 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomical Token Uncertainty for Transformer-Guided Active MRI Acquisition
Mar 23, 2026Full data acquisition in MRI is inherently slow, which limits clinical throughput and increases patient discomfort. Compressed Sensing MRI (CS-MRI) seeks to accelerate acquisition by reconstructing images from under-sampled k-space data, requiring both an optimal sampling trajectory and a high-fidelity reconstruction model. In this work, we propose a novel active sampling framework that leverages the inherent discrete structure of a pretrained medical image tokenizer and a latent transformer. By representing anatomy through a dictionary of quantized visual tokens, the model provides a well-defined probability distribution over the latent space. We utilize this distribution to derive a principled uncertainty measure via token entropy, which guides the active sampling process. We introduce two strategies to exploit this latent uncertainty: (1) Latent Entropy Selection (LES), projecting patch-wise token entropy into the $k$-space domain to identify informative sampling lines, and (2) Gradient-based Entropy Optimization (GEO), which identifies regions of maximum uncertainty reduction via the $k$-space gradient of a total latent entropy loss. We evaluate our framework on the fastMRI singlecoil Knee and Brain datasets at $\times 8$ and $\times 16$ acceleration. Our results demonstrate that our active policies outperform state-of-the-art baselines in perceptual metrics, and feature-based distances. Our code is available at https://github.com/levayz/TRUST-MRI.
DeciMamba: Exploring the Length Extrapolation Potential of Mamba
Jun 20, 2024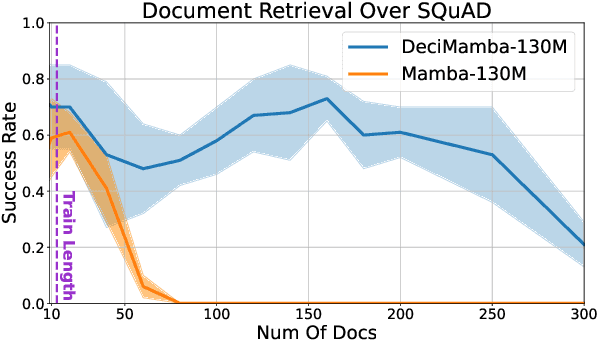

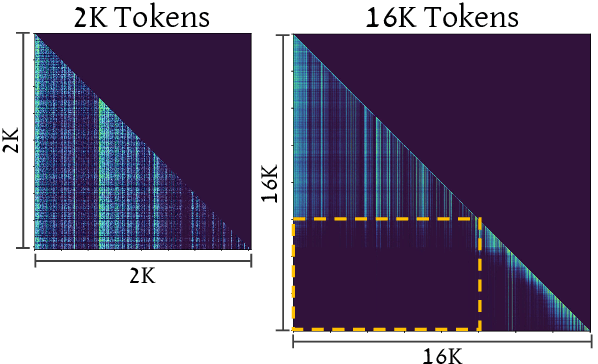
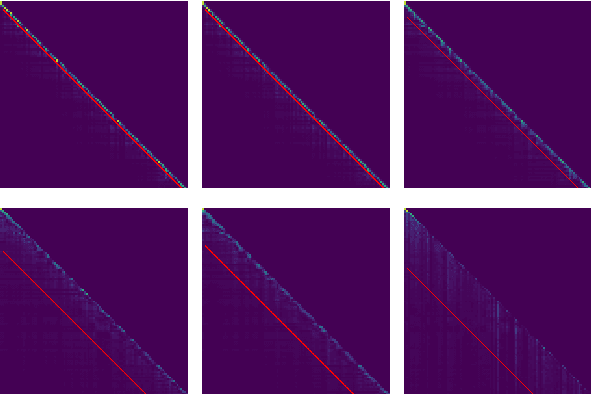
Long-range sequence processing poses a significant challenge for Transformers due to their quadratic complexity in input length. A promising alternative is Mamba, which demonstrates high performance and achieves Transformer-level capabilities while requiring substantially fewer computational resources. In this paper we explore the length-generalization capabilities of Mamba, which we find to be relatively limited. Through a series of visualizations and analyses we identify that the limitations arise from a restricted effective receptive field, dictated by the sequence length used during training. To address this constraint, we introduce DeciMamba, a context-extension method specifically designed for Mamba. This mechanism, built on top of a hidden filtering mechanism embedded within the S6 layer, enables the trained model to extrapolate well even without additional training. Empirical experiments over real-world long-range NLP tasks show that DeciMamba can extrapolate to context lengths that are 25x times longer than the ones seen during training, and does so without utilizing additional computational resources. We will release our code and models.
