational dependencies while preserving rich geometric structures. Additionally, we redefine the reconstruction target to a canonically aligned version of the input, mitigating rotational ambiguities. Extensive experiments on ModelNet40, ScanObjectNN, and ShapeNetPart demonstrate that HFBRI-MAE consistently outperforms existing methods in object classification, segmentation, and few-shot learning, highlighting its robustness and strong generalization ability in real-world 3D applications.
Stealthy Patch-Wise Backdoor Attack in 3D Point Cloud via Curvature Awareness
Mar 12, 2025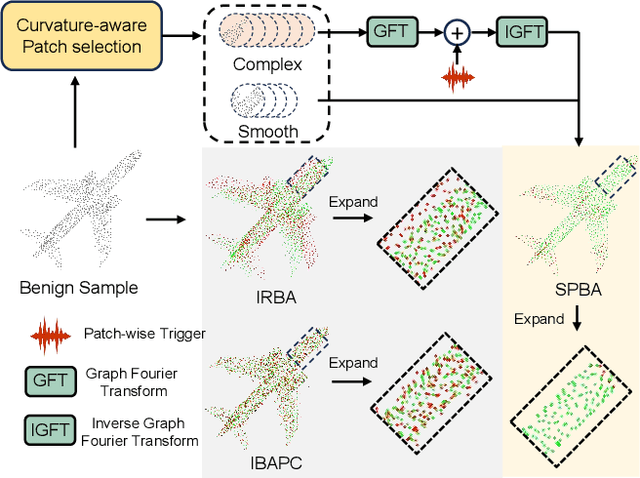
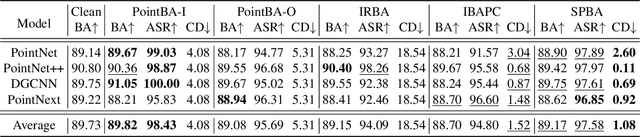
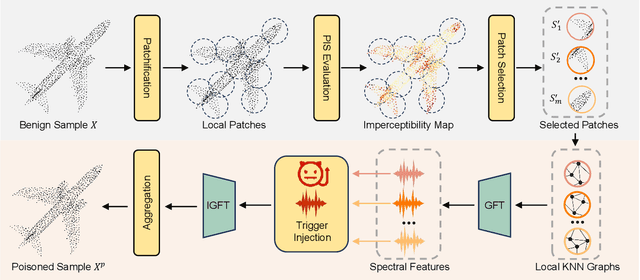
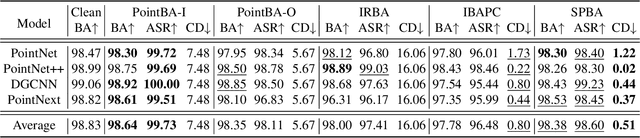
Backdoor attacks pose a severe threat to deep neural networks (DNN) by implanting hidden backdoors that can be activated with predefined triggers to manipulate model behaviors maliciously. Existing 3D point cloud backdoor attacks primarily rely on sample-wise global modifications, resulting in suboptimal stealthiness. To address this limitation, we propose Stealthy Patch-Wise Backdoor Attack (SPBA), which employs the first patch-wise trigger for 3D point clouds and restricts perturbations to local regions, significantly enhancing stealthiness. Specifically, SPBA decomposes point clouds into local patches and evaluates their geometric complexity using a curvature-based patch imperceptibility score, ensuring that the trigger remains less perceptible to the human eye by strategically applying it across multiple geometrically complex patches with lower visual sensitivity. By leveraging the Graph Fourier Transform (GFT), SPBA optimizes a patch-wise spectral trigger that perturbs the spectral features of selected patches, enhancing attack effectiveness while preserving the global geometric structure of the point cloud. Extensive experiments on ModelNet40 and ShapeNetPart demonstrate that SPBA consistently achieves an attack success rate (ASR) exceeding 96.5% across different models while achieving state-of-the-art imperceptibility compared to existing backdoor attack methods.
