 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDanQing: An Up-to-Date Large-Scale Chinese Vision-Language Pre-training Dataset
Jan 15, 2026Vision-Language Pre-training (VLP) models demonstrate strong performance across various downstream tasks by learning from large-scale image-text pairs through contrastive pretraining. The release of extensive English image-text datasets (e.g., COYO-700M and LAION-400M) has enabled widespread adoption of models such as CLIP and SigLIP in tasks including cross-modal retrieval and image captioning. However, the advancement of Chinese vision-language pretraining has substantially lagged behind, due to the scarcity of high-quality Chinese image-text data. To address this gap, we develop a comprehensive pipeline for constructing a high-quality Chinese cross-modal dataset. As a result, we propose DanQing, which contains 100 million image-text pairs collected from Common Crawl. Different from existing datasets, DanQing is curated through a more rigorous selection process, yielding superior data quality. Moreover, DanQing is primarily built from 2024-2025 web data, enabling models to better capture evolving semantic trends and thus offering greater practical utility. We compare DanQing with existing datasets by continual pre-training of the SigLIP2 model. Experimental results show that DanQing consistently achieves superior performance across a range of Chinese downstream tasks, including zero-shot classification, cross-modal retrieval, and LMM-based evaluations. To facilitate further research in Chinese vision-language pre-training, we will open-source the DanQing dataset under the Creative Common CC-BY 4.0 license.
ProCLIP: Progressive Vision-Language Alignment via LLM-based Embedder
Oct 22, 2025The original CLIP text encoder is limited by a maximum input length of 77 tokens, which hampers its ability to effectively process long texts and perform fine-grained semantic understanding. In addition, the CLIP text encoder lacks support for multilingual inputs. All these limitations significantly restrict its applicability across a broader range of tasks. Recent studies have attempted to replace the CLIP text encoder with an LLM-based embedder to enhance its ability in processing long texts, multilingual understanding, and fine-grained semantic comprehension. However, because the representation spaces of LLMs and the vision-language space of CLIP are pretrained independently without alignment priors, direct alignment using contrastive learning can disrupt the intrinsic vision-language alignment in the CLIP image encoder, leading to an underutilization of the knowledge acquired during pre-training. To address this challenge, we propose ProCLIP, a curriculum learning-based progressive vision-language alignment framework to effectively align the CLIP image encoder with an LLM-based embedder. Specifically, ProCLIP first distills knowledge from CLIP's text encoder into the LLM-based embedder to leverage CLIP's rich pretrained knowledge while establishing initial alignment between the LLM embedder and CLIP image encoder. Subsequently, ProCLIP further aligns the CLIP image encoder with the LLM-based embedder through image-text contrastive tuning, employing self-distillation regularization to avoid overfitting. To achieve a more effective alignment, instance semantic alignment loss and embedding structure alignment loss are employed during representation inheritance and contrastive tuning. The Code is available at https://github.com/VisionXLab/ProCLIP.
Gradient-Attention Guided Dual-Masking Synergetic Framework for Robust Text-based Person Retrieval
Sep 11, 2025Although Contrastive Language-Image Pre-training (CLIP) exhibits strong performance across diverse vision tasks, its application to person representation learning faces two critical challenges: (i) the scarcity of large-scale annotated vision-language data focused on person-centric images, and (ii) the inherent limitations of global contrastive learning, which struggles to maintain discriminative local features crucial for fine-grained matching while remaining vulnerable to noisy text tokens. This work advances CLIP for person representation learning through synergistic improvements in data curation and model architecture. First, we develop a noise-resistant data construction pipeline that leverages the in-context learning capabilities of MLLMs to automatically filter and caption web-sourced images. This yields WebPerson, a large-scale dataset of 5M high-quality person-centric image-text pairs. Second, we introduce the GA-DMS (Gradient-Attention Guided Dual-Masking Synergetic) framework, which improves cross-modal alignment by adaptively masking noisy textual tokens based on the gradient-attention similarity score. Additionally, we incorporate masked token prediction objectives that compel the model to predict informative text tokens, enhancing fine-grained semantic representation learning. Extensive experiments show that GA-DMS achieves state-of-the-art performance across multiple benchmarks.
