 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCWoMP: Morpheme Representation Learning for Interlinear Glossing
Mar 18, 2026Interlinear glossed text (IGT) is a standard notation for language documentation which is linguistically rich but laborious to produce manually. Recent automated IGT methods treat glosses as character sequences, neglecting their compositional structure. We propose CWoMP (Contrastive Word-Morpheme Pretraining), which instead treats morphemes as atomic form-meaning units with learned representations. A contrastively trained encoder aligns words-in-context with their constituent morphemes in a shared embedding space; an autoregressive decoder then generates the morpheme sequence by retrieving entries from a mutable lexicon of these embeddings. Predictions are interpretable--grounded in lexicon entries--and users can improve results at inference time by expanding the lexicon without retraining. We evaluate on diverse low-resource languages, showing that CWoMP outperforms existing methods while being significantly more efficient, with particularly strong gains in extremely low-resource settings.
ConlangCrafter: Constructing Languages with a Multi-Hop LLM Pipeline
Aug 08, 2025Constructed languages (conlangs) such as Esperanto and Quenya have played diverse roles in art, philosophy, and international communication. Meanwhile, large-scale foundation models have revolutionized creative generation in text, images, and beyond. In this work, we leverage modern LLMs as computational creativity aids for end-to-end conlang creation. We introduce ConlangCrafter, a multi-hop pipeline that decomposes language design into modular stages -- phonology, morphology, syntax, lexicon generation, and translation. At each stage, our method leverages LLMs' meta-linguistic reasoning capabilities, injecting randomness to encourage diversity and leveraging self-refinement feedback to encourage consistency in the emerging language description. We evaluate ConlangCrafter on metrics measuring coherence and typological diversity, demonstrating its ability to produce coherent and varied conlangs without human linguistic expertise.
WildCAT3D: Appearance-Aware Multi-View Diffusion in the Wild
Jun 16, 2025Despite recent advances in sparse novel view synthesis (NVS) applied to object-centric scenes, scene-level NVS remains a challenge. A central issue is the lack of available clean multi-view training data, beyond manually curated datasets with limited diversity, camera variation, or licensing issues. On the other hand, an abundance of diverse and permissively-licensed data exists in the wild, consisting of scenes with varying appearances (illuminations, transient occlusions, etc.) from sources such as tourist photos. To this end, we present WildCAT3D, a framework for generating novel views of scenes learned from diverse 2D scene image data captured in the wild. We unlock training on these data sources by explicitly modeling global appearance conditions in images, extending the state-of-the-art multi-view diffusion paradigm to learn from scene views of varying appearances. Our trained model generalizes to new scenes at inference time, enabling the generation of multiple consistent novel views. WildCAT3D provides state-of-the-art results on single-view NVS in object- and scene-level settings, while training on strictly less data sources than prior methods. Additionally, it enables novel applications by providing global appearance control during generation.
Phonikud: Hebrew Grapheme-to-Phoneme Conversion for Real-Time Text-to-Speech
Jun 14, 2025Real-time text-to-speech (TTS) for Modern Hebrew is challenging due to the language's orthographic complexity. Existing solutions ignore crucial phonetic features such as stress that remain underspecified even when vowel marks are added. To address these limitations, we introduce Phonikud, a lightweight, open-source Hebrew grapheme-to-phoneme (G2P) system that outputs fully-specified IPA transcriptions. Our approach adapts an existing diacritization model with lightweight adaptors, incurring negligible additional latency. We also contribute the ILSpeech dataset of transcribed Hebrew speech with IPA annotations, serving as a benchmark for Hebrew G2P and as training data for TTS systems. Our results demonstrate that Phonikud G2P conversion more accurately predicts phonemes from Hebrew text compared to prior methods, and that this enables training of effective real-time Hebrew TTS models with superior speed-accuracy trade-offs. We release our code, data, and models at https://phonikud.github.io.