UDPM: Upsampling Diffusion Probabilistic Models
May 25, 2023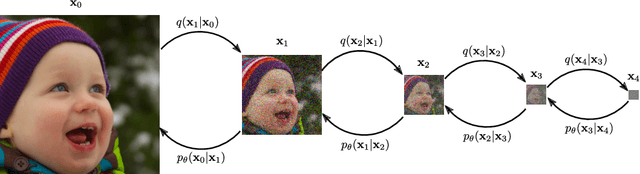

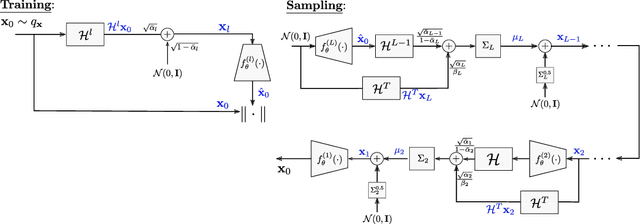

In recent years, Denoising Diffusion Probabilistic Models (DDPM) have caught significant attention. By composing a Markovian process that starts in the data domain and then gradually adds noise until reaching pure white noise, they achieve superior performance in learning data distributions. Yet, these models require a large number of diffusion steps to produce aesthetically pleasing samples, which is inefficient. In addition, unlike common generative adversarial networks, the latent space of diffusion models is not interpretable. In this work, we propose to generalize the denoising diffusion process into an Upsampling Diffusion Probabilistic Model (UDPM), in which we reduce the latent variable dimension in addition to the traditional noise level addition. As a result, we are able to sample images of size $256\times 256$ with only 7 diffusion steps, which is less than two orders of magnitude compared to standard DDPMs. We formally develop the Markovian diffusion processes of the UDPM, and demonstrate its generation capabilities on the popular FFHQ, LSUN horses, ImageNet, and AFHQv2 datasets. Another favorable property of UDPM is that it is very easy to interpolate its latent space, which is not the case with standard diffusion models. Our code is available online \url{https://github.com/shadyabh/UDPM}
VisDA 2022 Challenge: Domain Adaptation for Industrial Waste Sorting
Mar 26, 2023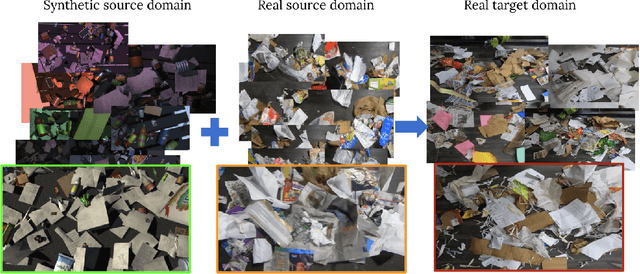
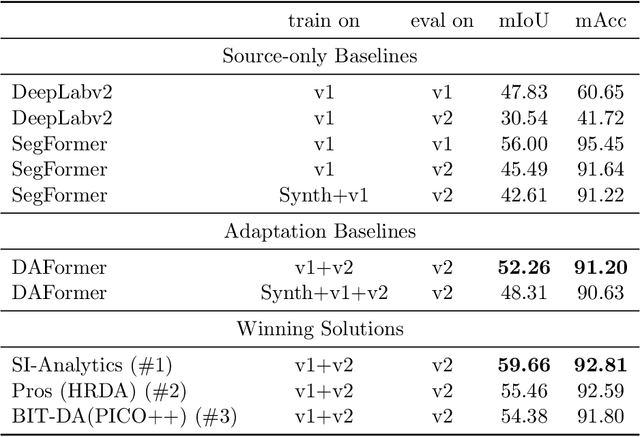

Label-efficient and reliable semantic segmentation is essential for many real-life applications, especially for industrial settings with high visual diversity, such as waste sorting. In industrial waste sorting, one of the biggest challenges is the extreme diversity of the input stream depending on factors like the location of the sorting facility, the equipment available in the facility, and the time of year, all of which significantly impact the composition and visual appearance of the waste stream. These changes in the data are called ``visual domains'', and label-efficient adaptation of models to such domains is needed for successful semantic segmentation of industrial waste. To test the abilities of computer vision models on this task, we