 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeID-to-3D: Expressive ID-guided 3D Heads via Score Distillation Sampling
May 28, 2024We propose ID-to-3D, a method to generate identity- and text-guided 3D human heads with disentangled expressions, starting from even a single casually captured in-the-wild image of a subject. The foundation of our approach is anchored in compositionality, alongside the use of task-specific 2D diffusion models as priors for optimization. First, we extend a foundational model with a lightweight expression-aware and ID-aware architecture, and create 2D priors for geometry and texture generation, via fine-tuning only 0.2% of its available training parameters. Then, we jointly leverage a neural parametric representation for the expressions of each subject and a multi-stage generation of highly detailed geometry and albedo texture. This combination of strong face identity embeddings and our neural representation enables accurate reconstruction of not only facial features but also accessories and hair and can be meshed to provide render-ready assets for gaming and telepresence. Our results achieve an unprecedented level of identity-consistent and high-quality texture and geometry generation, generalizing to a ``world'' of unseen 3D identities, without relying on large 3D captured datasets of human assets.
Tunable Convolutions with Parametric Multi-Loss Optimization
Apr 03, 2023Behavior of neural networks is irremediably determined by the specific loss and data used during training. However it is often desirable to tune the model at inference time based on external factors such as preferences of the user or dynamic characteristics of the data. This is especially important to balance the perception-distortion trade-off of ill-posed image-to-image translation tasks. In this work, we propose to optimize a parametric tunable convolutional layer, which includes a number of different kernels, using a parametric multi-loss, which includes an equal number of objectives. Our key insight is to use a shared set of parameters to dynamically interpolate both the objectives and the kernels. During training, these parameters are sampled at random to explicitly optimize all possible combinations of objectives and consequently disentangle their effect into the corresponding kernels. During inference, these parameters become interactive inputs of the model hence enabling reliable and consistent control over the model behavior. Extensive experimental results demonstrate that our tunable convolutions effectively work as a drop-in replacement for traditional convolutions in existing neural networks at virtually no extra computational cost, outperforming state-of-the-art control strategies in a wide range of applications; including image denoising, deblurring, super-resolution, and style transfer.
Poly-NL: Linear Complexity Non-local Layers with Polynomials
Jul 06, 2021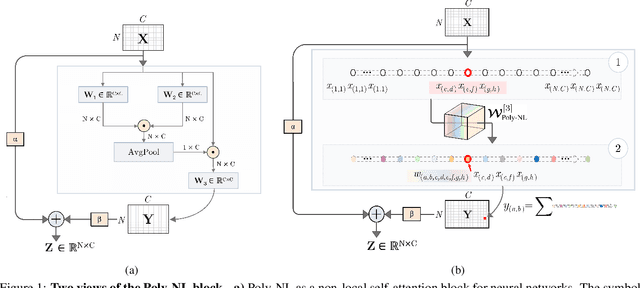
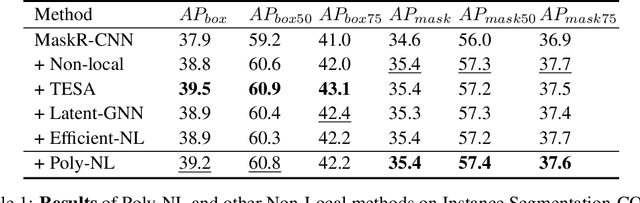
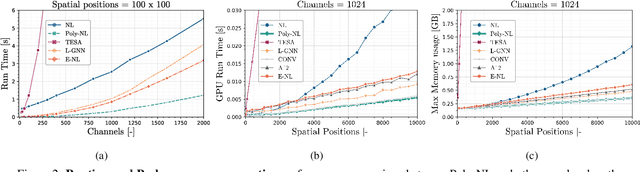
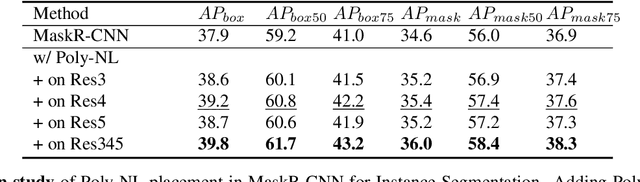
Spatial self-attention layers, in the form of Non-Local blocks, introduce long-range dependencies in Convolutional Neural Networks by computing pairwise similarities among all possible positions. Such pairwise functions underpin the effectiveness of non-local layers, but also determine a complexity that scales quadratically with respect to the input size both in space and time. This is a severely limiting factor that practically hinders the applicability of non-local blocks to even moderately sized inputs. Previous works focused on reducing the complexity by modifying the underlying matrix operations, however in this work we aim to retain full expressiveness of non-local layers while keeping complexity linear. We overcome the efficiency limitation of non-local blocks by framing them as special cases of 3rd order polynomial functions. This fact enables us to formulate novel fast Non-Local blocks, capable of reducing the complexity from quadratic to linear with no loss in performance, by replacing any direct computation of pairwise similarities with element-wise multiplications. The proposed method, which we dub as "Poly-NL", is competitive with state-of-the-art performance across image recognition, instance segmentation, and face detection tasks, while having considerably less computational overhead.
