 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerspectiveGap: A Benchmark for Multi-Agent Orchestration Prompting
Jun 07, 2026Real-world LLM applications are moving beyond single-agent workflows toward orchestrated multi-agent systems, yet current models still struggle to determine what each sub-agent needs to know. To measure this, we introduce PerspectiveGap, a benchmark for evaluating LLMs' ability to compose orchestration prompts for multi-agent systems. PerspectiveGap contains 110 scenarios, each evaluated through two distractor-mixed task formats: role-fragment assignment and free-form prompt writing. These scenarios are organized into 10 topologies, which are distilled from the authors' real-world engineering practice and framed by the Prompt Economy principle: building loop-centered orchestrations that maximize utility with minimal role and engineering overhead. In experiments with 27 commercial models from 10 companies, GPT-5.5 substantially outperforms all competitors, whereas Opus 4.7 shows a notable weakness in orchestration prompting despite its strong coding performance. Nevertheless, PerspectiveGap remains challenging: the evaluated models achieve an average combined pass rate of only 14.9\% (GPT-5.5 62.0\%) and an average overall leakage rate of 246.5\% (a per-scenario information leak-event count, not a proportion; GPT-5.5 49.1\%). These findings suggest that multi-agent orchestration prompting is a distinct and under-evaluated capability, and PerspectiveGap provides a foundation for measuring and improving it systematically.
Discovering Physical Directions in Weight Space: Composing Neural PDE Experts
May 14, 2026Recent advances in neural operators have made partial differential equation (PDE) surrogate modeling increasingly scalable and transferable through large-scale pretraining and in-context adaptation. However, after a shared operator is fine-tuned to multiple regimes within a continuous physical family, it remains unclear whether the resulting weight-space updates merely form isolated regime experts or reveal reusable physical structure. Starting from a shared family anchor, we fine-tune low- and high-regime endpoint experts and show that their updates can be separated into a family-shared adaptation and a direction aligned with the underlying physical parameter. This separation reinterprets endpoint experts as finite-difference probes of a local physical direction in weight space, explaining why static averaging can interpolate between regimes but attenuates endpoint-specific physics. Building on this perspective, we propose Calibration-Conditioned Merge (CCM), a post-hoc coordinate readout method for composing neural PDE experts along this physical direction. Given physical metadata, a calibrated coordinate mapping, or a short observed rollout prefix, CCM infers the target composition coordinate and deploys a single merged checkpoint for the remaining rollout. We evaluate CCM on the reaction--diffusion system, viscosity-parameterized two-dimensional Navier--Stokes equations, and radial dam-break dynamics. Across these benchmarks, CCM achieves its strongest gains in extrapolative regimes, reducing out-of-distribution rollout error relative to the family anchor by 54.2%, 42.8%, and 13.8%, respectively. Further experiments across FNO scales, a DPOT-style backbone, and ablations confirm that endpoint fine-tuning is not arbitrary checkpoint drift, but reveals a calibratable physical direction for training-free transfer across PDE regimes.
PDEAgent-Bench: A Multi-Metric, Multi-Library Benchmark for PDE Solver Generation
May 10, 2026PDE-to-solver code generation aims to automatically synthesize executable numerical solvers from partial differential equation (PDE) specifications. This task requires not only understanding the mathematical structure of PDEs, but also selecting appropriate discretization schemes and solver configurations, and correctly implementing the resulting formulations in finite-element method (FEM) libraries. Existing code generation benchmarks mainly evaluate syntactic correctness, or success on predefined test cases. To our knowledge, there is currently no publicly available benchmark specifically for PDE-to-solver code generation, and general-purpose code benchmarks do not fully capture the unique challenges of numerical PDE solution, such as ensuring solver accuracy, efficiency, and compatibility with professional FEM libraries. We introduce PDEAgent-Bench, to the best of our knowledge, the first multi-metric, multi-library benchmark for PDE-to-solver code generation. PDEAgent-Bench contains 645 instances across 6 mathematical categories and 11 PDE families, with common FEM libraries for DOLFINx, Firedrake, and deal.II. Each instance provides an agent-facing problem specification, a reference solution on a prescribed evaluation grid, and case-specific accuracy and runtime targets. PDEAgent-Bench adopts a staged evaluation framework in which generated solvers must sequentially pass executability, numerical accuracy, and computational efficiency checks. Experiments with representative LLMs and code agents show that models can often produce runnable code, but their pass rate drops substantially once accuracy and efficiency requirements are enforced. These results indicate that current agents remain limited in producing numerically reliable and efficient PDE solvers, and that PDEAgent-Bench provides a reproducible testbed grounded in the practical requirements of numerical PDE solving.
