 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training
Sep 30, 2025



Large Language Models (LLMs), despite being trained on text alone, surprisingly develop rich visual priors. These priors allow latent visual capabilities to be unlocked for vision tasks with a relatively small amount of multimodal data, and in some cases, to perform visual tasks without ever having seen an image. Through systematic analysis, we reveal that visual priors-the implicit, emergent knowledge about the visual world acquired during language pre-training-are composed of separable perception and reasoning priors with unique scaling trends and origins. We show that an LLM's latent visual reasoning ability is predominantly developed by pre-training on reasoning-centric data (e.g., code, math, academia) and scales progressively. This reasoning prior acquired from language pre-training is transferable and universally applicable to visual reasoning. In contrast, a perception prior emerges more diffusely from broad corpora, and perception ability is more sensitive to the vision encoder and visual instruction tuning data. In parallel, text describing the visual world proves crucial, though its performance impact saturates rapidly. Leveraging these insights, we propose a data-centric recipe for pre-training vision-aware LLMs and verify it in 1T token scale pre-training. Our findings are grounded in over 100 controlled experiments consuming 500,000 GPU-hours, spanning the full MLLM construction pipeline-from LLM pre-training to visual alignment and supervised multimodal fine-tuning-across five model scales, a wide range of data categories and mixtures, and multiple adaptation setups. Along with our main findings, we propose and investigate several hypotheses, and introduce the Multi-Level Existence Bench (MLE-Bench). Together, this work provides a new way of deliberately cultivating visual priors from language pre-training, paving the way for the next generation of multimodal LLMs.
WildCAT3D: Appearance-Aware Multi-View Diffusion in the Wild
Jun 16, 2025Despite recent advances in sparse novel view synthesis (NVS) applied to object-centric scenes, scene-level NVS remains a challenge. A central issue is the lack of available clean multi-view training data, beyond manually curated datasets with limited diversity, camera variation, or licensing issues. On the other hand, an abundance of diverse and permissively-licensed data exists in the wild, consisting of scenes with varying appearances (illuminations, transient occlusions, etc.) from sources such as tourist photos. To this end, we present WildCAT3D, a framework for generating novel views of scenes learned from diverse 2D scene image data captured in the wild. We unlock training on these data sources by explicitly modeling global appearance conditions in images, extending the state-of-the-art multi-view diffusion paradigm to learn from scene views of varying appearances. Our trained model generalizes to new scenes at inference time, enabling the generation of multiple consistent novel views. WildCAT3D provides state-of-the-art results on single-view NVS in object- and scene-level settings, while training on strictly less data sources than prior methods. Additionally, it enables novel applications by providing global appearance control during generation.
Gen3DEval: Using vLLMs for Automatic Evaluation of Generated 3D Objects
Apr 10, 2025