Exploring the Challenges towards Lifelong Fact Learning
Dec 26, 2018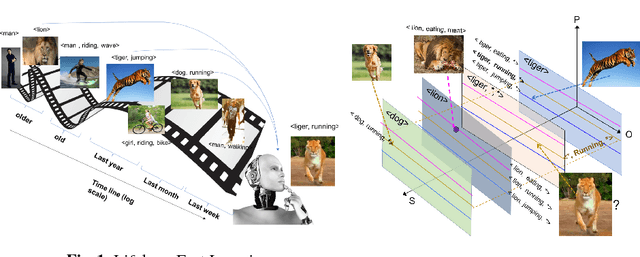
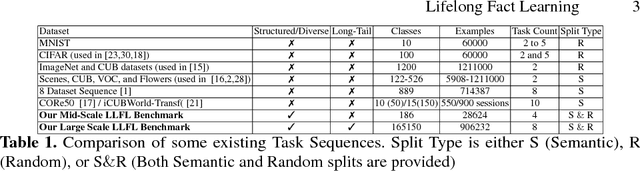
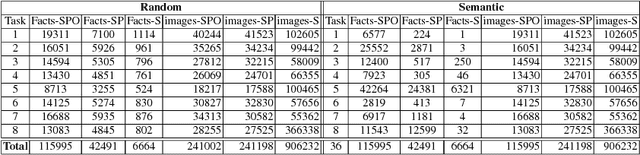
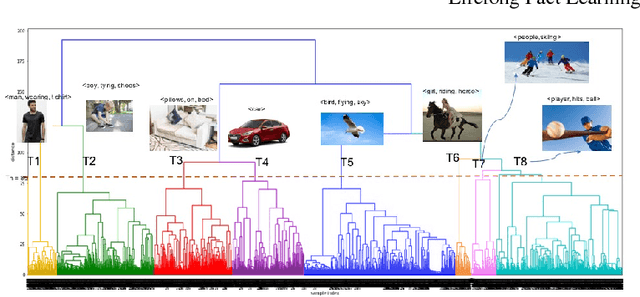
So far life-long learning (LLL) has been studied in relatively small-scale and relatively artificial setups. Here, we introduce a new large-scale alternative. What makes the proposed setup more natural and closer to human-like visual systems is threefold: First, we focus on concepts (or facts, as we call them) of varying complexity, ranging from single objects to more complex structures such as objects performing actions, and objects interacting with other objects. Second, as in real-world settings, our setup has a long-tail distribution, an aspect which has mostly been ignored in the LLL context. Third, facts across tasks may share structure (e.g., <person, riding, wave> and <dog, riding, wave>). Facts can also be semantically related (e.g., "liger" relates to seen categories like "tiger" and "lion"). Given the large number of possible facts, a LLL setup seems a natural choice. To avoid model size growing over time and to optimally exploit the semantic relations and structure, we combine it with a visual semantic embedding instead of discrete class labels. We adapt existing datasets with the properties mentioned above into new benchmarks, by dividing them semantically or randomly into disjoint tasks. This leads to two large-scale benchmarks with 906,232 images and 165,150 unique facts, on which we evaluate and analyze state-of-the-art LLL methods.