Region-based Cluster Discrimination for Visual Representation Learning
Jul 26, 2025Learning visual representations is foundational for a broad spectrum of downstream tasks. Although recent vision-language contrastive models, such as CLIP and SigLIP, have achieved impressive zero-shot performance via large-scale vision-language alignment, their reliance on global representations constrains their effectiveness for dense prediction tasks, such as grounding, OCR, and segmentation. To address this gap, we introduce Region-Aware Cluster Discrimination (RICE), a novel method that enhances region-level visual and OCR capabilities. We first construct a billion-scale candidate region dataset and propose a Region Transformer layer to extract rich regional semantics. We further design a unified region cluster discrimination loss that jointly supports object and OCR learning within a single classification framework, enabling efficient and scalable distributed training on large-scale data. Extensive experiments show that RICE consistently outperforms previous methods on tasks, including segmentation, dense detection, and visual perception for Multimodal Large Language Models (MLLMs). The pre-trained models have been released at https://github.com/deepglint/MVT.
RealSyn: An Effective and Scalable Multimodal Interleaved Document Transformation Paradigm
Feb 18, 2025
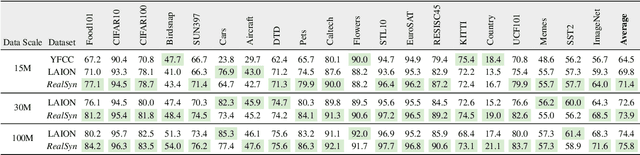


After pre-training on extensive image-text pairs, Contrastive Language-Image Pre-training (CLIP) demonstrates promising performance on a wide variety of benchmarks. However, a substantial volume of non-paired data, such as multimodal interleaved documents, remains underutilized for vision-language representation learning. To fully leverage these unpaired documents, we initially establish a Real-World Data Extraction pipeline to extract high-quality images and texts. Then we design a hierarchical retrieval method to efficiently associate each image with multiple semantically relevant realistic texts. To further enhance fine-grained visual information, we propose an image semantic augmented generation module for synthetic text production. Furthermore, we employ a semantic balance sampling strategy to improve dataset diversity, enabling better learning of long-tail concepts. Based on these innovations, we construct RealSyn, a dataset combining realistic and synthetic texts, available in three scales: 15M, 30M, and 100M. Extensive experiments demonstrate that RealSyn effectively advances vision-language representation learning and exhibits strong scalability. Models pre-trained on RealSyn achieve state-of-the-art performance on multiple downstream tasks. To facilitate future research, the RealSyn dataset and pre-trained model weights are released at https://github.com/deepglint/RealSyn.
ORID: Organ-Regional Information Driven Framework for Radiology Report Generation
Nov 20, 2024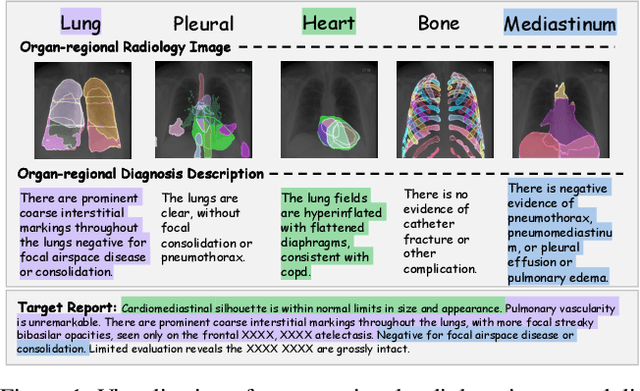
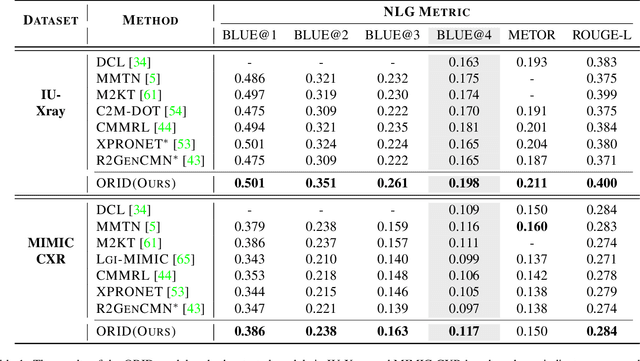
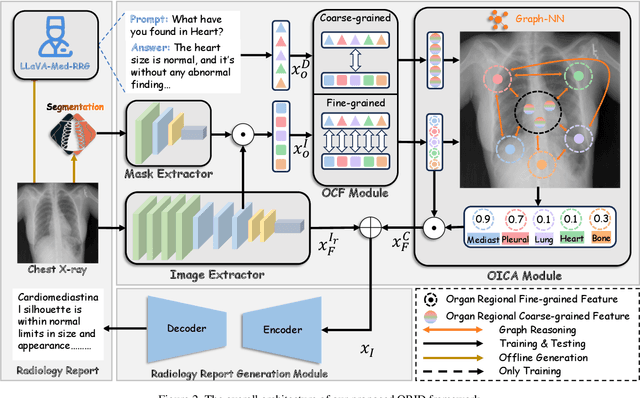
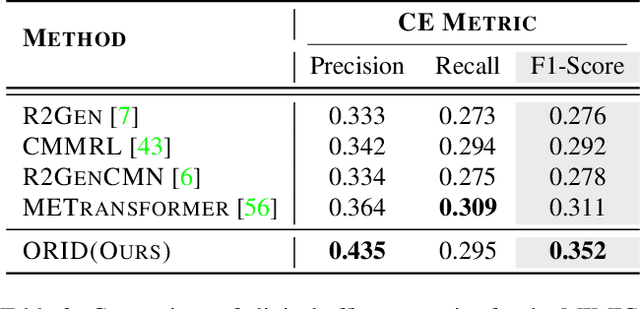
