 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeGA: Texture Space Gaussian Avatars for High-Resolution Dynamic Head Modeling
May 08, 2025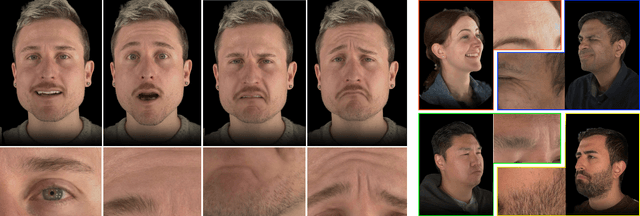
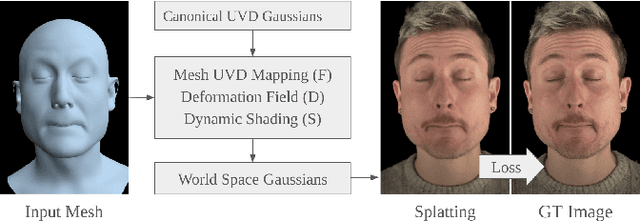


Sparse volumetric reconstruction and rendering via 3D Gaussian splatting have recently enabled animatable 3D head avatars that are rendered under arbitrary viewpoints with impressive photorealism. Today, such photoreal avatars are seen as a key component in emerging applications in telepresence, extended reality, and entertainment. Building a photoreal avatar requires estimating the complex non-rigid motion of different facial components as seen in input video images; due to inaccurate motion estimation, animatable models typically present a loss of fidelity and detail when compared to their non-animatable counterparts, built from an individual facial expression. Also, recent state-of-the-art models are often affected by memory limitations that reduce the number of 3D Gaussians used for modeling, leading to lower detail and quality. To address these problems, we present a new high-detail 3D head avatar model that improves upon the state of the art, largely increasing the number of 3D Gaussians and modeling quality for rendering at 4K resolution. Our high-quality model is reconstructed from multiview input video and builds on top of a mesh-based 3D morphable model, which provides a coarse deformation layer for the head. Photoreal appearance is modelled by 3D Gaussians embedded within the continuous UVD tangent space of this mesh, allowing for more effective densification where most needed. Additionally, these Gaussians are warped by a novel UVD deformation field to capture subtle, localized motion. Our key contribution is the novel deformable Gaussian encoding and overall fitting procedure that allows our head model to preserve appearance detail, while capturing facial motion and other transient high-frequency features such as skin wrinkling.
SpinMeRound: Consistent Multi-View Identity Generation Using Diffusion Models
Apr 14, 2025Despite recent progress in diffusion models, generating realistic head portraits from novel viewpoints remains a significant challenge. Most current approaches are constrained to limited angular ranges, predominantly focusing on frontal or near-frontal views. Moreover, although the recent emerging large-scale diffusion models have been proven robust in handling 3D scenes, they underperform on facial data, given their complex structure and the uncanny valley pitfalls. In this paper, we propose SpinMeRound, a diffusion-based approach designed to generate consistent and accurate head portraits from novel viewpoints. By leveraging a number of input views alongside an identity embedding, our method effectively synthesizes diverse viewpoints of a subject whilst robustly maintaining its unique identity features. Through experimentation, we showcase our model's generation capabilities in 360 head synthesis, while beating current state-of-the-art multiview diffusion models.
Synthetic Prior for Few-Shot Drivable Head Avatar Inversion
Jan 12, 2025We present SynShot, a novel method for the few-shot inversion of a drivable head avatar based on a synthetic prior. We tackle two major challenges. First, training a controllable 3D generative network requires a large number of diverse sequences, for which pairs of images and high-quality tracked meshes are not always available. Second, state-of-the-art monocular avatar models struggle to generalize to new views and expressions, lacking a strong prior and often overfitting to a specific viewpoint distribution. Inspired by machine learning models trained solely on synthetic data, we propose a method that learns a prior model from a large dataset of synthetic heads with diverse identities, expressions, and viewpoints. With few input images, SynShot fine-tunes the pretrained synthetic prior to bridge the domain gap, modeling a photorealistic head avatar that generalizes to novel expressions and viewpoints. We model the head avatar using 3D Gaussian splatting and a convolutional encoder-decoder that outputs Gaussian parameters in UV texture space. To account for the different modeling complexities over parts of the head (e.g., skin vs hair), we embed the prior with explicit control for upsampling the number of per-part primitives. Compared to state-of-the-art monocular methods that require thousands of real training images, SynShot significantly improves novel view and expression synthesis.