Enhancing Robustness to Noise Corruption for Point Cloud Model via Spatial Sorting and Set-Mixing Aggregation Module
Jul 15, 2024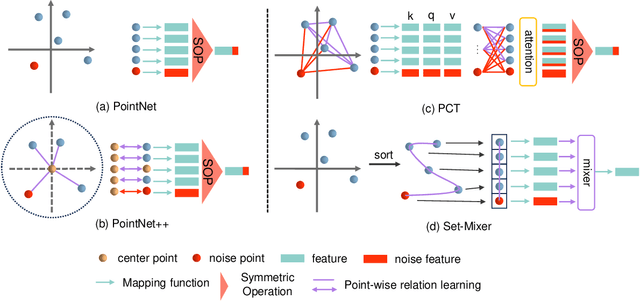
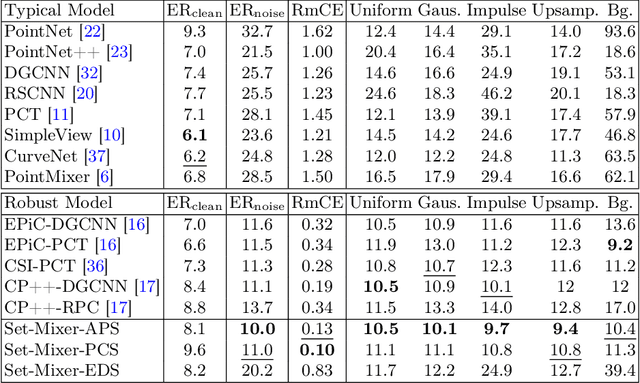
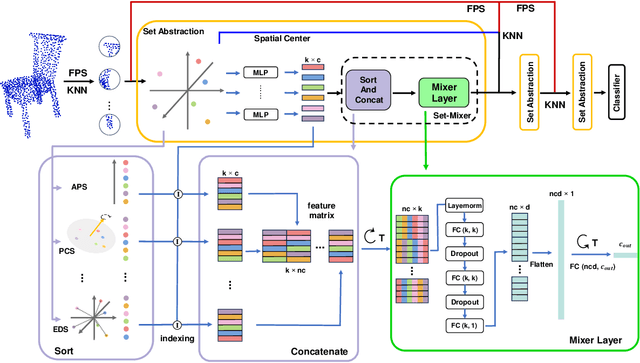
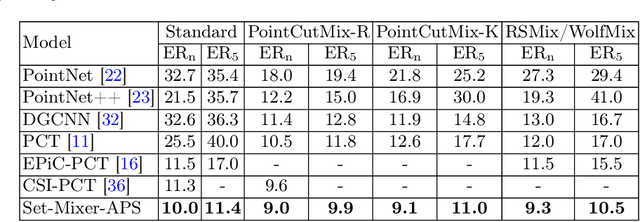
Current models for point cloud recognition demonstrate promising performance on synthetic datasets. However, real-world point cloud data inevitably contains noise, impacting model robustness. While recent efforts focus on enhancing robustness through various strategies, there still remains a gap in comprehensive analyzes from the standpoint of network architecture design. Unlike traditional methods that rely on generic techniques, our approach optimizes model robustness to noise corruption through network architecture design. Inspired by the token-mixing technique applied in 2D images, we propose Set-Mixer, a noise-robust aggregation module which facilitates communication among all points to extract geometric shape information and mitigating the influence of individual noise points. A sorting strategy is designed to enable our module to be invariant to point permutation, which also tackles the unordered structure of point cloud and introduces consistent relative spatial information. Experiments conducted on ModelNet40-C indicate that Set-Mixer significantly enhances the model performance on noisy point clouds, underscoring its potential to advance real-world applicability in 3D recognition and perception tasks.