present the VisDA 2022 Challenge on Domain Adaptation for Industrial Waste Sorting. Our challenge incorporates a fully-annotated waste sorting dataset, ZeroWaste, collected from two real material recovery facilities in different locations and seasons, as well as a novel procedurally generated synthetic waste sorting dataset, SynthWaste. In this competition, we aim to answer two questions: 1) can we leverage domain adaptation techniques to minimize the domain gap? and 2) can synthetic data augmentation improve performance on this task and help adapt to changing data distributions? The results of the competition show that industrial waste detection poses a real domain adaptation problem, that domain generalization techniques such as augmentations, ensembling, etc., improve the overall performance on the unlabeled target domain examples, and that leveraging synthetic data effectively remains an open problem. See https://ai.bu.edu/visda-2022/
ADIR: Adaptive Diffusion for Image Reconstruction
Dec 06, 2022
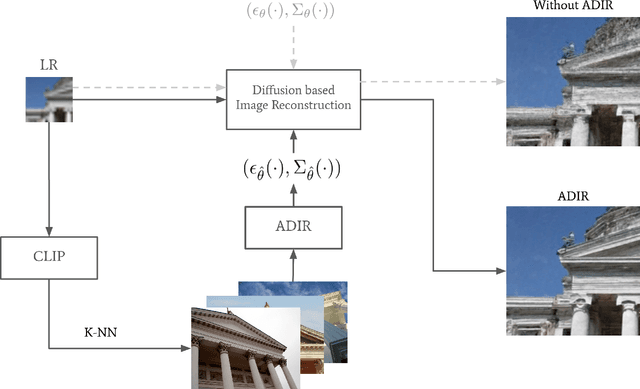

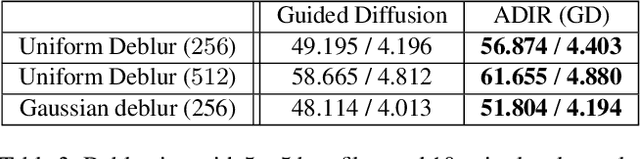
In recent years, denoising diffusion models have demonstrated outstanding image generation performance. The information on natural images captured by these models is useful for many image reconstruction applications, where the task is to restore a clean image from its degraded observations. In this work, we propose a conditional sampling scheme that exploits the prior learned by diffusion models while retaining agreement with the observations. We then combine it with a novel approach for adapting pretrained diffusion denoising networks to their input. We examine two adaption strategies: the first uses only the degraded image, while the second, which we advocate, is performed using images that are ``nearest neighbors'' of the degraded image, retrieved from a diverse dataset using an off-the-shelf visual-language model. To evaluate our method, we test it on two state-of-the-art publicly available diffusion models, Stable Diffusion and Guided Diffusion. We show that our proposed `adaptive diffusion for image reconstruction' (ADIR) approach achieves a significant improvement in the super-resolution, deblurring, and text-based editing tasks.
ProCST: Boosting Semantic Segmentation using Progressive Cyclic Style-Transfer
Apr 25, 2022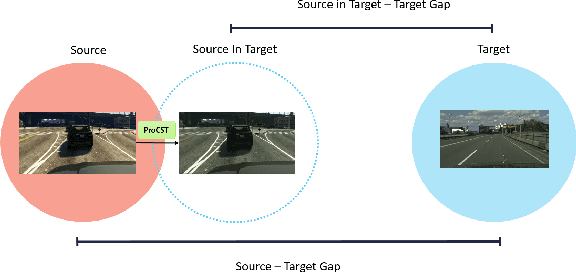