Arc2Avatar: Generating Expressive 3D Avatars from a Single Image via ID Guidance
Jan 09, 2025Inspired by the effectiveness of 3D Gaussian Splatting (3DGS) in reconstructing detailed 3D scenes within multi-view setups and the emergence of large 2D human foundation models, we introduce Arc2Avatar, the first SDS-based method utilizing a human face foundation model as guidance with just a single image as input. To achieve that, we extend such a model for diverse-view human head generation by fine-tuning on synthetic data and modifying its conditioning. Our avatars maintain a dense correspondence with a human face mesh template, allowing blendshape-based expression generation. This is achieved through a modified 3DGS approach, connectivity regularizers, and a strategic initialization tailored for our task. Additionally, we propose an optional efficient SDS-based correction step to refine the blendshape expressions, enhancing realism and diversity. Experiments demonstrate that Arc2Avatar achieves state-of-the-art realism and identity preservation, effectively addressing color issues by allowing the use of very low guidance, enabled by our strong identity prior and initialization strategy, without compromising detail.
ID-to-3D: Expressive ID-guided 3D Heads via Score Distillation Sampling
May 28, 2024We propose ID-to-3D, a method to generate identity- and text-guided 3D human heads with disentangled expressions, starting from even a single casually captured in-the-wild image of a subject. The foundation of our approach is anchored in compositionality, alongside the use of task-specific 2D diffusion models as priors for optimization. First, we extend a foundational model with a lightweight expression-aware and ID-aware architecture, and create 2D priors for geometry and texture generation, via fine-tuning only 0.2% of its available training parameters. Then, we jointly leverage a neural parametric representation for the expressions of each subject and a multi-stage generation of highly detailed geometry and albedo texture. This combination of strong face identity embeddings and our neural representation enables accurate reconstruction of not only facial features but also accessories and hair and can be meshed to provide render-ready assets for gaming and telepresence. Our results achieve an unprecedented level of identity-consistent and high-quality texture and geometry generation, generalizing to a ``world'' of unseen 3D identities, without relying on large 3D captured datasets of human assets.
AnimateMe: 4D Facial Expressions via Diffusion Models
Mar 25, 2024



The field of photorealistic 3D avatar reconstruction and generation has garnered significant attention in recent years; however, animating such avatars remains challenging. Recent advances in diffusion models have notably enhanced the capabilities of generative models in 2D animation. In this work, we directly utilize these models within the 3D domain to achieve controllable and high-fidelity 4D facial animation. By integrating the strengths of diffusion processes and geometric deep learning, we employ Graph Neural Networks (GNNs) as denoising diffusion models in a novel approach, formulating the diffusion process directly on the mesh space and enabling the generation of 3D facial expressions. This facilitates the generation of facial deformations through a mesh-diffusion-based model. Additionally, to ensure temporal coherence in our animations, we propose a consistent noise sampling method. Under a series of both quantitative and qualitative experiments, we showcase that the proposed method outperforms prior work in 4D expression synthesis by generating high-fidelity extreme expressions. Furthermore, we applied our method to textured 4D facial expression generation, implementing a straightforward extension that involves training on a large-scale textured 4D facial expression database.
Arc2Face: A Foundation Model of Human Faces
Mar 18, 2024This paper presents Arc2Face, an identity-conditioned face foundation model, which, given the ArcFace embedding of a person, can generate diverse photo-realistic images with an unparalleled degree of face similarity than existing models. Despite previous attempts to decode face recognition features into detailed images, we find that common high-resolution datasets (e.g. FFHQ) lack sufficient identities to reconstruct any subject. To that end, we meticulously upsample a significant portion of the WebFace42M database, the largest public dataset for face recognition (FR). Arc2Face builds upon a pretrained Stable Diffusion model, yet adapts it to the task of ID-to-face generation, conditioned solely on ID vectors. Deviating from recent works that combine ID with text embeddings for zero-shot personalization of text-to-image models, we emphasize on the compactness of FR features, which can fully capture the essence of the human face, as opposed to hand-crafted prompts. Crucially, text-augmented models struggle to decouple identity and text, usually necessitating some description of the given face to achieve satisfactory similarity. Arc2Face, however, only needs the discriminative features of ArcFace to guide the generation, offering a robust prior for a plethora of tasks where ID consistency is of paramount importance. As an example, we train a FR model on synthetic images from our model and achieve superior performance to existing synthetic datasets.
