 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFitMe: Deep Photorealistic 3D Morphable Model Avatars
May 16, 2023



In this paper, we introduce FitMe, a facial reflectance model and a differentiable rendering optimization pipeline, that can be used to acquire high-fidelity renderable human avatars from single or multiple images. The model consists of a multi-modal style-based generator, that captures facial appearance in terms of diffuse and specular reflectance, and a PCA-based shape model. We employ a fast differentiable rendering process that can be used in an optimization pipeline, while also achieving photorealistic facial shading. Our optimization process accurately captures both the facial reflectance and shape in high-detail, by exploiting the expressivity of the style-based latent representation and of our shape model. FitMe achieves state-of-the-art reflectance acquisition and identity preservation on single "in-the-wild" facial images, while it produces impressive scan-like results, when given multiple unconstrained facial images pertaining to the same identity. In contrast with recent implicit avatar reconstructions, FitMe requires only one minute and produces relightable mesh and texture-based avatars, that can be used by end-user applications.
Efficient Hair Style Transfer with Generative Adversarial Networks
Oct 22, 2022Despite the recent success of image generation and style transfer with Generative Adversarial Networks (GANs), hair synthesis and style transfer remain challenging due to the shape and style variability of human hair in in-the-wild conditions. The current state-of-the-art hair synthesis approaches struggle to maintain global composition of the target style and cannot be used in real-time applications due to their high running costs on high-resolution portrait images. Therefore, We propose a novel hairstyle transfer method, called EHGAN, which reduces computational costs to enable real-time processing while improving the transfer of hairstyle with better global structure compared to the other state-of-the-art hair synthesis methods. To achieve this goal, we train an encoder and a low-resolution generator to transfer hairstyle and then, increase the resolution of results with a pre-trained super-resolution model. We utilize Adaptive Instance Normalization (AdaIN) and design our novel Hair Blending Block (HBB) to obtain the best performance of the generator. EHGAN needs around 2.7 times and over 10,000 times less time consumption than the state-of-the-art MichiGAN and LOHO methods respectively while obtaining better photorealism and structural similarity to the desired style than its competitors.
3DMM-RF: Convolutional Radiance Fields for 3D Face Modeling
Sep 15, 2022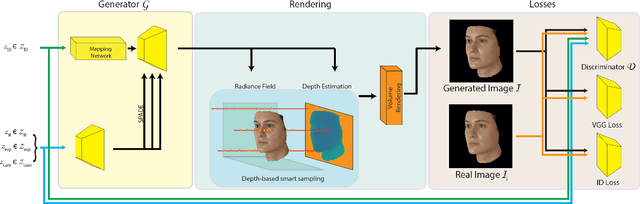
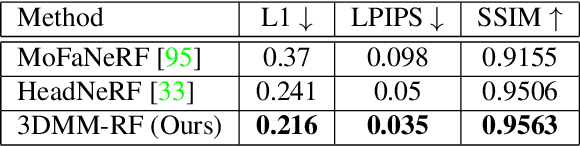


Facial 3D Morphable Models are a main computer vision subject with countless applications and have been highly optimized in the last two decades. The tremendous improvements of deep generative networks have created various possibilities for improving such models and have attracted wide interest. Moreover, the recent advances in neural radiance fields, are revolutionising novel-view synthesis of known scenes. In this work, we present a facial 3D Morphable Model, which exploits both of the above, and can accurately model a subject's identity, pose and expression and render it in arbitrary illumination. This is achieved by utilizing a powerful deep style-based generator to overcome two main weaknesses of neural radiance fields, their rigidity and rendering speed. We introduce a style-based generative network that synthesizes in one pass all and only the required rendering samples of a neural radiance field. We create a vast labelled synthetic dataset of facial renders, and train the network on these data, so that it can accurately model and generalize on facial identity, pose and appearance. Finally, we show that this model can accurately be fit to "in-the-wild" facial images of arbitrary pose and illumination, extract the facial characteristics, and be used to re-render the face in controllable conditions.