Dynamic Scene Understanding from Vision-Language Representations
Jan 20, 2025



Images depicting complex, dynamic scenes are challenging to parse automatically, requiring both high-level comprehension of the overall situation and fine-grained identification of participating entities and their interactions. Current approaches use distinct methods tailored to sub-tasks such as Situation Recognition and detection of Human-Human and Human-Object Interactions. However, recent advances in image understanding have often leveraged web-scale vision-language (V&L) representations to obviate task-specific engineering. In this work, we propose a framework for dynamic scene understanding tasks by leveraging knowledge from modern, frozen V&L representations. By framing these tasks in a generic manner - as predicting and parsing structured text, or by directly concatenating representations to the input of existing models - we achieve state-of-the-art results while using a minimal number of trainable parameters relative to existing approaches. Moreover, our analysis of dynamic knowledge of these representations shows that recent, more powerful representations effectively encode dynamic scene semantics, making this approach newly possible.
WAFFLE: Multimodal Floorplan Understanding in the Wild
Dec 01, 2024



Buildings are a central feature of human culture and are increasingly being analyzed with computational methods. However, recent works on computational building understanding have largely focused on natural imagery of buildings, neglecting the fundamental element defining a building's structure -- its floorplan. Conversely, existing works on floorplan understanding are extremely limited in scope, often focusing on floorplans of a single semantic category and region (e.g. floorplans of apartments from a single country). In this work, we introduce WAFFLE, a novel multimodal floorplan understanding dataset of nearly 20K floorplan images and metadata curated from Internet data spanning diverse building types, locations, and data formats. By using a large language model and multimodal foundation models, we curate and extract semantic information from these images and their accompanying noisy metadata. We show that WAFFLE enables progress on new building understanding tasks, both discriminative and generative, which were not feasible using prior datasets. We will publicly release WAFFLE along with our code and trained models, providing the research community with a new foundation for learning the semantics of buildings.
Emergent Visual-Semantic Hierarchies in Image-Text Representations
Jul 11, 2024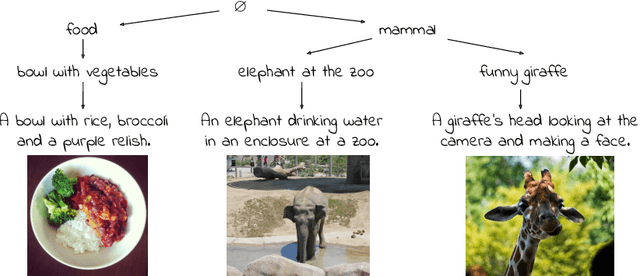
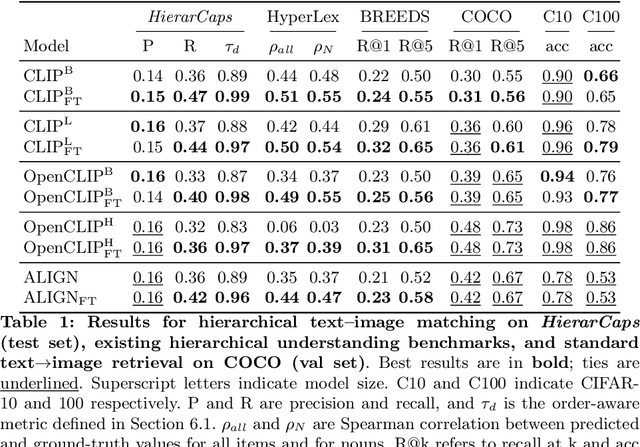
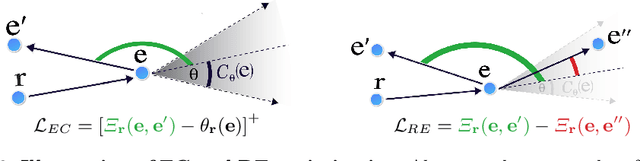
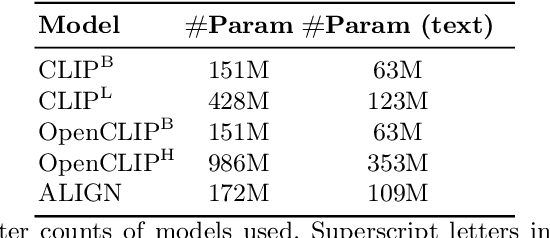
While recent vision-and-language models (VLMs) like CLIP are a powerful tool for analyzing text and images in a shared semantic space, they do not explicitly model the hierarchical nature of the set of texts which may describe an image. Conversely, existing multimodal hierarchical representation learning methods require costly training from scratch, failing to leverage the knowledge encoded by state-of-the-art multimodal foundation models. In this work, we study the knowledge of existing foundation models, finding that they exhibit emergent understanding of visual-semantic hierarchies despite not being directly trained for this purpose. We propose the Radial Embedding (RE) framework for probing and optimizing hierarchical understanding, and contribute the HierarCaps dataset, a benchmark facilitating the study of hierarchical knowledge in image--text representations, constructed automatically via large language models. Our results show that foundation VLMs exhibit zero-shot hierarchical understanding, surpassing the performance of prior models explicitly designed for this purpose. Furthermore, we show that foundation models may be better aligned to hierarchical reasoning via a text-only fine-tuning phase, while retaining pretraining knowledge.