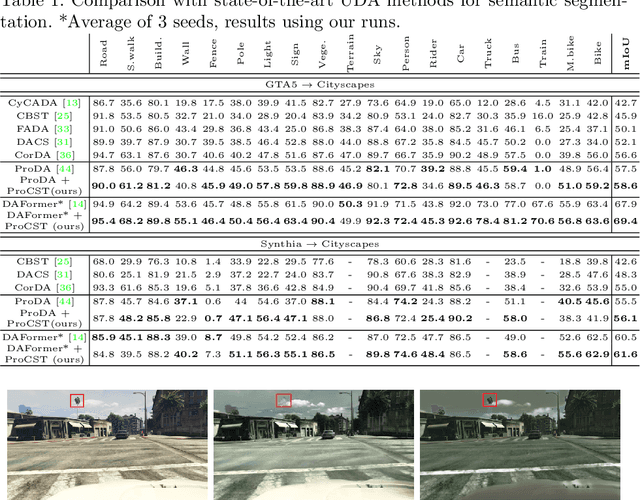
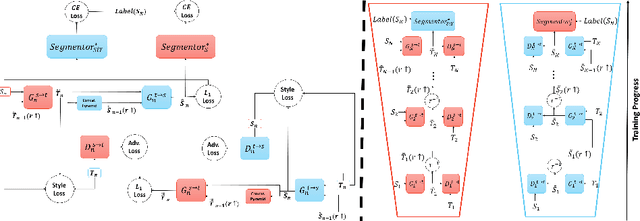

Using synthetic data for training neural networks that achieve good performance on real-world data is an important task as it has the potential to reduce the need for costly data annotation. Yet, a network that is trained on synthetic data alone does not perform well on real data due to the domain gap between the two. Reducing this gap, also known as domain adaptation, has been widely studied in recent years. In the unsupervised domain adaptation (UDA) framework, unlabeled real data is used during training with labeled synthetic data to obtain a neural network that performs well on real data. In this work, we focus on image data. For the semantic segmentation task, it has been shown that performing image-to-image translation from source to target, and then training a network for segmentation on source annotations - leads to poor results. Therefore a joint training of both is essential, which has been a common practice in many techniques. Yet, closing the large domain gap between the source and the target by directly performing the adaptation between the two is challenging. In this work, we propose a novel two-stage framework for improving domain adaptation techniques. In the first step, we progressively train a multi-scale neural network to perform an initial transfer between the source data to the target data. We denote the new transformed data as "Source in Target" (SiT). Then, we use the generated SiT data as the input to any standard UDA approach. This new data has a reduced domain gap from the desired target domain, and the applied UDA approach further closes the gap. We demonstrate the improvement achieved by our framework with two state-of-the-art methods for semantic segmentation, DAFormer and ProDA, on two UDA tasks, GTA5 to Cityscapes and Synthia to Cityscapes. Code and state-of-the-art checkpoints of ProCST+DAFormer are provided.
Unsupervised Domain Generalization by Learning a Bridge Across Domains
Dec 04, 2021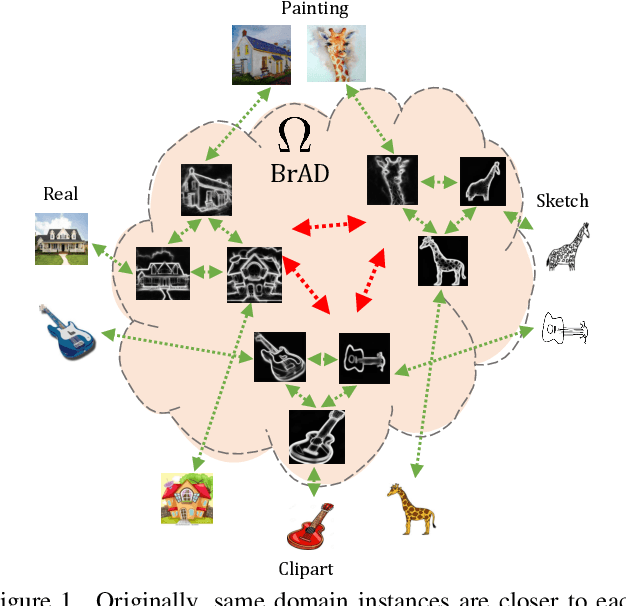
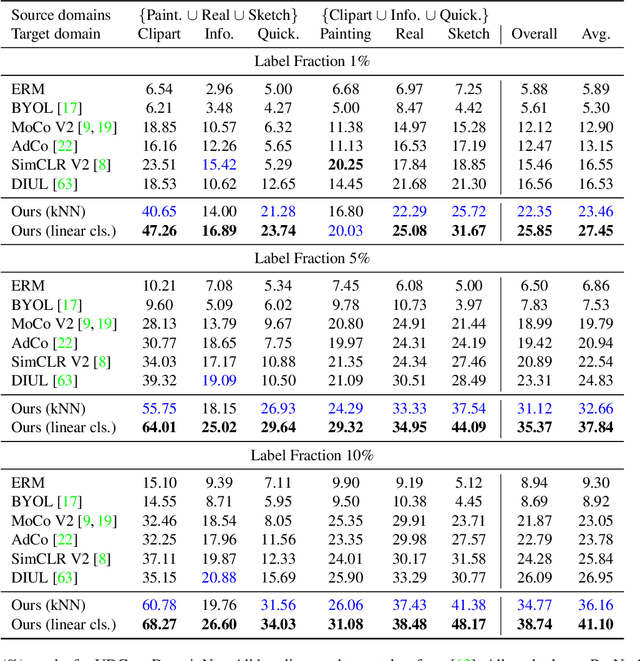
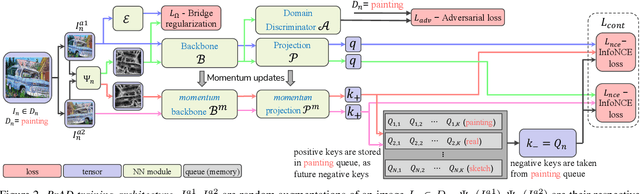
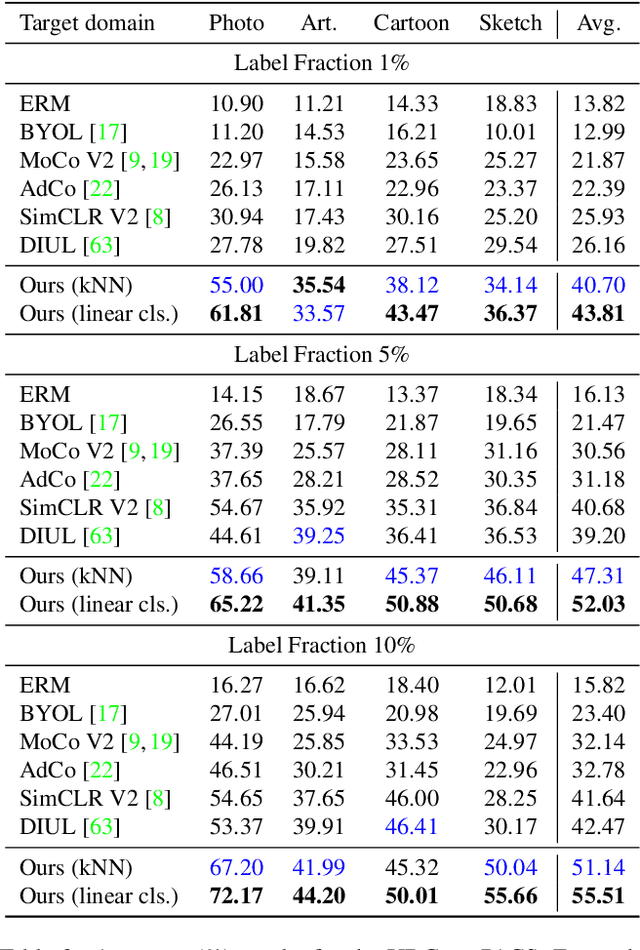