The objective of Radiology Report Generation (RRG) is to automatically generate coherent textual analyses of diseases based on radiological images, thereby alleviating the workload of radiologists. Current AI-based methods for RRG primarily focus on modifications to the encoder-decoder model architecture. To advance these approaches, this paper introduces an Organ-Regional Information Driven (ORID) framework which can effectively integrate multi-modal information and reduce the influence of noise from unrelated organs. Specifically, based on the LLaVA-Med, we first construct an RRG-related instruction dataset to improve organ-regional diagnosis description ability and get the LLaVA-Med-RRG. After that, we propose an organ-based cross-modal fusion module to effectively combine the information from the organ-regional diagnosis description and radiology image. To further reduce the influence of noise from unrelated organs on the radiology report generation, we introduce an organ importance coefficient analysis module, which leverages Graph Neural Network (GNN) to examine the interconnections of the cross-modal information of each organ region. Extensive experiments an1d comparisons with state-of-the-art methods across various evaluation metrics demonstrate the superior performance of our proposed method.
Croc: Pretraining Large Multimodal Models with Cross-Modal Comprehension
Oct 18, 2024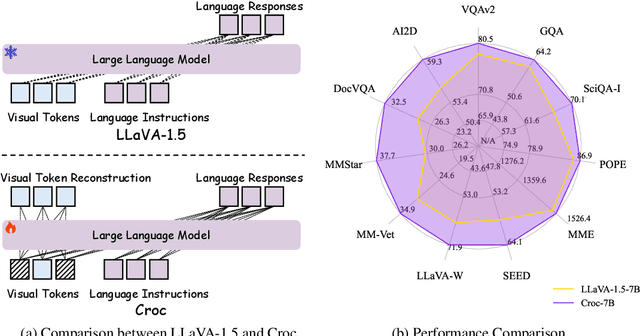
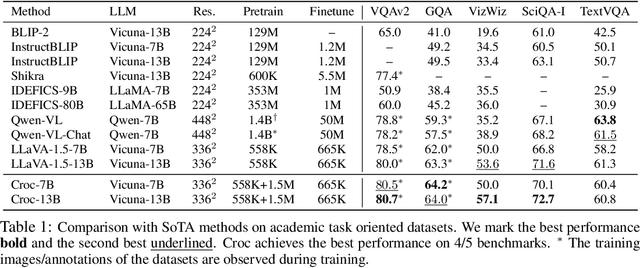
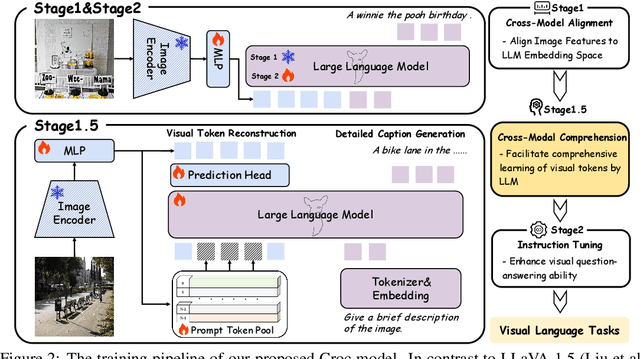
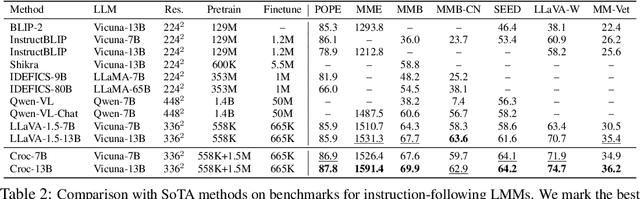
Recent advances in Large Language Models (LLMs) have catalyzed the development of Large Multimodal Models (LMMs). However, existing research primarily focuses on tuning language and image instructions, ignoring the critical pretraining phase where models learn to process textual and visual modalities jointly. In this paper, we propose a new pretraining paradigm for LMMs to enhance the visual comprehension capabilities of LLMs by introducing a novel cross-modal comprehension stage. Specifically, we design a dynamically learnable prompt token pool and employ the Hungarian algorithm to replace part of the original visual tokens with the most relevant prompt tokens. Then, we conceptualize visual tokens as analogous to a "foreign language" for the LLMs and propose a mixed attention mechanism with bidirectional visual attention and unidirectional textual attention to comprehensively enhance the understanding of visual tokens. Meanwhile, we integrate a detailed caption generation task, leveraging rich descriptions to further facilitate LLMs in understanding visual semantic information. After pretraining on 1.5 million publicly accessible data, we present a new foundation model called Croc. Experimental results demonstrate that Croc achieves new state-of-the-art performance on massive vision-language benchmarks. To support reproducibility and facilitate further research, we release the training code and pre-trained model weights at https://github.com/deepglint/Croc.
