 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgiATM: A Physics-Guided Plug-and-Play Model for Deep Learning-Based Smoke Removal in Laparoscopic Surgery
Nov 07, 2025During laparoscopic surgery, smoke generated by tissue cauterization can significantly degrade the visual quality of endoscopic frames, increasing the risk of surgical errors and hindering both clinical decision-making and computer-assisted visual analysis. Consequently, removing surgical smoke is critical to ensuring patient safety and maintaining operative efficiency. In this study, we propose the Surgical Atmospheric Model (SurgiATM) for surgical smoke removal. SurgiATM statistically bridges a physics-based atmospheric model and data-driven deep learning models, combining the superior generalizability of the former with the high accuracy of the latter. Furthermore, SurgiATM is designed as a lightweight, plug-and-play module that can be seamlessly integrated into diverse surgical desmoking architectures to enhance their accuracy and stability, better meeting clinical requirements. It introduces only two hyperparameters and no additional trainable weights, preserving the original network architecture with minimal computational and modification overhead. We conduct extensive experiments on three public surgical datasets with ten desmoking methods, involving multiple network architectures and covering diverse procedures, including cholecystectomy, partial nephrectomy, and diaphragm dissection. The results demonstrate that incorporating SurgiATM commonly reduces the restoration errors of existing models and relatively enhances their generalizability, without adding any trainable layers or weights. This highlights the convenience, low cost, effectiveness, and generalizability of the proposed method. The code for SurgiATM is released at https://github.com/MingyuShengSMY/SurgiATM.
ScSAM: Debiasing Morphology and Distributional Variability in Subcellular Semantic Segmentation
Jul 23, 2025The significant morphological and distributional variability among subcellular components poses a long-standing challenge for learning-based organelle segmentation models, significantly increasing the risk of biased feature learning. Existing methods often rely on single mapping relationships, overlooking feature diversity and thereby inducing biased training. Although the Segment Anything Model (SAM) provides rich feature representations, its application to subcellular scenarios is hindered by two key challenges: (1) The variability in subcellular morphology and distribution creates gaps in the label space, leading the model to learn spurious or biased features. (2) SAM focuses on global contextual understanding and often ignores fine-grained spatial details, making it challenging to capture subtle structural alterations and cope with skewed data distributions. To address these challenges, we introduce ScSAM, a method that enhances feature robustness by fusing pre-trained SAM with Masked Autoencoder (MAE)-guided cellular prior knowledge to alleviate training bias from data imbalance. Specifically, we design a feature alignment and fusion module to align pre-trained embeddings to the same feature space and efficiently combine different representations. Moreover, we present a cosine similarity matrix-based class prompt encoder to activate class-specific features to recognize subcellular categories. Extensive experiments on diverse subcellular image datasets demonstrate that ScSAM outperforms state-of-the-art methods.
A Multimodal Deep Learning Approach for White Matter Shape Prediction in Diffusion MRI Tractography
Apr 25, 2025Shape measures have emerged as promising descriptors of white matter tractography, offering complementary insights into anatomical variability and associations with cognitive and clinical phenotypes. However, conventional methods for computing shape measures are computationally expensive and time-consuming for large-scale datasets due to reliance on voxel-based representations. We propose Tract2Shape, a novel multimodal deep learning framework that leverages geometric (point cloud) and scalar (tabular) features to predict ten white matter tractography shape measures. To enhance model efficiency, we utilize a dimensionality reduction algorithm for the model to predict five primary shape components. The model is trained and evaluated on two independently acquired datasets, the HCP-YA dataset, and the PPMI dataset. We evaluate the performance of Tract2Shape by training and testing it on the HCP-YA dataset and comparing the results with state-of-the-art models. To further assess its robustness and generalization ability, we also test Tract2Shape on the unseen PPMI dataset. Tract2Shape outperforms SOTA deep learning models across all ten shape measures, achieving the highest average Pearson's r and the lowest nMSE on the HCP-YA dataset. The ablation study shows that both multimodal input and PCA contribute to performance gains. On the unseen testing PPMI dataset, Tract2Shape maintains a high Pearson's r and low nMSE, demonstrating strong generalizability in cross-dataset evaluation. Tract2Shape enables fast, accurate, and generalizable prediction of white matter shape measures from tractography data, supporting scalable analysis across datasets. This framework lays a promising foundation for future large-scale white matter shape analysis.