Facial Geometric Detail Recovery via Implicit Representation
Mar 18, 2022
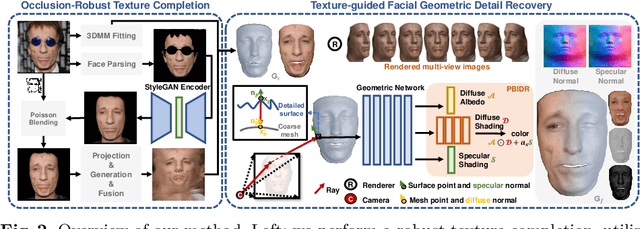


Learning a dense 3D model with fine-scale details from a single facial image is highly challenging and ill-posed. To address this problem, many approaches fit smooth geometries through facial prior while learning details as additional displacement maps or personalized basis. However, these techniques typically require vast datasets of paired multi-view data or 3D scans, whereas such datasets are scarce and expensive. To alleviate heavy data dependency, we present a robust texture-guided geometric detail recovery approach using only a single in-the-wild facial image. More specifically, our method combines high-quality texture completion with the powerful expressiveness of implicit surfaces. Initially, we inpaint occluded facial parts, generate complete textures, and build an accurate multi-view dataset of the same subject. In order to estimate the detailed geometry, we define an implicit signed distance function and employ a physically-based implicit renderer to reconstruct fine geometric details from the generated multi-view images. Our method not only recovers accurate facial details but also decomposes normals, albedos, and shading parts in a self-supervised way. Finally, we register the implicit shape details to a 3D Morphable Model template, which can be used in traditional modeling and rendering pipelines. Extensive experiments demonstrate that the proposed approach can reconstruct impressive facial details from a single image, especially when compared with state-of-the-art methods trained on large datasets.
AvatarMe++: Facial Shape and BRDF Inference with Photorealistic Rendering-Aware GANs
Dec 11, 2021
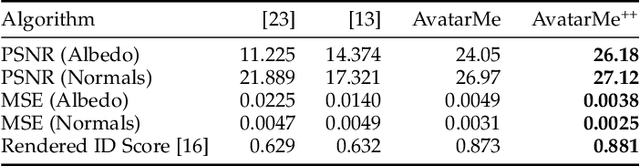


Over the last years, many face analysis tasks have accomplished astounding performance, with applications including face generation and 3D face reconstruction from a single "in-the-wild" image. Nevertheless, to the best of our knowledge, there is no method which can produce render-ready high-resolution 3D faces from "in-the-wild" images and this can be attributed to the: (a) scarcity of available data for training, and (b) lack of robust methodologies that can successfully be applied on very high-resolution data. In this work, we introduce the first method that is able to reconstruct photorealistic render-ready 3D facial geometry and BRDF from a single "in-the-wild" image. We capture a large dataset of facial shape and reflectance, which we have made public. We define a fast facial photorealistic differentiable rendering methodology with accurate facial skin diffuse and specular reflection, self-occlusion and subsurface scattering approximation. With this, we train a network that disentangles the facial diffuse and specular BRDF components from a shape and texture with baked illumination, reconstructed with a state-of-the-art 3DMM fitting method. Our method outperforms the existing arts by a significant margin and reconstructs high-resolution 3D faces from a single low-resolution image, that can be rendered in various applications, and bridge the uncanny valley.
