 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-axis Analysis of Image Manipulation Localization
May 19, 2026Advanced image editing software enables easy creation of highly convincing image manipulations, which has been made even more accessible in recent years due to advances in generative AI. Manipulated images, while often harmless, could spread misinformation, create false narratives, and influence people's opinions on important issues. Despite this growing threat, there is limited research on detecting advanced manipulations across different visual domains. Thus, we introduce Analysis Under Domain-shifts, qualIty, Type, and Size (AUDITS), a comprehensive benchmark designed for studying axes of analysis in image manipulation detection. AUDITS comprises over 530K images from two distinct sources (user and news photos). We curate our dataset to support analysis across multiple axes using recent diffusion-based inpaintings, spanning a diverse range of manipulation types and sizes. We conduct experiments under different types of domain shift to evaluate robustness of existing image manipulation detection methods. Our goal is to drive further research in this area by offering new insights that would help develop more reliable and generalizable image manipulation detection methods.
SAT: Spatial Aptitude Training for Multimodal Language Models
Dec 10, 2024



Spatial perception is a fundamental component of intelligence. While many studies highlight that large multimodal language models (MLMs) struggle to reason about space, they only test for static spatial reasoning, such as categorizing the relative positions of objects. Meanwhile, real-world deployment requires dynamic capabilities like perspective-taking and egocentric action recognition. As a roadmap to improving spatial intelligence, we introduce SAT, Spatial Aptitude Training, which goes beyond static relative object position questions to the more dynamic tasks. SAT contains 218K question-answer pairs for 22K synthetic scenes across a training and testing set. Generated using a photo-realistic physics engine, our dataset can be arbitrarily scaled and easily extended to new actions, scenes, and 3D assets. We find that even MLMs that perform relatively well on static questions struggle to accurately answer dynamic spatial questions. Further, we show that SAT instruction-tuning data improves not only dynamic spatial reasoning on SAT, but also zero-shot performance on existing real-image spatial benchmarks: $23\%$ on CVBench, $8\%$ on the harder BLINK benchmark, and $18\%$ on VSR. When instruction-tuned on SAT, our 13B model matches larger proprietary MLMs like GPT4-V and Gemini-3-1.0 in spatial reasoning. Our data/code is available at http://arijitray1993.github.io/SAT/ .
Learning to Compose SuperWeights for Neural Parameter Allocation Search
Dec 03, 2023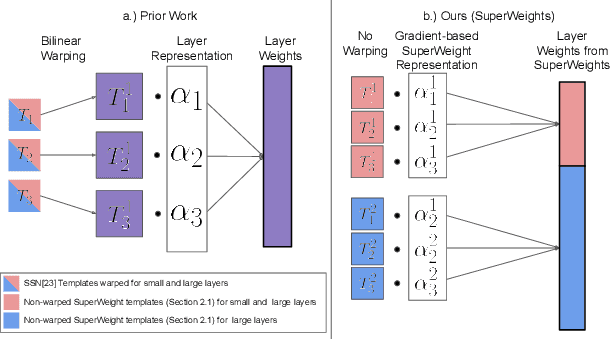
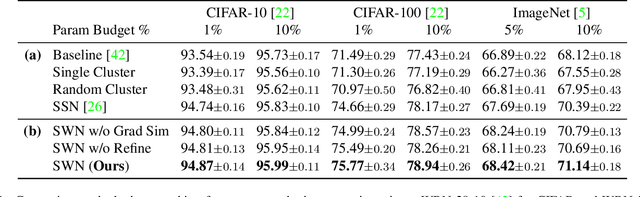
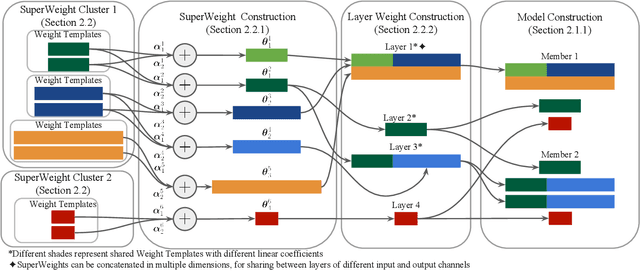
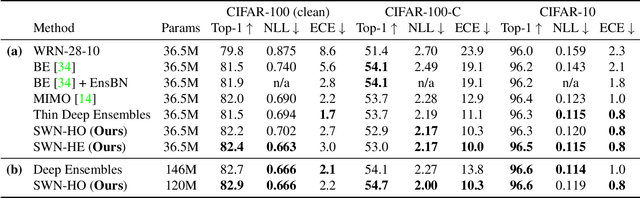