MultiCo3D: Multi-Label Voxel Contrast for One-Shot Incremental Segmentation of 3D Neuroimages
Mar 09, 20253D neuroimages provide a comprehensive view of brain structure and function, aiding in precise localization and functional connectivity analysis. Segmentation of white matter (WM) tracts using 3D neuroimages is vital for understanding the brain's structural connectivity in both healthy and diseased states. One-shot Class Incremental Semantic Segmentation (OCIS) refers to effectively segmenting new (novel) classes using only a single sample while retaining knowledge of old (base) classes without forgetting. Voxel-contrastive OCIS methods adjust the feature space to alleviate the feature overlap problem between the base and novel classes. However, since WM tract segmentation is a multi-label segmentation task, existing single-label voxel contrastive-based methods may cause inherent contradictions. To address this, we propose a new multi-label voxel contrast framework called MultiCo3D for one-shot class incremental tract segmentation. Our method utilizes uncertainty distillation to preserve base tract segmentation knowledge while adjusting the feature space with multi-label voxel contrast to alleviate feature overlap when learning novel tracts and dynamically weighting multi losses to balance overall loss. We compare our method against several state-of-the-art (SOTA) approaches. The experimental results show that our method significantly enhances one-shot class incremental tract segmentation accuracy across five different experimental setups on HCP and Preto datasets.
RealSyn: An Effective and Scalable Multimodal Interleaved Document Transformation Paradigm
Feb 18, 2025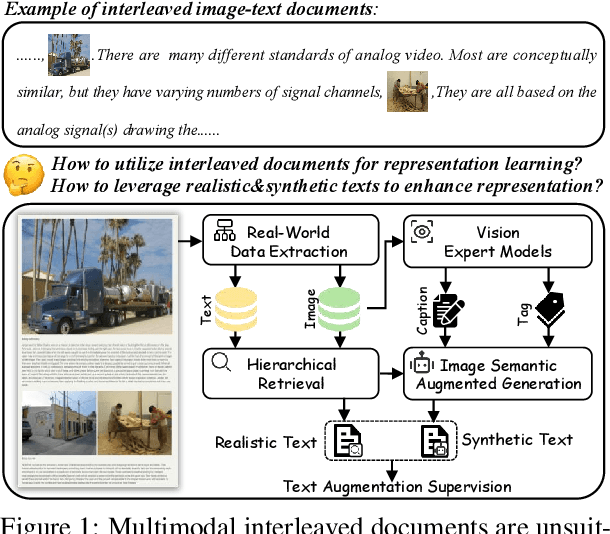
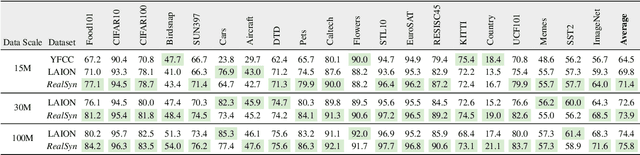


After pre-training on extensive image-text pairs, Contrastive Language-Image Pre-training (CLIP) demonstrates promising performance on a wide variety of benchmarks. However, a substantial volume of non-paired data, such as multimodal interleaved documents, remains underutilized for vision-language representation learning. To fully leverage these unpaired documents, we initially establish a Real-World Data Extraction pipeline to extract high-quality images and texts. Then we design a hierarchical retrieval method to efficiently associate each image with multiple semantically relevant realistic texts. To further enhance fine-grained visual information, we propose an image semantic augmented generation module for synthetic text production. Furthermore, we employ a semantic balance sampling strategy to improve dataset diversity, enabling better learning of long-tail concepts. Based on these innovations, we construct RealSyn, a dataset combining realistic and synthetic texts, available in three scales: 15M, 30M, and 100M. Extensive experiments demonstrate that RealSyn effectively advances vision-language representation learning and exhibits strong scalability. Models pre-trained on RealSyn achieve state-of-the-art performance on multiple downstream tasks. To facilitate future research, the RealSyn dataset and pre-trained model weights are released at https://github.com/deepglint/RealSyn.