Fast-GANFIT: Generative Adversarial Network for High Fidelity 3D Face Reconstruction
May 16, 2021
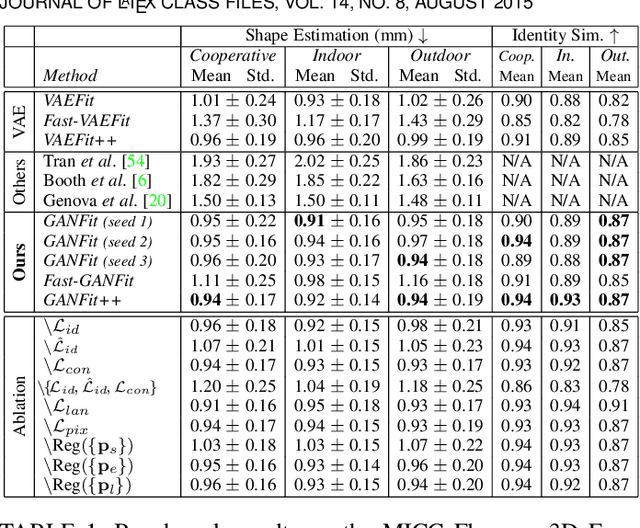
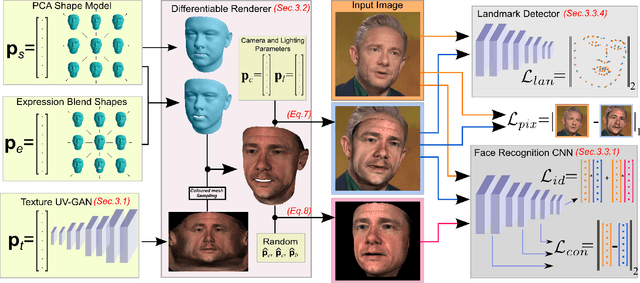
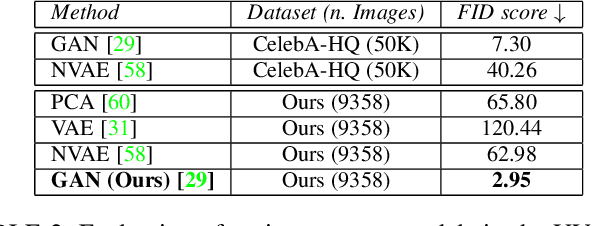
A lot of work has been done towards reconstructing the 3D facial structure from single images by capitalizing on the power of Deep Convolutional Neural Networks (DCNNs). In the recent works, the texture features either correspond to components of a linear texture space or are learned by auto-encoders directly from in-the-wild images. In all cases, the quality of the facial texture reconstruction is still not capable of modeling facial texture with high-frequency details. In this paper, we take a radically different approach and harness the power of Generative Adversarial Networks (GANs) and DCNNs in order to reconstruct the facial texture and shape from single images. That is, we utilize GANs to train a very powerful facial texture prior \edit{from a large-scale 3D texture dataset}. Then, we revisit the original 3D Morphable Models (3DMMs) fitting making use of non-linear optimization to find the optimal latent parameters that best reconstruct the test image but under a new perspective. In order to be robust towards initialisation and expedite the fitting process, we propose a novel self-supervised regression based approach. We demonstrate excellent results in photorealistic and identity preserving 3D face reconstructions and achieve for the first time, to the best of our knowledge, facial texture reconstruction with high-frequency details.
OSTeC: One-Shot Texture Completion
Dec 30, 2020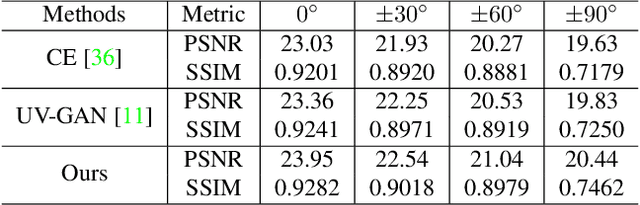

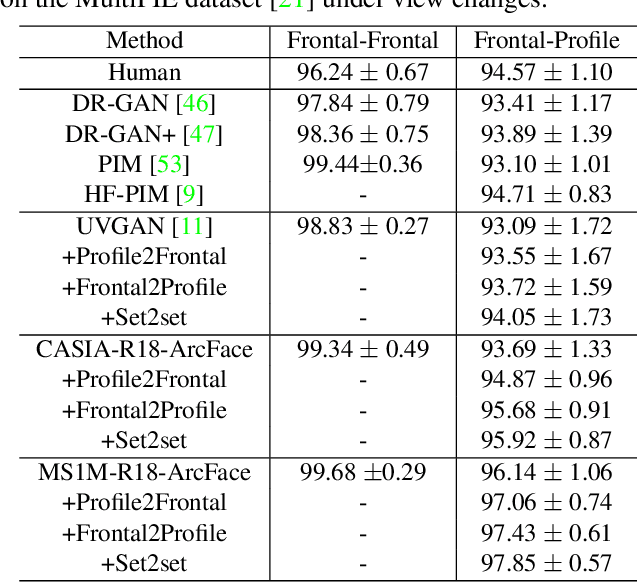

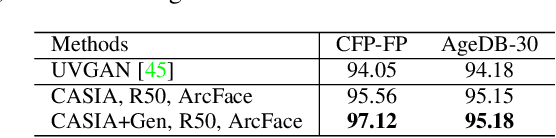
The last few years have witnessed the great success of non-linear generative models in synthesizing high-quality photorealistic face images. Many recent 3D facial texture reconstruction and pose manipulation from a single image approaches still rely on large and clean face datasets to train image-to-image Generative Adversarial Networks (GANs). Yet the collection of such a large scale high-resolution 3D texture dataset is still very costly and difficult to maintain age/ethnicity balance. Moreover, regression-based approaches suffer from generalization to the in-the-wild conditions and are unable to fine-tune to