Neural parameter allocation search (NPAS) automates parameter sharing by obtaining weights for a network given an arbitrary, fixed parameter budget. Prior work has two major drawbacks we aim to address. First, there is a disconnect in the sharing pattern between the search and training steps, where weights are warped for layers of different sizes during the search to measure similarity, but not during training, resulting in reduced performance. To address this, we generate layer weights by learning to compose sets of SuperWeights, which represent a group of trainable parameters. These SuperWeights are created to be large enough so they can be used to represent any layer in the network, but small enough that they are computationally efficient. The second drawback we address is the method of measuring similarity between shared parameters. Whereas prior work compared the weights themselves, we argue this does not take into account the amount of conflict between the shared weights. Instead, we use gradient information to identify layers with shared weights that wish to diverge from each other. We demonstrate that our SuperWeight Networks consistently boost performance over the state-of-the-art on the ImageNet and CIFAR datasets in the NPAS setting. We further show that our approach can generate parameters for many network architectures using the same set of weights. This enables us to support tasks like efficient ensembling and anytime prediction, outperforming fully-parameterized ensembles with 17% fewer parameters.
Lasagna: Layered Score Distillation for Disentangled Object Relighting
Nov 30, 2023



Professional artists, photographers, and other visual content creators use object relighting to establish their photo's desired effect. Unfortunately, manual tools that allow relighting have a steep learning curve and are difficult to master. Although generative editing methods now enable some forms of image editing, relighting is still beyond today's capabilities; existing methods struggle to keep other aspects of the image -- colors, shapes, and textures -- consistent after the edit. We propose Lasagna, a method that enables intuitive text-guided relighting control. Lasagna learns a lighting prior by using score distillation sampling to distill the prior of a diffusion model, which has been finetuned on synthetic relighting data. To train Lasagna, we curate a new synthetic dataset ReLiT, which contains 3D object assets re-lit from multiple light source locations. Despite training on synthetic images, quantitative results show that Lasagna relights real-world images while preserving other aspects of the input image, outperforming state-of-the-art text-guided image editing methods. Lasagna enables realistic and controlled results on natural images and digital art pieces and is preferred by humans over other methods in over 91% of cases. Finally, we demonstrate the versatility of our learning objective by extending it to allow colorization, another form of image editing.
VisDA 2022 Challenge: Domain Adaptation for Industrial Waste Sorting
Mar 26, 2023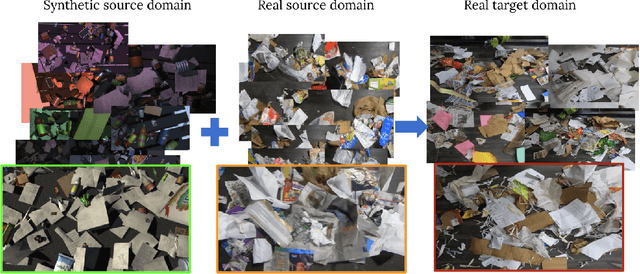
