 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDermaFlux: Synthetic Skin Lesion Generation with Rectified Flows for Enhanced Image Classification
Mar 17, 2026Despite recent advances in deep generative modeling, skin lesion classification systems remain constrained by the limited availability of large, diverse, and well-annotated clinical datasets, resulting in class imbalance between benign and malignant lesions and consequently reduced generalization performance. We introduce DermaFlux, a rectified flow-based text-to-image generative framework that synthesizes clinically grounded skin lesion images from natural language descriptions of dermatological attributes. Built upon Flux.1, DermaFlux is fine-tuned using parameter-efficient Low-Rank Adaptation (LoRA) on a large curated collection of publicly available clinical image datasets. We construct image-text pairs using synthetic textual captions generated by Llama 3.2, following established dermatological criteria including lesion asymmetry, border irregularity, and color variation. Extensive experiments demonstrate that DermaFlux generates diverse and clinically meaningful dermatology images that improve binary classification performance by up to 6% when augmenting small real-world datasets, and by up to 9% when classifiers are trained on DermaFlux-generated synthetic images rather than diffusion-based synthetic images. Our ImageNet-pretrained ViT fine-tuned with only 2,500 real images and 4,375 DermaFlux-generated samples achieves 78.04% binary classification accuracy and an AUC of 0.859, surpassing the next best dermatology model by 8%.
STARCaster: Spatio-Temporal AutoRegressive Video Diffusion for Identity- and View-Aware Talking Portraits
Dec 15, 2025


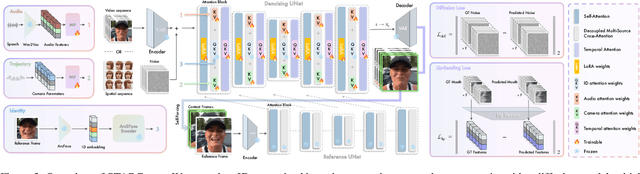
This paper presents STARCaster, an identity-aware spatio-temporal video diffusion model that addresses both speech-driven portrait animation and free-viewpoint talking portrait synthesis, given an identity embedding or reference image, within a unified framework. Existing 2D speech-to-video diffusion models depend heavily on reference guidance, leading to limited motion diversity. At the same time, 3D-aware animation typically relies on inversion through pre-trained tri-plane generators, which often leads to imperfect reconstructions and identity drift. We rethink reference- and geometry-based paradigms in two ways. First, we deviate from strict reference conditioning at pre-training by introducing softer identity constraints. Second, we address 3D awareness implicitly within the 2D video domain by leveraging the inherent multi-view nature of video data. STARCaster adopts a compositional approach progressing from ID-aware motion modeling, to audio-visual synchronization via lip reading-based supervision, and finally to novel view animation through temporal-to-spatial adaptation. To overcome the scarcity of 4D audio-visual data, we propose a decoupled learning approach in which view consistency and temporal coherence are trained independently. A self-forcing training scheme enables the model to learn from longer temporal contexts than those generated at inference, mitigating the overly static animations common in existing autoregressive approaches. Comprehensive evaluations demonstrate that STARCaster generalizes effectively across tasks and identities, consistently surpassing prior approaches in different benchmarks.
SpinMeRound: Consistent Multi-View Identity Generation Using Diffusion Models
Apr 14, 2025Despite recent progress in diffusion models, generating realistic head portraits from novel viewpoints remains a significant challenge. Most current approaches are constrained to limited angular ranges, predominantly focusing on frontal or near-frontal views. Moreover, although the recent emerging large-scale diffusion models have been proven robust in handling 3D scenes, they underperform on facial data, given their complex structure and the uncanny valley pitfalls. In this paper, we propose SpinMeRound, a diffusion-based approach designed to generate consistent and accurate head portraits from novel viewpoints. By leveraging a number of input views alongside an identity embedding, our method effectively synthesizes diverse viewpoints of a subject whilst robustly maintaining its unique identity features. Through experimentation, we showcase our model's generation capabilities in 360 head synthesis, while beating current state-of-the-art multiview diffusion models.
FitDiff: Robust monocular 3D facial shape and reflectance estimation using Diffusion Models
Dec 07, 2023The remarkable progress in 3D face reconstruction has resulted in high-detail and photorealistic facial representations. Recently, Diffusion Models have revolutionized the capabilities of generative methods by achieving far better performance than GANs. In this work, we present FitDiff, a diffusion-based 3D facial avatar generative model. This model accurately generates relightable facial avatars, utilizing an identity embedding extracted from an "in-the-wild" 2D facial image. Our multi-modal diffusion model concurrently outputs facial reflectance maps (diffuse and specular albedo and normals) and shapes, showcasing great generalization capabilities. It is solely trained on an annotated subset of a public facial dataset, paired with 3D reconstructions. We revisit the typical 3D facial fitting approach by guiding a reverse diffusion process using perceptual and face recognition losses. Being the first LDM conditioned on face recognition embeddings, FitDiff reconstructs relightable human avatars, that can be used as-is in common rendering engines, starting only from an unconstrained facial image, and achieving state-of-the-art performance.
3DMM-RF: Convolutional Radiance Fields for 3D Face Modeling
Sep 15, 2022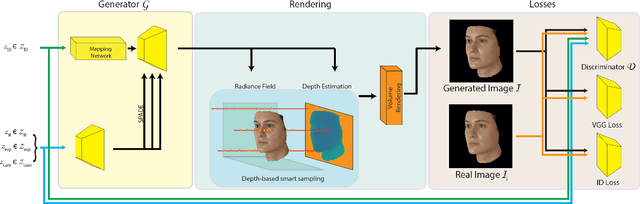
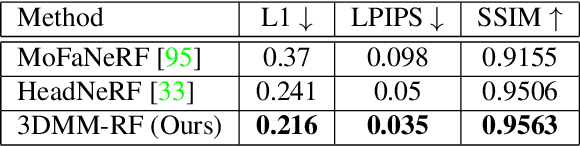


Facial 3D Morphable Models are a main computer vision subject with countless applications and have been highly optimized in the last two decades. The tremendous improvements of deep generative networks have created various possibilities for improving such models and have attracted wide interest. Moreover, the recent advances in neural radiance fields, are revolutionising novel-view synthesis of known scenes. In this work, we present a facial 3D Morphable Model, which exploits both of the above, and can accurately model a subject's identity, pose and expression and render it in arbitrary illumination. This is achieved by utilizing a powerful deep style-based generator to overcome two main weaknesses of neural radiance fields, their rigidity and rendering speed. We introduce a style-based generative network that synthesizes in one pass all and only the required rendering samples of a neural radiance field. We create a vast labelled synthetic dataset of facial renders, and train the network on these data, so that it can accurately model and generalize on facial identity, pose and appearance. Finally, we show that this model can accurately be fit to "in-the-wild" facial images of arbitrary pose and illumination, extract the facial characteristics, and be used to re-render the face in controllable conditions.