 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisDA 2022 Challenge: Domain Adaptation for Industrial Waste Sorting
Mar 26, 2023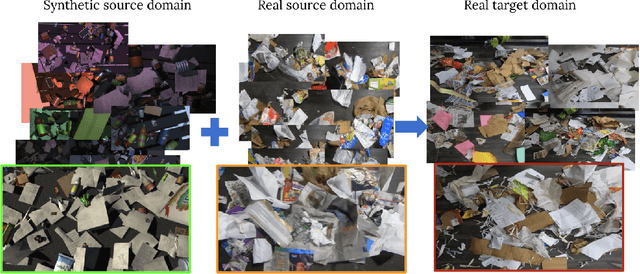
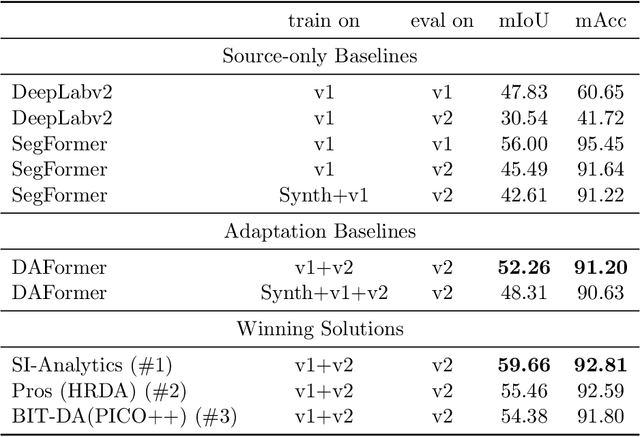
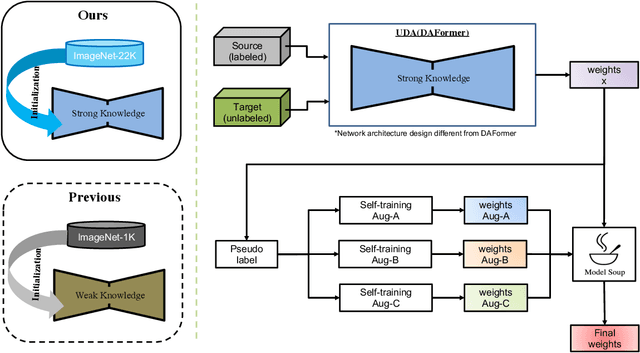

Label-efficient and reliable semantic segmentation is essential for many real-life applications, especially for industrial settings with high visual diversity, such as waste sorting. In industrial waste sorting, one of the biggest challenges is the extreme diversity of the input stream depending on factors like the location of the sorting facility, the equipment available in the facility, and the time of year, all of which significantly impact the composition and visual appearance of the waste stream. These changes in the data are called ``visual domains'', and label-efficient adaptation of models to such domains is needed for successful semantic segmentation of industrial waste. To test the abilities of computer vision models on this task, we present the VisDA 2022 Challenge on Domain Adaptation for Industrial Waste Sorting. Our challenge incorporates a fully-annotated waste sorting dataset, ZeroWaste, collected from two real material recovery facilities in different locations and seasons, as well as a novel procedurally generated synthetic waste sorting dataset, SynthWaste. In this competition, we aim to answer two questions: 1) can we leverage domain adaptation techniques to minimize the domain gap? and 2) can synthetic data augmentation improve performance on this task and help adapt to changing data distributions? The results of the competition show that industrial waste detection poses a real domain adaptation problem, that domain generalization techniques such as augmentations, ensembling, etc., improve the overall performance on the unlabeled target domain examples, and that leveraging synthetic data effectively remains an open problem. See https://ai.bu.edu/visda-2022/
ProCST: Boosting Semantic Segmentation using Progressive Cyclic Style-Transfer
Apr 25, 2022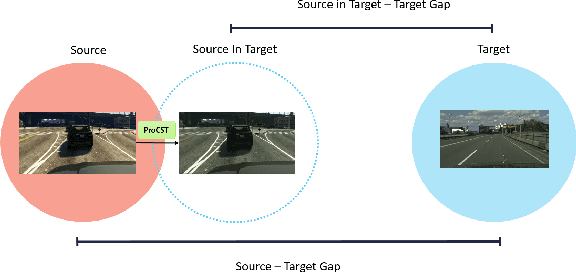
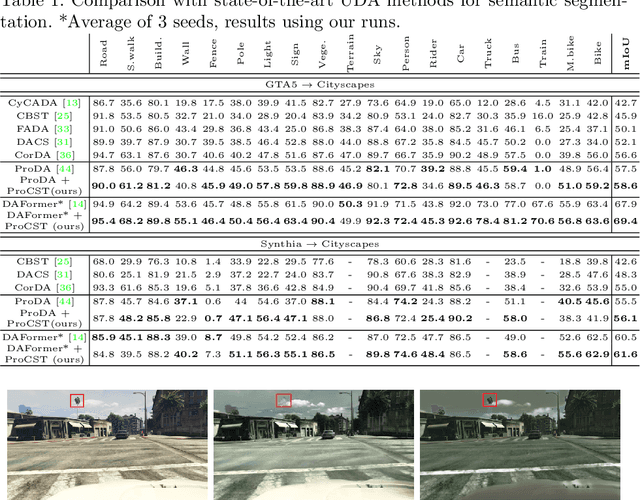
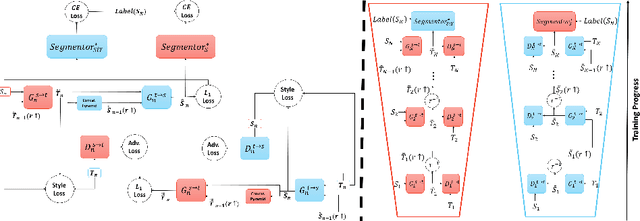

Using synthetic data for training neural networks that achieve good performance on real-world data is an important task as it has the potential to reduce the need for costly data annotation. Yet, a network that is trained on synthetic data alone does not perform well on real data due to the domain gap between the two. Reducing this gap, also known as domain adaptation, has been widely studied in recent years. In the unsupervised domain adaptation (UDA) framework, unlabeled real data is used during training with labeled synthetic data to obtain a neural network that performs well on real data. In this work, we focus on image data. For the semantic segmentation task, it has been shown that performing image-to-image translation from source to target, and then training a network for segmentation on source annotations - leads to poor results. Therefore a joint training of both is essential, which has been a common practice in many techniques. Yet, closing the large domain gap between the source and the target by directly performing the adaptation between the two is challenging. In this work, we propose a novel two-stage framework for improving domain adaptation techniques. In the first step, we progressively train a multi-scale neural network to perform an initial transfer between the source data to the target data. We denote the new transformed data as "Source in Target" (SiT). Then, we use the generated SiT data as the input to any standard UDA approach. This new data has a reduced domain gap from the desired target domain, and the applied UDA approach further closes the gap. We demonstrate the improvement achieved by our framework with two state-of-the-art methods for semantic segmentation, DAFormer and ProDA, on two UDA tasks, GTA5 to Cityscapes and Synthia to Cityscapes. Code and state-of-the-art checkpoints of ProCST+DAFormer are provided.