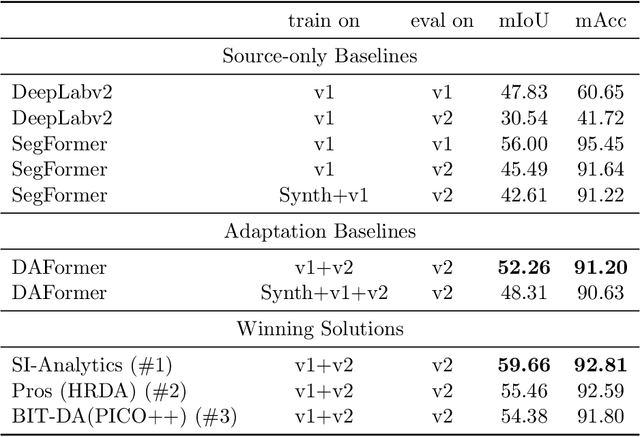

Label-efficient and reliable semantic segmentation is essential for many real-life applications, especially for industrial settings with high visual diversity, such as waste sorting. In industrial waste sorting, one of the biggest challenges is the extreme diversity of the input stream depending on factors like the location of the sorting facility, the equipment available in the facility, and the time of year, all of which significantly impact the composition and visual appearance of the waste stream. These changes in the data are called ``visual domains'', and label-efficient adaptation of models to such domains is needed for successful semantic segmentation of industrial waste. To test the abilities of computer vision models on this task, we present the VisDA 2022 Challenge on Domain Adaptation for Industrial Waste Sorting. Our challenge incorporates a fully-annotated waste sorting dataset, ZeroWaste, collected from two real material recovery facilities in different locations and seasons, as well as a novel procedurally generated synthetic waste sorting dataset, SynthWaste. In this competition, we aim to answer two questions: 1) can we leverage domain adaptation techniques to minimize the domain gap? and 2) can synthetic data augmentation improve performance on this task and help adapt to changing data distributions? The results of the competition show that industrial waste detection poses a real domain adaptation problem, that domain generalization techniques such as augmentations, ensembling, etc., improve the overall performance on the unlabeled target domain examples, and that leveraging synthetic data effectively remains an open problem. See https://ai.bu.edu/visda-2022/
MaskSketch: Unpaired Structure-guided Masked Image Generation
Feb 10, 2023
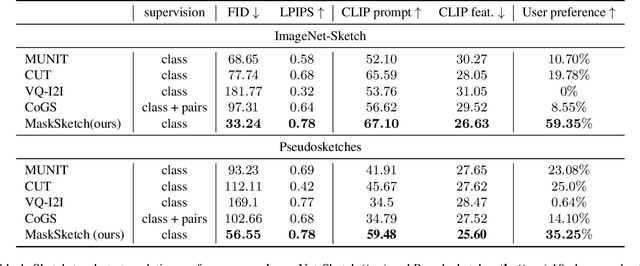

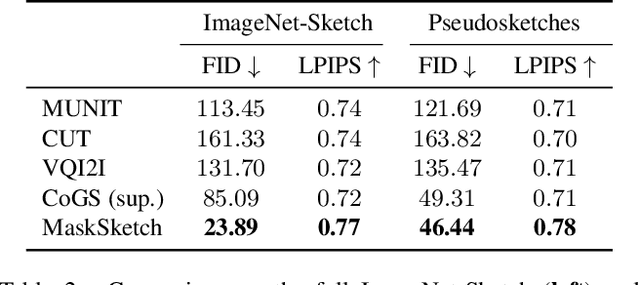
Recent conditional image generation methods produce images of remarkable diversity, fidelity and realism. However, the majority of these methods allow conditioning only on labels or text prompts, which limits their level of control over the generation result. In this paper, we introduce MaskSketch, an image generation method that allows spatial conditioning of the generation result using a guiding sketch as an extra conditioning signal during sampling. MaskSketch utilizes a pre-trained masked generative transformer, requiring no model training or paired supervision, and works with input sketches of different levels of abstraction. We show that intermediate self-attention maps of a masked generative transformer encode important structural information of the input image, such as scene layout and object shape, and we propose a novel sampling method based on this observation to enable structure-guided generation. Our results show that MaskSketch achieves high image realism and fidelity to the guiding structure. Evaluated on standard benchmark datasets, MaskSketch outperforms state-of-the-art methods for sketch-to-image translation, as well as unpaired image-to-image translation approaches.