Memory Aware Synapses: Learning what to forget
Oct 05, 2018
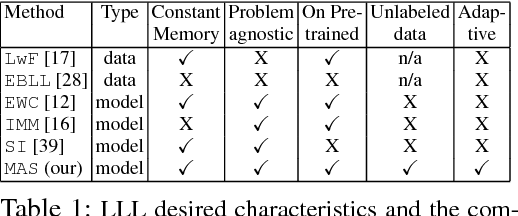
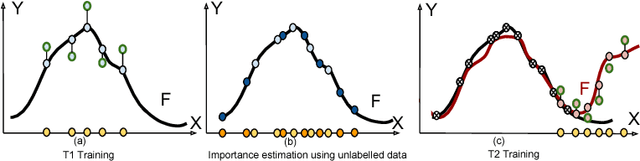
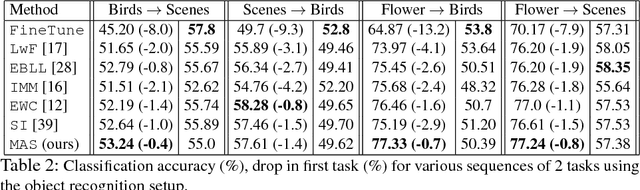
Humans can learn in a continuous manner. Old rarely utilized knowledge can be overwritten by new incoming information while important, frequently used knowledge is prevented from being erased. In artificial learning systems, lifelong learning so far has focused mainly on accumulating knowledge over tasks and overcoming catastrophic forgetting. In this paper, we argue that, given the limited model capacity and the unlimited new information to be learned, knowledge has to be preserved or erased selectively. Inspired by neuroplasticity, we propose a novel approach for lifelong learning, coined Memory Aware Synapses (MAS). It computes the importance of the parameters of a neural network in an unsupervised and online manner. Given a new sample which is fed to the network, MAS accumulates an importance measure for each parameter of the network, based on how sensitive the predicted output function is to a change in this parameter. When learning a new task, changes to important parameters can then be penalized, effectively preventing important knowledge related to previous tasks from being overwritten. Further, we show an interesting connection between a local version of our method and Hebb's rule,which is a model for the learning process in the brain. We test our method on a sequence of object recognition tasks and on the challenging problem of learning an embedding for predicting $<$subject, predicate, object$>$ triplets. We show state-of-the-art performance and, for the first time, the ability to adapt the importance of the parameters based on unlabeled data towards what the network needs (not) to forget, which may vary depending on test conditions.
Learning Deep Visual Object Models From Noisy Web Data: How to Make it Work
Feb 28, 2017

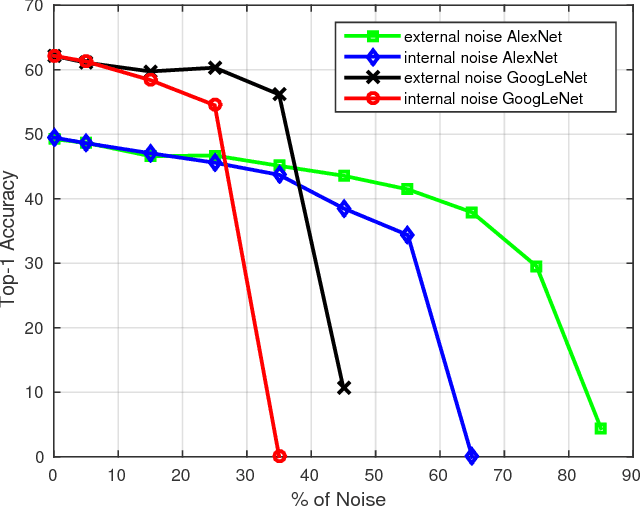
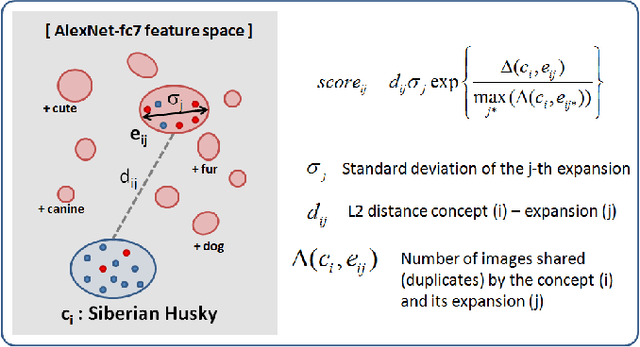
Deep networks thrive when trained on large scale data collections. This has given ImageNet a central role in the development of deep architectures for visual object classification. However, ImageNet was created during a specific period in time, and as such it is prone to aging, as well as dataset bias issues. Moving beyond fixed training datasets will lead to more robust visual systems, especially when deployed on robots in new environments which must train on the objects they encounter there. To make this possible, it is important to break free from the need for manual annotators. Recent work has begun to investigate how to use the massive amount of images available on the Web in place of manual image annotations. We contribute to this research thread with two findings: (1) a study correlating a given level of noisily labels to the expected drop in accuracy, for two deep architectures, on two different types of noise, that clearly identifies GoogLeNet as a suitable architecture for learning from Web data; (2) a recipe for the creation of Web datasets with minimal noise and maximum visual variability, based on a visual and natural language processing concept expansion strategy. By combining these two results, we obtain a method for learning powerful deep object models automatically from the Web. We confirm the effectiveness of our approach through object categorization experiments using our Web-derived version of ImageNet on a popular robot vision benchmark database, and on a lifelong object discovery task on a mobile robot.
* 8 pages, 7 figures, 3 tables