PaRot: Patch-Wise Rotation-Invariant Network via Feature Disentanglement and Pose Restoration
Feb 06, 2023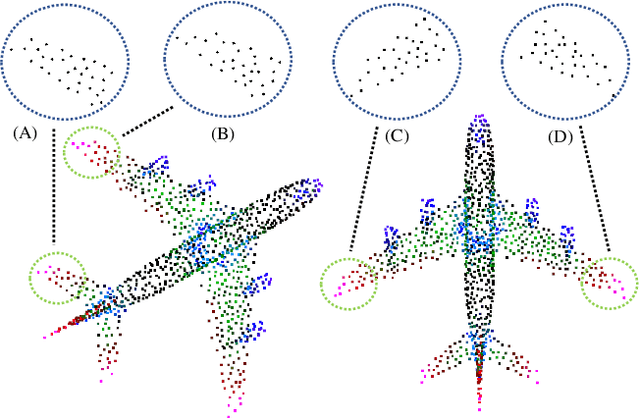
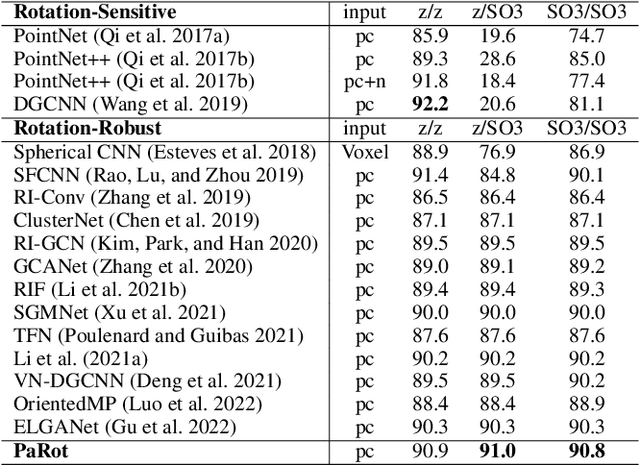
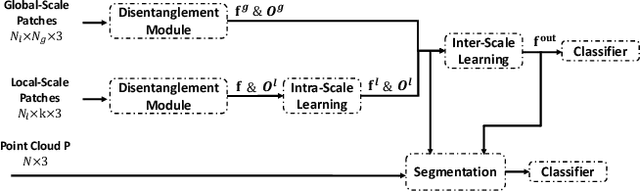
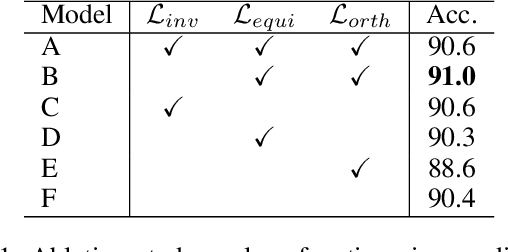
Recent interest in point cloud analysis has led rapid progress in designing deep learning methods for 3D models. However, state-of-the-art models are not robust to rotations, which remains an unknown prior to real applications and harms the model performance. In this work, we introduce a novel Patch-wise Rotation-invariant network (PaRot), which achieves rotation invariance via feature disentanglement and produces consistent predictions for samples with arbitrary rotations. Specifically, we design a siamese training module which disentangles rotation invariance and equivariance from patches defined over different scales, e.g., the local geometry and global shape, via a pair of rotations. However, our disentangled invariant feature loses the intrinsic pose information of each patch. To solve this problem, we propose a rotation-invariant geometric relation to restore the relative pose with equivariant information for patches defined over different scales. Utilising the pose information, we propose a hierarchical module which implements intra-scale and inter-scale feature aggregation for 3D shape learning. Moreover, we introduce a pose-aware feature propagation process with the rotation-invariant relative pose information embedded. Experiments show that our disentanglement module extracts high-quality rotation-robust features and the proposed lightweight model achieves competitive results in rotated 3D object classification and part segmentation tasks. Our project page is released at: https://patchrot.github.io/.
3D Medical Point Transformer: Introducing Convolution to Attention Networks for Medical Point Cloud Analysis
Dec 17, 2021


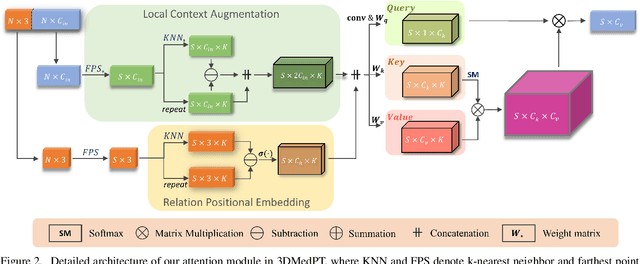
General point clouds have been increasingly investigated for different tasks, and recently Transformer-based networks are proposed for point cloud analysis. However, there are barely related works for medical point clouds, which are important for disease detection and treatment. In this work, we propose an attention-based model specifically for medical point clouds, namely 3D medical point Transformer (3DMedPT), to examine the complex biological structures. By augmenting contextual information and summarizing local responses at query, our attention module can capture both local context and global content feature interactions. However, the insufficient training samples of medical data may lead to poor feature learning, so we apply position embeddings to learn accurate local geometry and Multi-Graph Reasoning (MGR) to examine global knowledge propagation over channel graphs to enrich feature representations. Experiments conducted on IntrA dataset proves the superiority of 3DMedPT, where we achieve the best classification and segmentation results. Furthermore, the promising generalization ability of our method is validated on general 3D point cloud benchmarks: ModelNet40 and ShapeNetPart. Code is released.