CLIP-CID: Efficient CLIP Distillation via Cluster-Instance Discrimination
Aug 18, 2024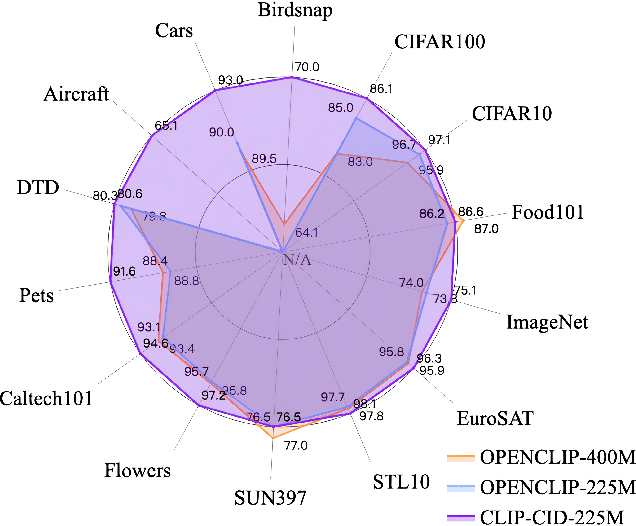
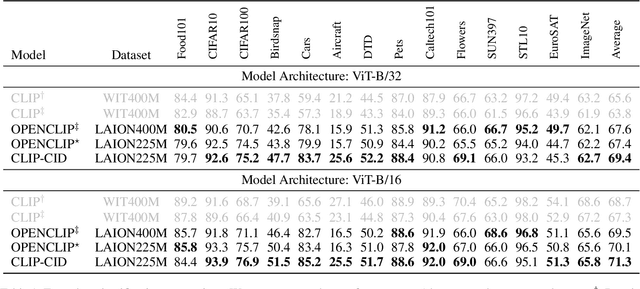
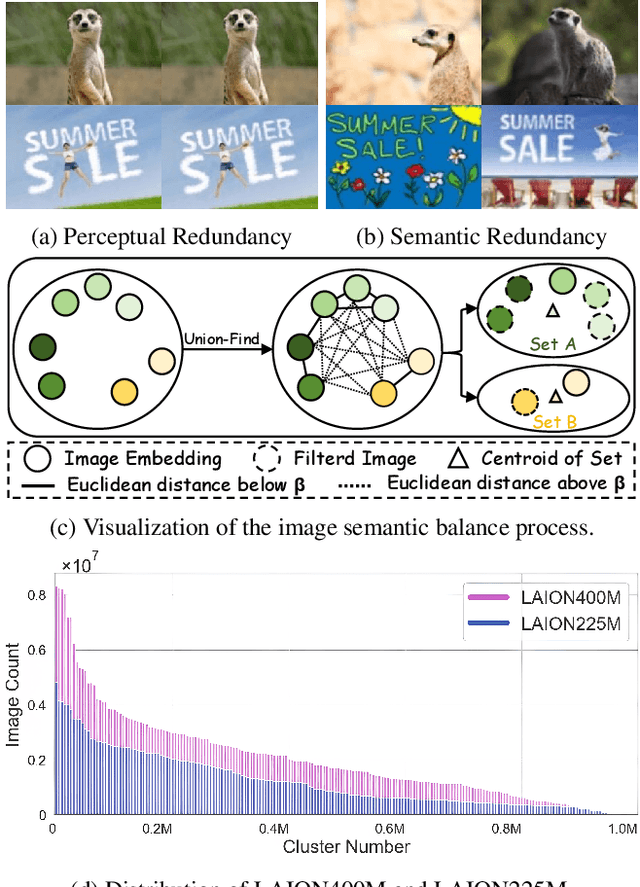
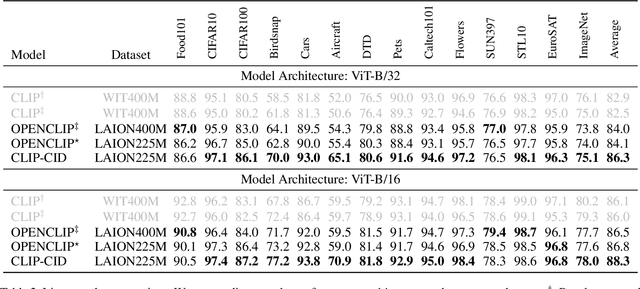
Contrastive Language-Image Pre-training (CLIP) has achieved excellent performance over a wide range of tasks. However, the effectiveness of CLIP heavily relies on a substantial corpus of pre-training data, resulting in notable consumption of computational resources. Although knowledge distillation has been widely applied in single modality models, how to efficiently expand knowledge distillation to vision-language foundation models with extensive data remains relatively unexplored. In this paper, we introduce CLIP-CID, a novel distillation mechanism that effectively transfers knowledge from a large vision-language foundation model to a smaller model. We initially propose a simple but efficient image semantic balance method to reduce transfer learning bias and improve distillation efficiency. This method filters out 43.7% of image-text pairs from the LAION400M while maintaining superior performance. After that, we leverage cluster-instance discrimination to facilitate knowledge transfer from the teacher model to the student model, thereby empowering the student model to acquire a holistic semantic comprehension of the pre-training data. Experimental results demonstrate that CLIP-CID achieves state-of-the-art performance on various downstream tasks including linear probe and zero-shot classification.
VAR-CLIP: Text-to-Image Generator with Visual Auto-Regressive Modeling
Aug 02, 2024



VAR is a new generation paradigm that employs 'next-scale prediction' as opposed to 'next-token prediction'. This innovative transformation enables auto-regressive (AR) transformers to rapidly learn visual distributions and achieve robust generalization. However, the original VAR model is constrained to class-conditioned synthesis, relying solely on textual captions for guidance. In this paper, we introduce VAR-CLIP, a novel text-to-image model that integrates Visual Auto-Regressive techniques with the capabilities of CLIP. The