The ability to generalize learned representations across significantly different visual domains, such as between real photos, clipart, paintings, and sketches, is a fundamental capacity of the human visual system. In this paper, different from most cross-domain works that utilize some (or full) source domain supervision, we approach a relatively new and very practical Unsupervised Domain Generalization (UDG) setup of having no training supervision in neither source nor target domains. Our approach is based on self-supervised learning of a Bridge Across Domains (BrAD) - an auxiliary bridge domain accompanied by a set of semantics preserving visual (image-to-image) mappings to BrAD from each of the training domains. The BrAD and mappings to it are learned jointly (end-to-end) with a contrastive self-supervised representation model that semantically aligns each of the domains to its BrAD-projection, and hence implicitly drives all the domains (seen or unseen) to semantically align to each other. In this work, we show how using an edge-regularized BrAD our approach achieves significant gains across multiple benchmarks and a range of tasks, including UDG, Few-shot UDA, and unsupervised generalization across multi-domain datasets (including generalization to unseen domains and classes).
Image Restoration by Deep Projected GSURE
Feb 04, 2021



Ill-posed inverse problems appear in many image processing applications, such as deblurring and super-resolution. In recent years, solutions that are based on deep Convolutional Neural Networks (CNNs) have shown great promise. Yet, most of these techniques, which train CNNs using external data, are restricted to the observation models that have been used in the training phase. A recent alternative that does not have this drawback relies on learning the target image using internal learning. One such prominent example is the Deep Image Prior (DIP) technique that trains a network directly on the input image with a least-squares loss. In this paper, we propose a new image restoration framework that is based on minimizing a loss function that includes a "projected-version" of the Generalized SteinUnbiased Risk Estimator (GSURE) and parameterization of the latent image by a CNN. We demonstrate two ways to use our framework. In the first one, where no explicit prior is used, we show that the proposed approach outperforms other internal learning methods, such as DIP. In the second one, we show that our GSURE-based loss leads to improved performance when used within a plug-and-play priors scheme.