Rapid advancements in text-to-3D generation require robust and scalable evaluation metrics that align closely with human judgment, a need unmet by current metrics such as PSNR and CLIP, which require ground-truth data or focus only on prompt fidelity. To address this, we introduce Gen3DEval, a novel evaluation framework that leverages vision large language models (vLLMs) specifically fine-tuned for 3D object quality assessment. Gen3DEval evaluates text fidelity, appearance, and surface quality by analyzing 3D surface normals, without requiring ground-truth comparisons, bridging the gap between automated metrics and user preferences. Compared to state-of-the-art task-agnostic models, Gen3DEval demonstrates superior performance in user-aligned evaluations, placing it as a comprehensive and accessible benchmark for future research on text-to-3D generation. The project page can be found here: \href{https://shalini-maiti.github.io/gen3deval.github.io/}{https://shalini-maiti.github.io/gen3deval.github.io/}.
VGRP-Bench: Visual Grid Reasoning Puzzle Benchmark for Large Vision-Language Models
Apr 02, 2025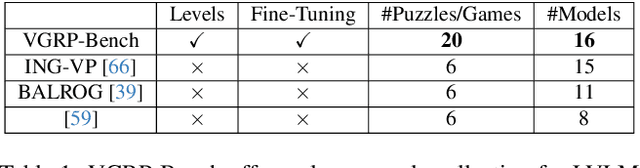
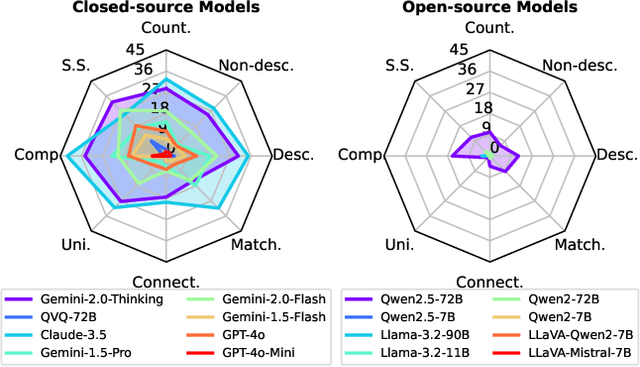
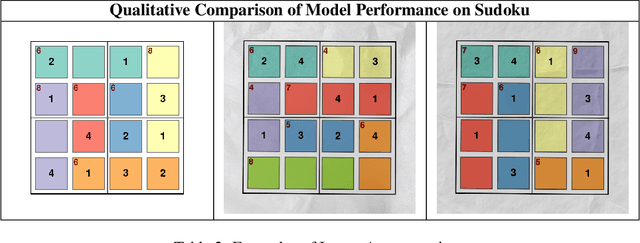
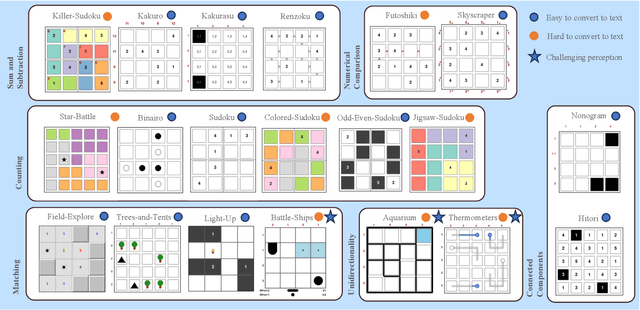
Large Vision-Language Models (LVLMs) struggle with puzzles, which require precise perception, rule comprehension, and logical reasoning. Assessing and enhancing their performance in this domain is crucial, as it reflects their ability to engage in structured reasoning - an essential skill for real-world problem-solving. However, existing benchmarks primarily evaluate pre-trained models without additional training or fine-tuning, often lack a dedicated focus on reasoning, and fail to establish a systematic evaluation framework. To address these limitations, we introduce VGRP-Bench, a Visual Grid Reasoning Puzzle Benchmark featuring 20 diverse puzzles. VGRP-Bench spans multiple difficulty levels, and includes extensive experiments not only on existing chat LVLMs (e.g., GPT-4o), but also on reasoning LVLMs (e.g., Gemini-Thinking). Our results reveal that even the state-of-the-art LVLMs struggle with these puzzles, highlighting fundamental limitations in their puzzle-solving capabilities. Most importantly, through systematic experiments, we identify and analyze key factors influencing LVLMs' puzzle-solving performance, including the number of clues, grid size, and rule complexity. Furthermore, we explore two Supervised Fine-Tuning (SFT) strategies that can be used in post-training: SFT on solutions (S-SFT) and SFT on synthetic reasoning processes (R-SFT). While both methods significantly improve performance on trained puzzles, they exhibit limited generalization to unseen ones. We will release VGRP-Bench to facilitate further research on LVLMs for complex, real-world problem-solving. Project page: https://yufan-ren.com/subpage/VGRP-Bench/.
Flex3D: Feed-Forward 3D Generation With Flexible Reconstruction Model And Input View Curation
Oct 02, 2024

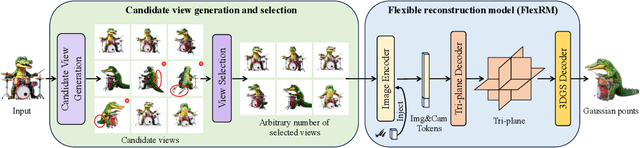
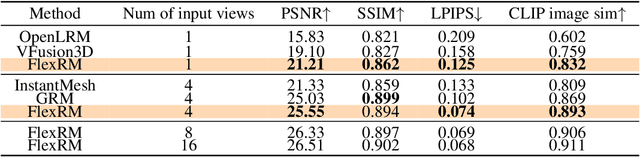
Generating high-quality 3D content from text, single images, or sparse view images remains a challenging task with broad applications. Existing methods typically employ multi-view diffusion models to synthesize multi-view images, followed by a feed-forward process for 3D reconstruction. However, these approaches are often constrained by a small and fixed number of input views, limiting their ability to capture diverse viewpoints and, even worse, leading to suboptimal generation results if the synthesized views are of poor quality. To address these limitations, we propose Flex3D, a novel two-stage framework capable of leveraging an arbitrary number of high-quality input views. The first stage consists of a candidate view generation and curation pipeline. We employ a fine-tuned multi-view image diffusion model and a video diffusion model to generate a pool of candidate views, enabling a rich representation of the target 3D object. Subsequently, a view selection pipeline filters these views based on quality and consistency, ensuring that only the high-quality and reliable views are used for reconstruction. In the second stage, the curated views are fed into a Flexible Reconstruction Model (FlexRM), built upon a transformer architecture that can effectively process an arbitrary number of inputs. FlemRM directly outputs 3D Gaussian points leveraging a tri-plane representation, enabling efficient and detailed 3D generation. Through extensive exploration of design and training strategies, we optimize FlexRM to achieve superior performance in both reconstruction and generation tasks. Our results demonstrate that Flex3D achieves state-of-the-art performance, with a user study winning rate of over 92% in 3D generation tasks when compared to several of the latest feed-forward 3D generative models.
Meta 3D Gen
Jul 02, 2024