VAR-CLIP framework encodes captions into text embeddings, which are then utilized as textual conditions for image generation. To facilitate training on extensive datasets, such as ImageNet, we have constructed a substantial image-text dataset leveraging BLIP2. Furthermore, we delve into the significance of word positioning within CLIP for the purpose of caption guidance. Extensive experiments confirm VAR-CLIP's proficiency in generating fantasy images with high fidelity, textual congruence, and aesthetic excellence. Our project page are https://github.com/daixiangzi/VAR-CLIP
Multi-label Cluster Discrimination for Visual Representation Learning
Jul 24, 2024



Contrastive Language Image Pre-training (CLIP) has recently demonstrated success across various tasks due to superior feature representation empowered by image-text contrastive learning. However, the instance discrimination method used by CLIP can hardly encode the semantic structure of training data. To handle this limitation, cluster discrimination has been proposed through iterative cluster assignment and classification. Nevertheless, most cluster discrimination approaches only define a single pseudo-label for each image, neglecting multi-label signals in the image. In this paper, we propose a novel Multi-Label Cluster Discrimination method named MLCD to enhance representation learning. In the clustering step, we first cluster the large-scale LAION-400M dataset into one million centers based on off-the-shelf embedding features. Considering that natural images frequently contain multiple visual objects or attributes, we select the multiple closest centers as auxiliary class labels. In the discrimination step, we design a novel multi-label classification loss, which elegantly separates losses from positive classes and negative classes, and alleviates ambiguity on decision boundary. We validate the proposed multi-label cluster discrimination method with experiments on different scales of models and pre-training datasets. Experimental results show that our method achieves state-of-the-art performance on multiple downstream tasks including linear probe, zero-shot classification, and image-text retrieval.