Correcting Mean Bias in Text Embeddings: A Refined Renormalization with Training-Free Improvements on MMTEB
Nov 14, 2025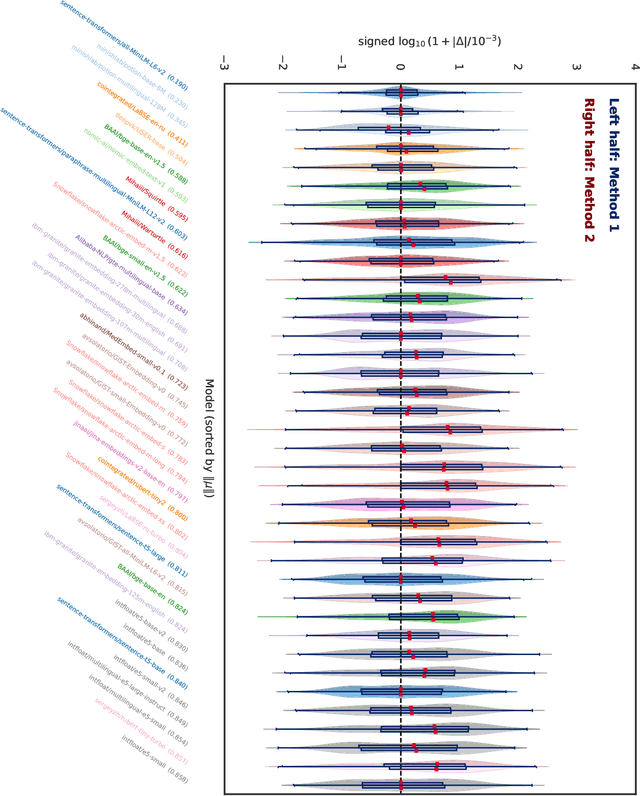
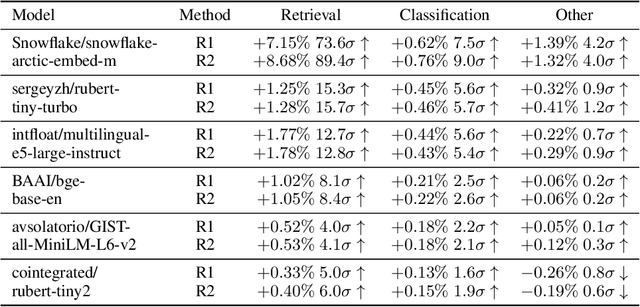
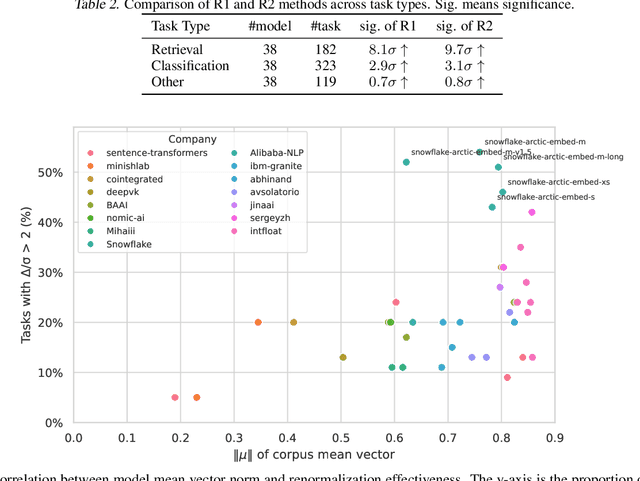
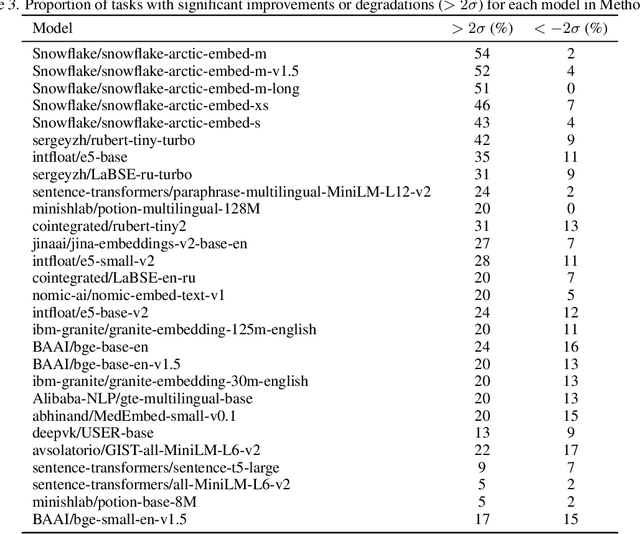
We find that current text embedding models produce outputs with a consistent bias, i.e., each embedding vector $e$ can be decomposed as $\tilde{e} + μ$, where $μ$ is almost identical across all sentences. We propose a plug-and-play, training-free and lightweight solution called Renormalization. Through extensive experiments, we show that renormalization consistently and statistically significantly improves the performance of existing models on the Massive Multilingual Text Embedding Benchmark (MMTEB). In particular, across 38 models, renormalization improves performance by 9.7 $σ$ on retrieval tasks, 3.1 $σ$ on classification tasks, and 0.8 $σ$ on other types of tasks. Renormalization has two variants: directly subtracting $μ$ from $e$, or subtracting the projection of $e$ onto $μ$. We theoretically predict that the latter performs better, and our experiments confirm this prediction.
MoRE: 3D Visual Geometry Reconstruction Meets Mixture-of-Experts
Oct 31, 2025Recent advances in language and vision have demonstrated that scaling up model capacity consistently improves performance across diverse tasks. In 3D visual geometry reconstruction, large-scale training has likewise proven effective for learning versatile representations. However, further scaling of 3D models is challenging due to the complexity of geometric supervision and the diversity of 3D data. To overcome these limitations, we propose MoRE, a dense 3D visual foundation model based on a Mixture-of-Experts (MoE) architecture that dynamically routes features to task-specific experts, allowing them to specialize in complementary data aspects and enhance both scalability