a target-image. In this work, we propose an unsupervised approach for one-shot 3D facial texture completion that does not require large-scale texture datasets, but rather harnesses the knowledge stored in 2D face generators. The proposed approach rotates an input image in 3D and fill-in the unseen regions by reconstructing the rotated image in a 2D face generator, based on the visible parts. Finally, we stitch the most visible textures at different angles in the UV image-plane. Further, we frontalize the target image by projecting the completed texture into the generator. The qualitative and quantitative experiments demonstrate that the completed UV textures and frontalized images are of high quality, resembles the original identity, can be used to train a texture GAN model for 3DMM fitting and improve pose-invariant face recognition.
AvatarMe: Realistically Renderable 3D Facial Reconstruction "in-the-wild"
Mar 30, 2020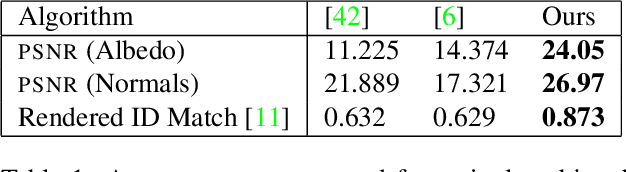


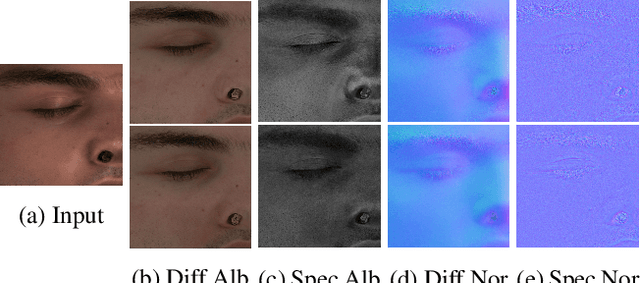
Over the last years, with the advent of Generative Adversarial Networks (GANs), many face analysis tasks have accomplished astounding performance, with applications including, but not limited to, face generation and 3D face reconstruction from a single "in-the-wild" image. Nevertheless, to the best of our knowledge, there is no method which can produce high-resolution photorealistic 3D faces from "in-the-wild" images and this can be attributed to the: (a) scarcity of available data for training, and (b) lack of robust methodologies that can successfully be applied on very high-resolution data. In this paper, we introduce AvatarMe, the first method that is able to reconstruct photorealistic 3D faces from a single "in-the-wild" image with an increasing level of detail. To achieve this, we capture a large dataset of facial shape and reflectance and build on a state-of-the-art 3D texture and shape reconstruction method and successively refine its results, while generating the per-pixel diffuse and specular components that are required for realistic rendering. As we demonstrate in a series of qualitative and quantitative experiments, AvatarMe outperforms the existing arts by a significant margin and reconstructs authentic, 4K by 6K-resolution 3D faces from a single low-resolution image that, for the first time, bridges the uncanny valley.