Medical Image Registration Meets Vision Foundation Model: Prototype Learning and Contour Awareness
Feb 17, 2025Medical image registration is a fundamental task in medical image analysis, aiming to establish spatial correspondences between paired images. However, existing unsupervised deformable registration methods rely solely on intensity-based similarity metrics, lacking explicit anatomical knowledge, which limits their accuracy and robustness. Vision foundation models, such as the Segment Anything Model (SAM), can generate high-quality segmentation masks that provide explicit anatomical structure knowledge, addressing the limitations of traditional methods that depend only on intensity similarity. Based on this, we propose a novel SAM-assisted registration framework incorporating prototype learning and contour awareness. The framework includes: (1) Explicit anatomical information injection, where SAM-generated segmentation masks are used as auxiliary inputs throughout training and testing to ensure the consistency of anatomical information; (2) Prototype learning, which leverages segmentation masks to extract prototype features and aligns prototypes to optimize semantic correspondences between images; and (3) Contour-aware loss, a contour-aware loss is designed that leverages the edges of segmentation masks to improve the model's performance in fine-grained deformation fields. Extensive experiments demonstrate that the proposed framework significantly outperforms existing methods across multiple datasets, particularly in challenging scenarios with complex anatomical structures and ambiguous boundaries. Our code is available at https://github.com/HaoXu0507/IPMI25-SAM-Assisted-Registration.
Cross-View Consistency Regularisation for Knowledge Distillation
Dec 21, 2024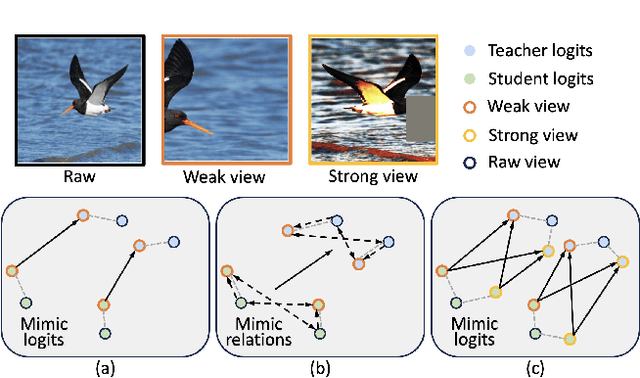
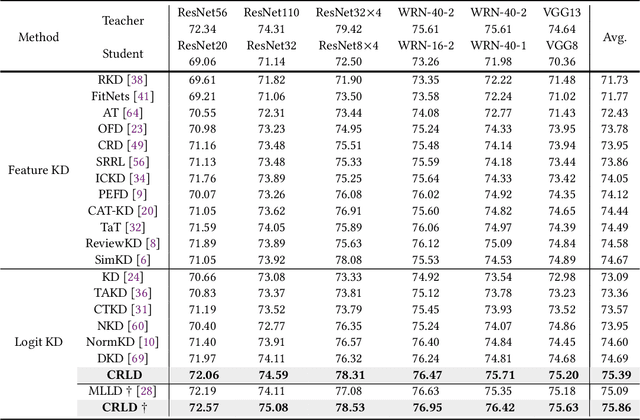
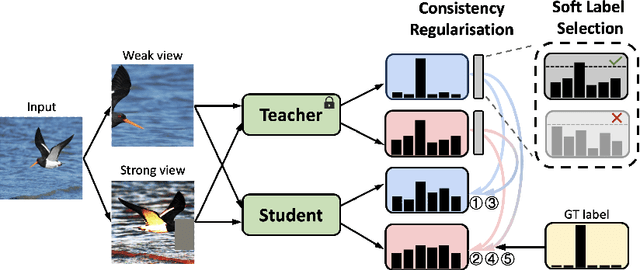
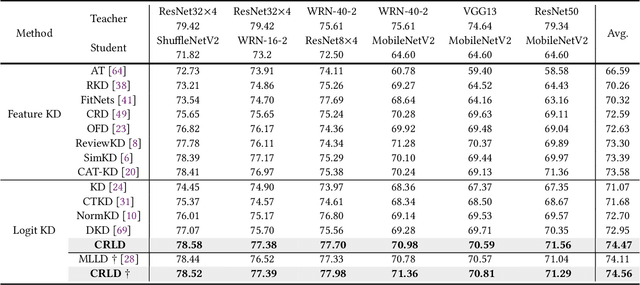
Knowledge distillation (KD) is an established paradigm for transferring privileged knowledge from a cumbersome model to a lightweight and efficient one. In recent years, logit-based KD methods are quickly catching up in performance with their feature-based counterparts. However, previous research has pointed out that logit-based methods are still fundamentally limited by two major issues in their training process, namely overconfident teacher and confirmation bias. Inspired by the success of cross-view learning in fields such as semi-supervised learning, in this work we introduce within-view and cross-view regularisations to standard logit-based distillation frameworks to combat the above cruxes. We also perform confidence-based soft label mining to improve the quality of distilling signals from the teacher, which further mitigates the confirmation bias problem. Despite its apparent simplicity, the proposed Consistency-Regularisation-based Logit Distillation (CRLD) significantly boosts student learning, setting new state-of-the-art results on the standard CIFAR-100, Tiny-ImageNet, and ImageNet datasets across a diversity of teacher and student architectures, whilst introducing no extra network parameters. Orthogonal to on-going logit-based distillation research, our method enjoys excellent generalisation properties and, without bells and whistles, boosts the performance of various existing approaches by considerable margins.
