 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Context Limits: Subconscious Threads for Long-Horizon Reasoning
Jul 22, 2025To break the context limits of large language models (LLMs) that bottleneck reasoning accuracy and efficiency, we propose the Thread Inference Model (TIM), a family of LLMs trained for recursive and decompositional problem solving, and TIMRUN, an inference runtime enabling long-horizon structured reasoning beyond context limits. Together, TIM hosted on TIMRUN supports virtually unlimited working memory and multi-hop tool calls within a single language model inference, overcoming output limits, positional-embedding constraints, and GPU-memory bottlenecks. Performance is achieved by modeling natural language as reasoning trees measured by both length and depth instead of linear sequences. The reasoning trees consist of tasks with thoughts, recursive subtasks, and conclusions based on the concept we proposed in Schroeder et al, 2025. During generation, we maintain a working memory that retains only the key-value states of the most relevant context tokens, selected by a rule-based subtask-pruning mechanism, enabling reuse of positional embeddings and GPU memory pages throughout reasoning. Experimental results show that our system sustains high inference throughput, even when manipulating up to 90% of the KV cache in GPU memory. It also delivers accurate reasoning on mathematical tasks and handles information retrieval challenges that require long-horizon reasoning and multi-hop tool use.
Overflow Prevention Enhances Long-Context Recurrent LLMs
May 12, 2025A recent trend in LLMs is developing recurrent sub-quadratic models that improve long-context processing efficiency. We investigate leading large long-context models, focusing on how their fixed-size recurrent memory affects their performance. Our experiments reveal that, even when these models are trained for extended contexts, their use of long contexts remains underutilized. Specifically, we demonstrate that a chunk-based inference procedure, which identifies and processes only the most relevant portion of the input can mitigate recurrent memory failures and be effective for many long-context tasks: On LongBench, our method improves the overall performance of Falcon3-Mamba-Inst-7B by 14%, Falcon-Mamba-Inst-7B by 28%, RecurrentGemma-IT-9B by 50%, and RWKV6-Finch-7B by 51%. Surprisingly, this simple approach also leads to state-of-the-art results in the challenging LongBench v2 benchmark, showing competitive performance with equivalent size Transformers. Furthermore, our findings raise questions about whether recurrent models genuinely exploit long-range dependencies, as our single-chunk strategy delivers stronger performance - even in tasks that presumably require cross-context relations.
DeciMamba: Exploring the Length Extrapolation Potential of Mamba
Jun 20, 2024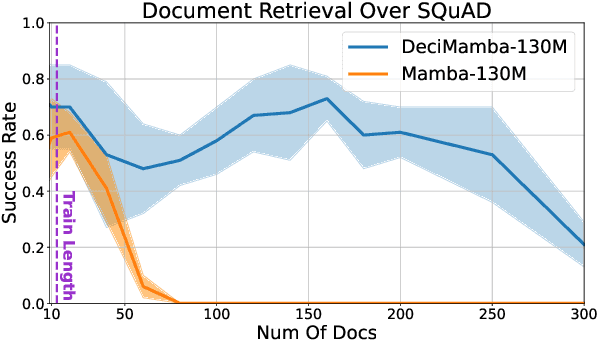

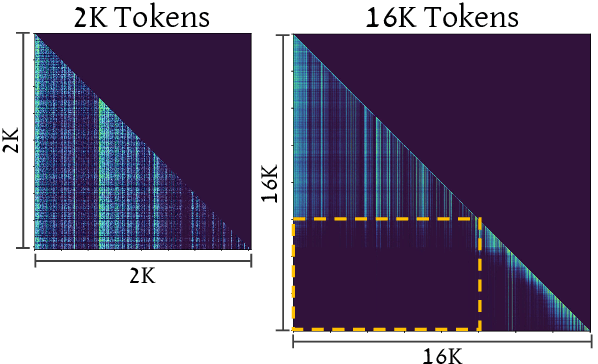
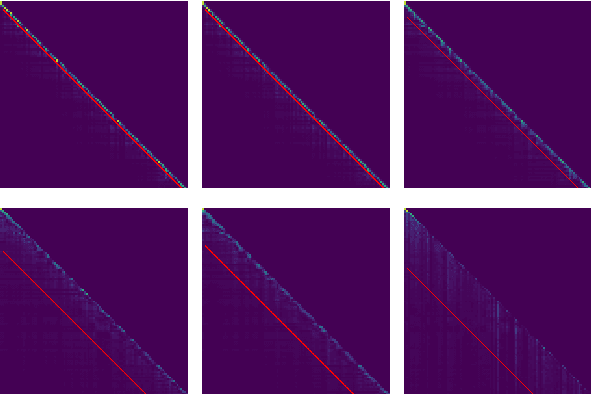
Long-range sequence processing poses a significant challenge for Transformers due to their quadratic complexity in input length. A promising alternative is Mamba, which demonstrates high performance and achieves Transformer-level capabilities while requiring substantially fewer computational resources. In this paper we explore the length-generalization capabilities of Mamba, which we find to be relatively limited. Through a series of visualizations and analyses we identify that the limitations arise from a restricted effective receptive field, dictated by the sequence length used during training. To address this constraint, we introduce DeciMamba, a context-extension method specifically designed for Mamba. This mechanism, built on top of a hidden filtering mechanism embedded within the S6 layer, enables the trained model to extrapolate well even without additional training. Empirical experiments over real-world long-range NLP tasks show that DeciMamba can extrapolate to context lengths that are 25x times longer than the ones seen during training, and does so without utilizing additional computational resources. We will release our code and models.
MOCHa: Multi-Objective Reinforcement Mitigating Caption Hallucinations
Dec 06, 2023



While recent years have seen rapid progress in image-conditioned text generation, image captioning still suffers from the fundamental issue of hallucinations, the generation of spurious details that cannot be inferred from the given image. Dedicated methods for reducing hallucinations in image captioning largely focus on closed-vocabulary object tokens, ignoring most types of hallucinations that occur in practice. In this work, we propose MOCHa, an approach that harnesses advancements in reinforcement learning (RL) to address the sequence-level nature of hallucinations in an open-world setup. To optimize for caption fidelity to the input image, we leverage ground-truth reference captions as proxies to measure the logical consistency of generated captions. However, optimizing for caption fidelity alone fails to preserve the semantic adequacy of generations; therefore, we propose a multi-objective reward function that jointly targets these qualities, without requiring any strong supervision. We demonstrate that these goals can be simultaneously optimized with our framework, enhancing performance for various captioning models of different scales. Our qualitative and quantitative results demonstrate MOCHa's superior performance across various established metrics. We also demonstrate the benefit of our method in the open-vocabulary setting. To this end, we contribute OpenCHAIR, a new benchmark for quantifying open-vocabulary hallucinations in image captioning models, constructed using generative foundation models. We will release our code, benchmark, and trained models.