and adaptability. Aiming to improve robustness under real-world conditions, MoRE incorporates a confidence-based depth refinement module that stabilizes and refines geometric estimation. In addition, it integrates dense semantic features with globally aligned 3D backbone representations for high-fidelity surface normal prediction. MoRE is further optimized with tailored loss functions to ensure robust learning across diverse inputs and multiple geometric tasks. Extensive experiments demonstrate that MoRE achieves state-of-the-art performance across multiple benchmarks and supports effective downstream applications without extra computation.
Multimodal Latent Diffusion Model for Complex Sewing Pattern Generation
Dec 19, 2024



Generating sewing patterns in garment design is receiving increasing attention due to its CG-friendly and flexible-editing nature. Previous sewing pattern generation methods have been able to produce exquisite clothing, but struggle to design complex garments with detailed control. To address these issues, we propose SewingLDM, a multi-modal generative model that generates sewing patterns controlled by text prompts, body shapes, and garment sketches. Initially, we extend the original vector of sewing patterns into a more comprehensive representation to cover more intricate details and then compress them into a compact latent space. To learn the sewing pattern distribution in the latent space, we design a two-step training strategy to inject the multi-modal conditions, \ie, body shapes, text prompts, and garment sketches, into a diffusion model, ensuring the generated garments are body-suited and detail-controlled. Comprehensive qualitative and quantitative experiments show the effectiveness of our proposed method, significantly surpassing previous approaches in terms of complex garment design and various body adaptability. Our project page: https://shengqiliu1.github.io/SewingLDM.