ORID: Organ-Regional Information Driven Framework for Radiology Report Generation
Nov 20, 2024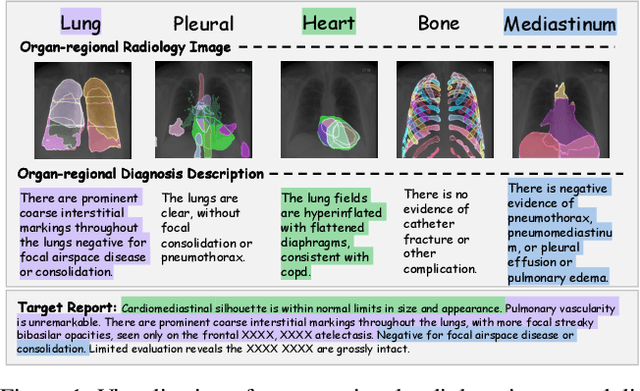
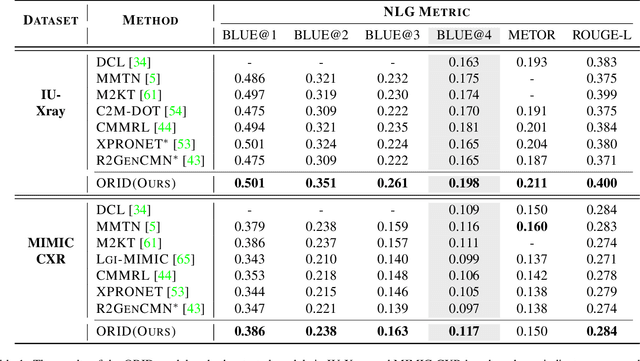
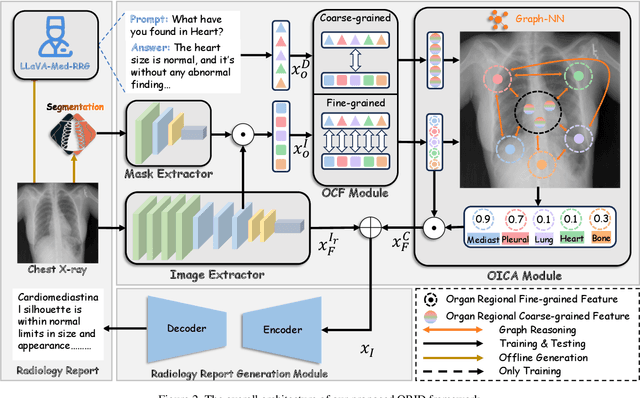
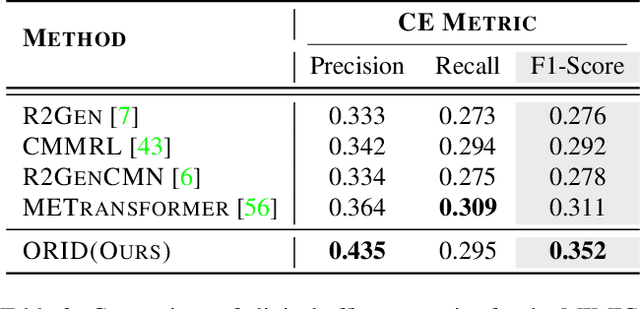
The objective of Radiology Report Generation (RRG) is to automatically generate coherent textual analyses of diseases based on radiological images, thereby alleviating the workload of radiologists. Current AI-based methods for RRG primarily focus on modifications to the encoder-decoder model architecture. To advance these approaches, this paper introduces an Organ-Regional Information Driven (ORID) framework which can effectively integrate multi-modal information and reduce the influence of noise from unrelated organs. Specifically, based on the LLaVA-Med, we first construct an RRG-related instruction dataset to improve organ-regional diagnosis description ability and get the LLaVA-Med-RRG. After that, we propose an organ-based cross-modal fusion module to effectively combine the information from the organ-regional diagnosis description and radiology image. To further reduce the influence of noise from unrelated organs on the radiology report generation, we introduce an organ importance coefficient analysis module, which leverages Graph Neural Network (GNN) to examine the interconnections of the cross-modal information of each organ region. Extensive experiments an1d comparisons with state-of-the-art methods across various evaluation metrics demonstrate the superior performance of our proposed method.