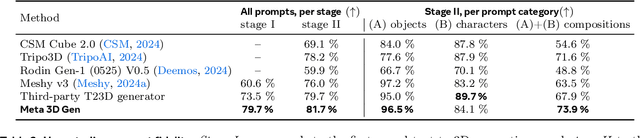
We introduce Meta 3D Gen (3DGen), a new state-of-the-art, fast pipeline for text-to-3D asset generation. 3DGen offers 3D asset creation with high prompt fidelity and high-quality 3D shapes and textures in under a minute. It supports physically-based rendering (PBR), necessary for 3D asset relighting in real-world applications. Additionally, 3DGen supports generative retexturing of previously generated (or artist-created) 3D shapes using additional textual inputs provided by the user. 3DGen integrates key technical components, Meta 3D AssetGen and Meta 3D TextureGen, that we developed for text-to-3D and text-to-texture generation, respectively. By combining their strengths, 3DGen represents 3D objects simultaneously in three ways: in view space, in volumetric space, and in UV (or texture) space. The integration of these two techniques achieves a win rate of 68% with respect to the single-stage model. We compare 3DGen to numerous industry baselines, and show that it outperforms them in terms of prompt fidelity and visual quality for complex textual prompts, while being significantly faster.
Meta 3D AssetGen: Text-to-Mesh Generation with High-Quality Geometry, Texture, and PBR Materials
Jul 02, 2024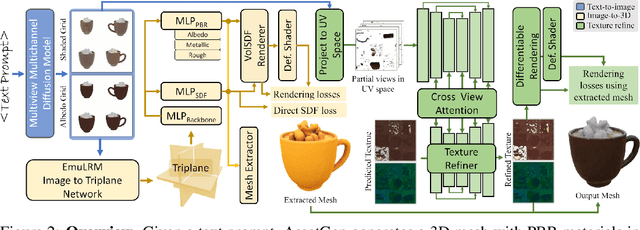
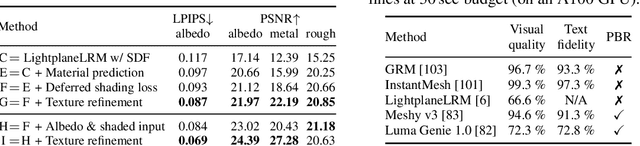
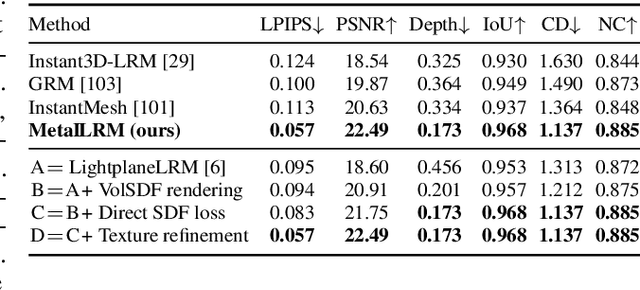

We present Meta 3D AssetGen (AssetGen), a significant advancement in text-to-3D generation which produces faithful, high-quality meshes with texture and material control. Compared to works that bake shading in the 3D object's appearance, AssetGen outputs physically-based rendering (PBR) materials, supporting realistic relighting. AssetGen generates first several views of the object with factored shaded and albedo appearance channels, and then reconstructs colours, metalness and roughness in 3D, using a deferred shading loss for efficient supervision. It also uses a sign-distance function to represent 3D shape more reliably and introduces a corresponding loss for direct shape supervision. This is implemented using fused kernels for high memory efficiency. After mesh extraction, a texture refinement transformer operating in UV space significantly improves sharpness and details. AssetGen achieves 17% improvement in Chamfer Distance and 40% in LPIPS over the best concurrent work for few-view reconstruction, and a human preference of 72% over the best industry competitors of comparable speed, including those that support PBR. Project page with generated assets: https://assetgen.github.io
DreamCraft: Text-Guided Generation of Functional 3D Environments in Minecraft
Apr 23, 2024Procedural Content Generation (PCG) algorithms enable the automatic generation of complex and diverse artifacts. However, they don't provide high-level control over the generated content and typically require domain expertise. In contrast, text-to-3D methods allow users to specify desired characteristics in natural language, offering a high amount of flexibility and expressivity. But unlike PCG, such approaches cannot guarantee functionality, which is crucial for certain applications like game design. In this paper, we present a method for generating functional 3D artifacts from free-form text prompts in the open-world game Minecraft. Our method, DreamCraft, trains quantized Neural Radiance Fields (NeRFs) to represent artifacts that, when viewed in-game, match given text descriptions. We find that DreamCraft produces more aligned in-game artifacts than a baseline that post-processes the output of an unconstrained NeRF. Thanks to the quantized representation of the environment, functional constraints can be integrated using specialized loss terms. We show how this can be leveraged to generate 3D structures that match a target distribution or obey certain adjacency rules over the block types. DreamCraft inherits a high degree of expressivity and controllability from the NeRF, while still being able to incorporate functional constraints through domain-specific objectives.