VAR-CLIP: Text-to-Image Generator with Visual Auto-Regressive Modeling
Aug 02, 2024



VAR is a new generation paradigm that employs 'next-scale prediction' as opposed to 'next-token prediction'. This innovative transformation enables auto-regressive (AR) transformers to rapidly learn visual distributions and achieve robust generalization. However, the original VAR model is constrained to class-conditioned synthesis, relying solely on textual captions for guidance. In this paper, we introduce VAR-CLIP, a novel text-to-image model that integrates Visual Auto-Regressive techniques with the capabilities of CLIP. The VAR-CLIP framework encodes captions into text embeddings, which are then utilized as textual conditions for image generation. To facilitate training on extensive datasets, such as ImageNet, we have constructed a substantial image-text dataset leveraging BLIP2. Furthermore, we delve into the significance of word positioning within CLIP for the purpose of caption guidance. Extensive experiments confirm VAR-CLIP's proficiency in generating fantasy images with high fidelity, textual congruence, and aesthetic excellence. Our project page are https://github.com/daixiangzi/VAR-CLIP
PAPM: A Physics-aware Proxy Model for Process Systems
Jul 07, 2024



In the context of proxy modeling for process systems, traditional data-driven deep learning approaches frequently encounter significant challenges, such as substantial training costs induced by large amounts of data, and limited generalization capabilities. As a promising alternative, physics-aware models incorporate partial physics knowledge to ameliorate these challenges. Although demonstrating efficacy, they fall short in terms of exploration depth and universality. To address these shortcomings, we introduce a physics-aware proxy model (PAPM) that fully incorporates partial prior physics of process systems, which includes multiple input conditions and the general form of conservation relations, resulting in better out-of-sample generalization. Additionally, PAPM contains a holistic temporal-spatial stepping module for flexible adaptation across various process systems. Through systematic comparisons with state-of-the-art pure data-driven and physics-aware models across five two-dimensional benchmarks in nine generalization tasks, PAPM notably achieves an average performance improvement of 6.7%, while requiring fewer FLOPs, and just 1% of the parameters compared to the prior leading method. The code is available at https://github.com/pengwei07/PAPM.
High-Fidelity Facial Albedo Estimation via Texture Quantization
Jun 19, 2024



Recent 3D face reconstruction methods have made significant progress in shape estimation, but high-fidelity facial albedo reconstruction remains challenging. Existing methods depend on expensive light-stage captured data to learn facial albedo maps. However, a lack of diversity in subjects limits their ability to recover high-fidelity results. In this paper, we present a novel facial albedo reconstruction model, HiFiAlbedo, which recovers the albedo map directly from a single image without the need for captured albedo data. Our key insight is that the albedo map is the illumination invariant texture map, which enables us to use inexpensive texture data to derive an albedo estimation by eliminating illumination. To achieve this, we first collect large-scale ultra-high-resolution facial images and train a high-fidelity facial texture codebook. By using the FFHQ dataset and limited UV textures, we then fine-tune the encoder for texture reconstruction from the input image with adversarial supervision in both image and UV space. Finally, we train a cross-attention module and utilize group identity loss to learn the adaptation from facial texture to the albedo domain. Extensive experimentation has demonstrated that our method exhibits excellent generalizability and is capable of achieving high-fidelity results for in-the-wild facial albedo recovery. Our code, pre-trained weights, and training data will be made publicly available at https://hifialbedo.github.io/.
Monocular Identity-Conditioned Facial Reflectance Reconstruction
Mar 30, 2024Recent 3D face reconstruction methods have made remarkable advancements, yet there remain huge challenges in monocular high-quality facial reflectance reconstruction. Existing methods rely on a large amount of light-stage captured data to learn facial reflectance models. However, the lack of subject diversity poses challenges in achieving good generalization and widespread applicability. In this paper, we learn the reflectance prior in image space rather than UV space and present a framework named ID2Reflectance. Our framework can directly estimate the reflectance maps of a single image while using limited reflectance data for training. Our key insight is that reflectance data shares facial structures with RGB faces, which enables obtaining expressive facial prior from inexpensive RGB data thus reducing the dependency on reflectance data. We first learn a high-quality prior for facial reflectance. Specifically, we pretrain multi-domain facial feature codebooks and design a codebook fusion method to align the reflectance and RGB domains. Then, we propose an identity-conditioned swapping module that injects facial identity from the target image into the pre-trained autoencoder to modify the identity of the source reflectance image. Finally, we stitch multi-view swapped reflectance images to obtain renderable assets. Extensive experiments demonstrate that our method exhibits excellent generalization capability and achieves state-of-the-art facial reflectance reconstruction results for in-the-wild faces. Our project page is https://xingyuren.github.io/id2reflectance/.