AMNCutter: Affinity-Attention-Guided Multi-View Normalized Cutter for Unsupervised Surgical Instrument Segmentation
Nov 07, 2024



Surgical instrument segmentation (SIS) is pivotal for robotic-assisted minimally invasive surgery, assisting surgeons by identifying surgical instruments in endoscopic video frames. Recent unsupervised surgical instrument segmentation (USIS) methods primarily rely on pseudo-labels derived from low-level features such as color and optical flow, but these methods show limited effectiveness and generalizability in complex and unseen endoscopic scenarios. In this work, we propose a label-free unsupervised model featuring a novel module named Multi-View Normalized Cutter (m-NCutter). Different from previous USIS works, our model is trained using a graph-cutting loss function that leverages patch affinities for supervision, eliminating the need for pseudo-labels. The framework adaptively determines which affinities from which levels should be prioritized. Therefore, the low- and high-level features and their affinities are effectively integrated to train a label-free unsupervised model, showing superior effectiveness and generalization ability. We conduct comprehensive experiments across multiple SIS datasets to validate our approach's state-of-the-art (SOTA) performance, robustness, and exceptional potential as a pre-trained model. Our code is released at https://github.com/MingyuShengSMY/AMNCutter.
TractShapeNet: Efficient Multi-Shape Learning with 3D Tractography Point Clouds
Oct 29, 2024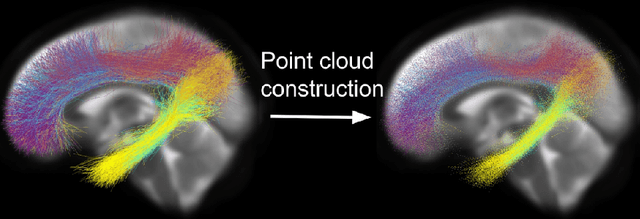
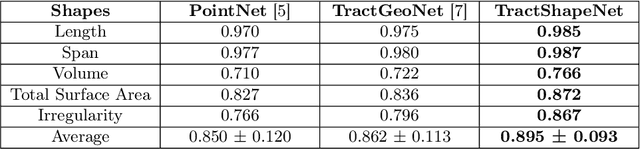

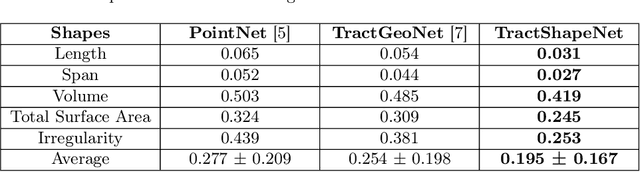
Brain imaging studies have demonstrated that diffusion MRI tractography geometric shape descriptors can inform the study of the brain's white matter pathways and their relationship to brain function. In this work, we investigate the possibility of utilizing a deep learning model to compute shape measures of the brain's white matter connections. We introduce a novel framework, TractShapeNet, that leverages a point cloud representation of tractography to compute five shape measures: length, span, volume, total surface area, and irregularity. We assess the performance of the method on a large dataset including 1065 healthy young adults. Experiments for shape measure computation demonstrate that our proposed TractShapeNet outperforms other point cloud-based neural network models in both the Pearson correlation coefficient and normalized error metrics. We compare the inference runtime results with the conventional shape computation tool DSI-Studio. Our results demonstrate that a deep learning approach enables faster and more efficient shape measure computation. We also conduct experiments on two downstream language cognition prediction tasks, showing that shape measures from TractShapeNet perform similarly to those computed by DSI-Studio. Our code will be available at: https://github.com/SlicerDMRI/TractShapeNet.