ICC: Quantifying Image Caption Concreteness for Multimodal Dataset Curation
Mar 02, 2024



Web-scale training on paired text-image data is becoming increasingly central to multimodal learning, but is challenged by the highly noisy nature of datasets in the wild. Standard data filtering approaches succeed in removing mismatched text-image pairs, but permit semantically related but highly abstract or subjective text. These approaches lack the fine-grained ability to isolate the most concrete samples that provide the strongest signal for learning in a noisy dataset. In this work, we propose a new metric, image caption concreteness, that evaluates caption text without an image reference to measure its concreteness and relevancy for use in multimodal learning. Our approach leverages strong foundation models for measuring visual-semantic information loss in multimodal representations. We demonstrate that this strongly correlates with human evaluation of concreteness in both single-word and sentence-level texts. Moreover, we show that curation using ICC complements existing approaches: It succeeds in selecting the highest quality samples from multimodal web-scale datasets to allow for efficient training in resource-constrained settings.
MOCHa: Multi-Objective Reinforcement Mitigating Caption Hallucinations
Dec 06, 2023While recent years have seen rapid progress in image-conditioned text generation, image captioning still suffers from the fundamental issue of hallucinations, the generation of spurious details that cannot be inferred from the given image. Dedicated methods for reducing hallucinations in image captioning largely focus on closed-vocabulary object tokens, ignoring most types of hallucinations that occur in practice. In this work, we propose MOCHa, an approach that harnesses advancements in reinforcement learning (RL) to address the sequence-level nature of hallucinations in an open-world setup. To optimize for caption fidelity to the input image, we leverage ground-truth reference captions as proxies to measure the logical consistency of generated captions. However, optimizing for caption fidelity alone fails to preserve the semantic adequacy of generations; therefore, we propose a multi-objective reward function that jointly targets these qualities, without requiring any strong supervision. We demonstrate that these goals can be simultaneously optimized with our framework, enhancing performance for various captioning models of different scales. Our qualitative and quantitative results demonstrate MOCHa's superior performance across various established metrics. We also demonstrate the benefit of our method in the open-vocabulary setting. To this end, we contribute OpenCHAIR, a new benchmark for quantifying open-vocabulary hallucinations in image captioning models, constructed using generative foundation models. We will release our code, benchmark, and trained models.
Kiki or Bouba? Sound Symbolism in Vision-and-Language Models
Oct 25, 2023Although the mapping between sound and meaning in human language is assumed to be largely arbitrary, research in cognitive science has shown that there are non-trivial correlations between particular sounds and meanings across languages and demographic groups, a phenomenon known as sound symbolism. Among the many dimensions of meaning, sound symbolism is particularly salient and well-demonstrated with regards to cross-modal associations between language and the visual domain. In this work, we address the question of whether sound symbolism is reflected in vision-and-language models such as CLIP and Stable Diffusion. Using zero-shot knowledge probing to investigate the inherent knowledge of these models, we find strong evidence that they do show this pattern, paralleling the well-known kiki-bouba effect in psycholinguistics. Our work provides a novel method for demonstrating sound symbolism and understanding its nature using computational tools. Our code will be made publicly available.