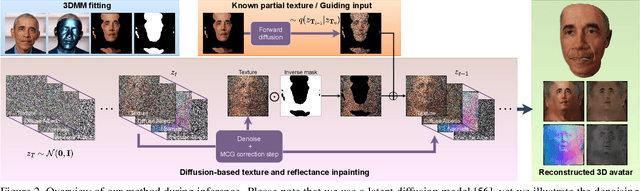
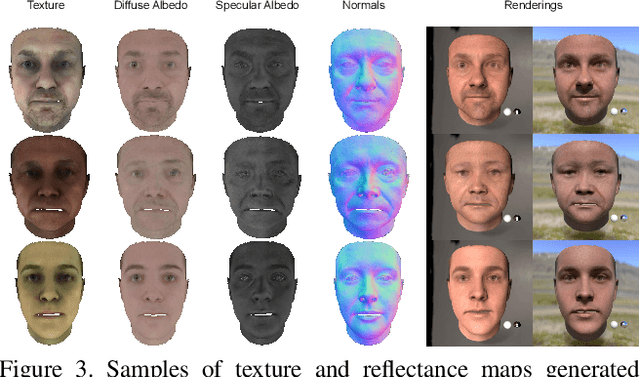
FitDiff: Robust monocular 3D facial shape and reflectance estimation using Diffusion Models
Dec 07, 2023The remarkable progress in 3D face reconstruction has resulted in high-detail and photorealistic facial representations. Recently, Diffusion Models have revolutionized the capabilities of generative methods by achieving far better performance than GANs. In this work, we present FitDiff, a diffusion-based 3D facial avatar generative model. This model accurately generates relightable facial avatars, utilizing an identity embedding extracted from an "in-the-wild" 2D facial image. Our multi-modal diffusion model concurrently outputs facial reflectance maps (diffuse and specular albedo and normals) and shapes, showcasing great generalization capabilities. It is solely trained on an annotated subset of a public facial dataset, paired with 3D reconstructions. We revisit the typical 3D facial fitting approach by guiding a reverse diffusion process using perceptual and face recognition losses. Being the first LDM conditioned on face recognition embeddings, FitDiff reconstructs relightable human avatars, that can be used as-is in common rendering engines, starting only from an unconstrained facial image, and achieving state-of-the-art performance.
FitMe: Deep Photorealistic 3D Morphable Model Avatars
May 16, 2023



In this paper, we introduce FitMe, a facial reflectance model and a differentiable rendering optimization pipeline, that can be used to acquire high-fidelity renderable human avatars from single or multiple images. The model consists of a multi-modal style-based generator, that captures facial appearance in terms of diffuse and specular reflectance, and a PCA-based shape model. We employ a fast differentiable rendering process that can be used in an optimization pipeline, while also achieving photorealistic facial shading. Our optimization process accurately captures both the facial reflectance and shape in high-detail, by exploiting the expressivity of the style-based latent representation and of our shape model. FitMe achieves state-of-the-art reflectance acquisition and identity preservation on single "in-the-wild" facial images, while it produces impressive scan-like results, when given multiple unconstrained facial images pertaining to the same identity. In contrast with recent implicit avatar reconstructions, FitMe requires only one minute and produces relightable mesh and texture-based avatars, that can be used by end-user applications.
Relightify: Relightable 3D Faces from a Single Image via Diffusion Models
May 10, 2023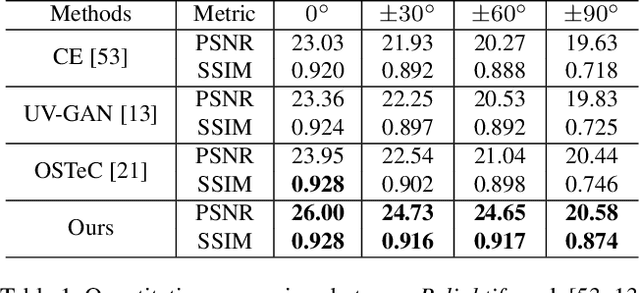

Following the remarkable success of diffusion models on image generation, recent works have also demonstrated their impressive ability to address a number of inverse problems in an unsupervised way, by properly constraining the sampling process based on a conditioning input. Motivated by this, in this paper, we present the first approach to use diffusion models as a prior for highly accurate 3D facial BRDF reconstruction from a single image. We start by leveraging a high-quality UV dataset of facial reflectance (diffuse and specular albedo and normals), which we render under varying illumination settings to simulate natural RGB textures and, then, train an unconditional diffusion model on concatenated pairs of rendered textures and reflectance components. At test time, we fit a 3D morphable model to the given image and unwrap the face in a partial UV texture. By sampling from the diffusion model, while retaining the observed texture part intact, the model inpaints not only the self-occluded areas but also the unknown reflectance components, in a single sequence of denoising steps. In contrast to existing methods, we directly acquire the observed texture from the input image, thus, resulting in more faithful and consistent reflectance estimation. Through a series of qualitative and quantitative comparisons, we demonstrate superior performance in both texture completion as well as reflectance reconstruction tasks.