Towards a complete 3D morphable model of the human head
Nov 18, 2019
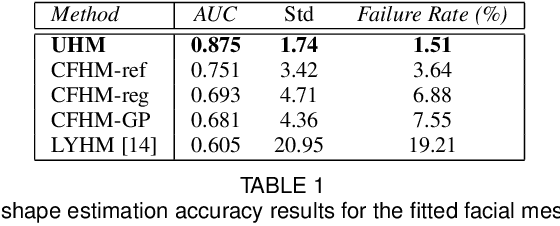
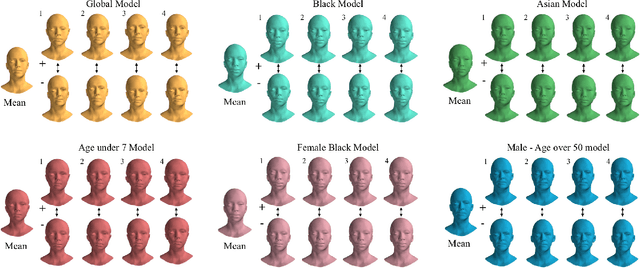
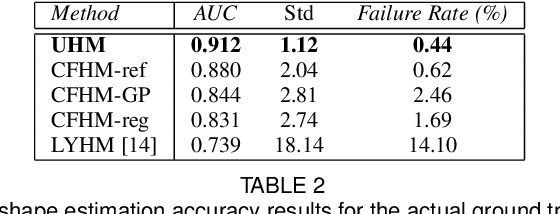
Three-dimensional Morphable Models (3DMMs) are powerful statistical tools for representing the 3D shapes and textures of an object class. Here we present the most complete 3DMM of the human head to date that includes face, cranium, ears, eyes, teeth and tongue. To achieve this, we propose two methods for combining existing 3DMMs of different overlapping head parts: i. use a regressor to complete missing parts of one model using the other, ii. use the Gaussian Process framework to blend covariance matrices from multiple models. Thus we build a new combined face-and-head shape model that blends the variability and facial detail of an existing face model (the LSFM) with the full head modelling capability of an existing head model (the LYHM). Then we construct and fuse a highly-detailed ear model to extend the variation of the ear shape. Eye and eye region models are incorporated into the head model, along with basic models of the teeth, tongue and inner mouth cavity. The new model achieves state-of-the-art performance. We use our model to reconstruct full head representations from single, unconstrained images allowing us to parameterize craniofacial shape and texture, along with the ear shape, eye gaze and eye color.
Synthesizing Coupled 3D Face Modalities by Trunk-Branch Generative Adversarial Networks
Sep 05, 2019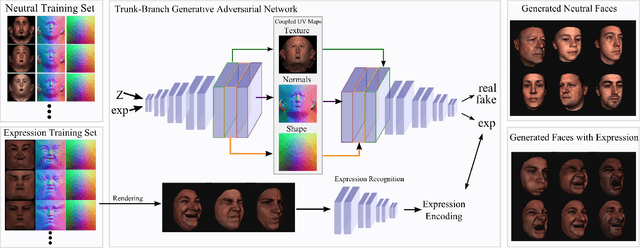


Generating realistic 3D faces is of high importance for computer graphics and computer vision applications. Generally, research on 3D face generation revolves around linear statistical models of the facial surface. Nevertheless, these models cannot represent faithfully either the facial texture or the normals of the face, which are very crucial for photo-realistic face synthesis. Recently, it was demonstrated that Generative Adversarial Networks (GANs) can be used for generating high-quality textures of faces. Nevertheless, the generation process either omits the geometry and normals, or independent processes are used to produce 3D shape information. In this paper, we present the first methodology that generates high-quality texture, shape, and normals jointly, which can be used for photo-realistic synthesis. To do so, we propose a novel GAN that can generate data from different modalities while exploiting their correlations. Furthermore, we demonstrate how we can condition the generation on the expression and create faces with various facial expressions. The qualitative results shown in this pre-print is compressed due to size limitations, full resolution results and the accompanying video can be found at the project page: https://github.com/barisgecer/TBGAN.