 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProCST: Boosting Semantic Segmentation using Progressive Cyclic Style-Transfer
Paper and Code
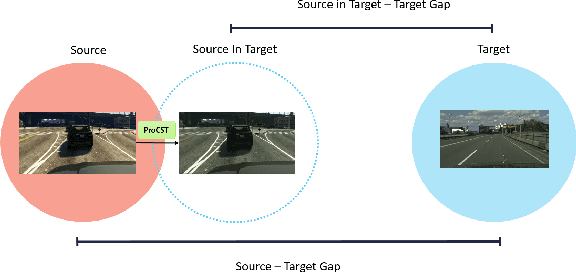
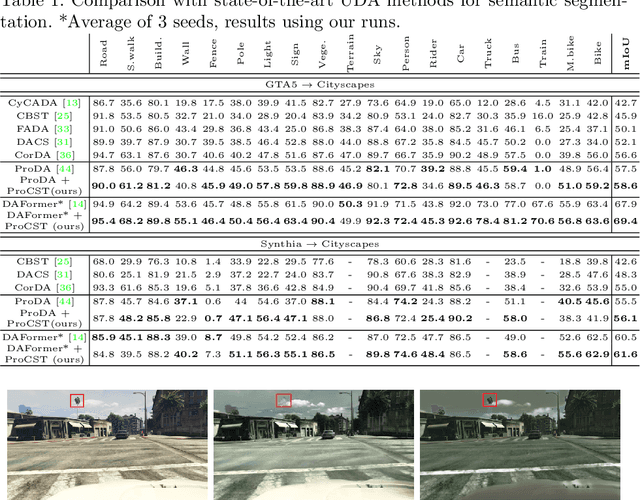
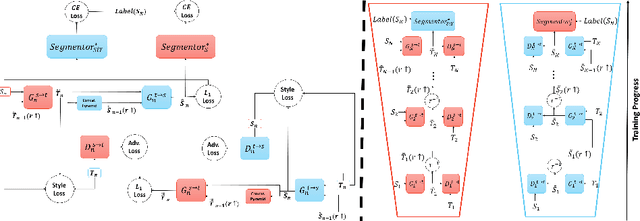

Using synthetic data for training neural networks that achieve good performance on real-world data is an important task as it has the potential to reduce the need for costly data annotation. Yet, a network that is trained on synthetic data alone does not perform well on real data due to the domain gap between the two. Reducing this gap, also known as domain adaptation, has been widely studied in recent years. In the unsupervised domain adaptation (UDA) framework, unlabeled real data is used during training with labeled synthetic data to obtain a neural network that performs well on real data. In this work, we focus on image data. For the semantic segmentation task, it has been shown that performing image-to-image translation from source to target, and then training a network for segmentation on source annotations - leads to poor results. Therefore a joint training of both is essential, which has been a common practice in many techniques. Yet, closing the large domain gap between the source and the target by directly performing the adaptation between the two is challenging. In this work, we propose a novel two-stage framework for improving domain adaptation techniques. In the first step, we progressively train a multi-scale neural network to perform an initial transfer between the source data to the target data. We denote the new transformed data as "Source in Target" (SiT). Then, we use the generated SiT data as the input to any standard UDA approach. This new data has a reduced domain gap from the desired target domain, and the applied UDA approach further closes the gap. We demonstrate the improvement achieved by our framework with two state-of-the-art methods for semantic segmentation, DAFormer and ProDA, on two UDA tasks, GTA5 to Cityscapes and Synthia to Cityscapes. Code and state-of-the-art checkpoints of ProCST+DAFormer are provided.