Disentangled Unsupervised Image Translation via Restricted Information Flow
Nov 26, 2021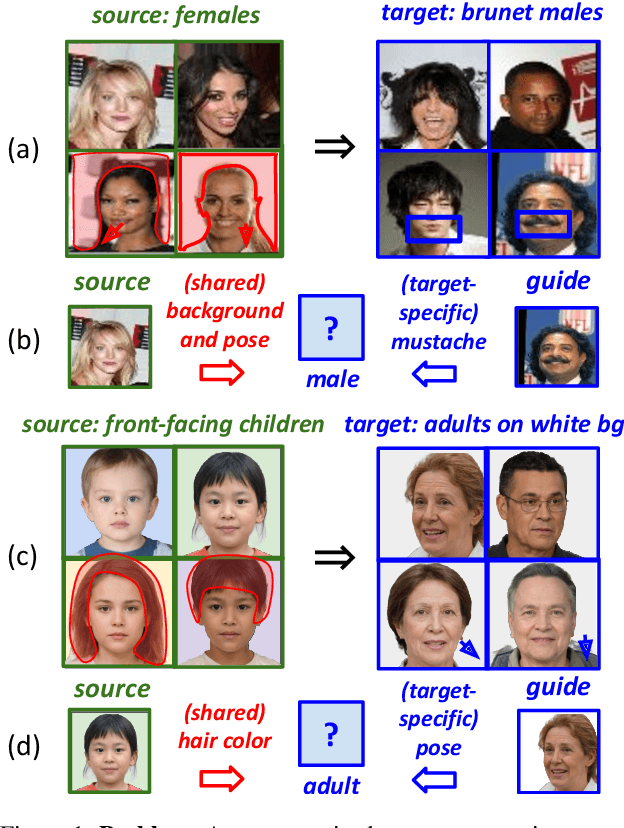
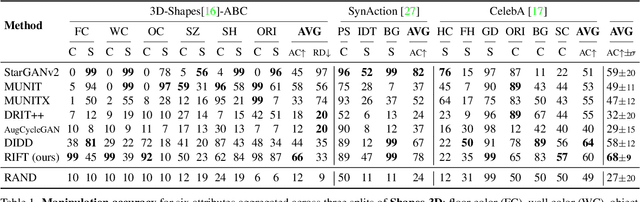
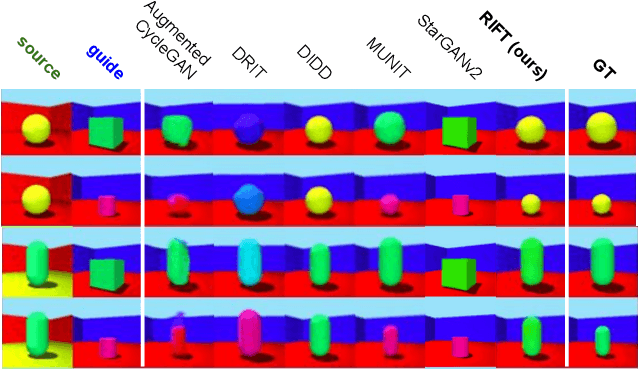
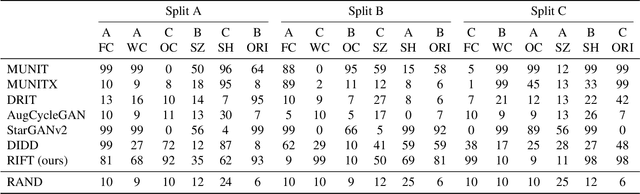
Unsupervised image-to-image translation methods aim to map images from one domain into plausible examples from another domain while preserving structures shared across two domains. In the many-to-many setting, an additional guidance example from the target domain is used to determine domain-specific attributes of the generated image. In the absence of attribute annotations, methods have to infer which factors are specific to each domain from data during training. Many state-of-art methods hard-code the desired shared-vs-specific split into their architecture, severely restricting the scope of the problem. In this paper, we propose a new method that does not rely on such inductive architectural biases, and infers which attributes are domain-specific from data by constraining information flow through the network using translation honesty losses and a penalty on the capacity of domain-specific embedding. We show that the proposed method achieves consistently high manipulation accuracy across two synthetic and one natural dataset spanning a wide variety of domain-specific and shared attributes.
VisDA-2021 Competition Universal Domain Adaptation to Improve Performance on Out-of-Distribution Data
Jul 23, 2021
Progress in machine learning is typically measured by training and testing a model on the same distribution of data, i.e., the same domain. This over-estimates future accuracy on out-of-distribution data. The Visual Domain Adaptation (VisDA) 2021 competition tests models' ability to adapt to novel test distributions and handle distributional shift. We set up unsupervised domain adaptation challenges for image classifiers and will evaluate adaptation to novel viewpoints, backgrounds, modalities and degradation in quality. Our challenge draws on large-scale publicly available datasets but constructs the evaluation across domains, rather that the traditional in-domain bench-marking. Furthermore, we focus on the difficult "universal" setting where, in addition to input distribution drift, methods may encounter missing and/or novel classes in the target dataset. Performance will be measured using a rigorous protocol, comparing to state-of-the-art domain adaptation methods with the help of established metrics. We believe that the competition will encourage further improvement in machine learning methods' ability to handle realistic data in many deployment scenarios.
Compositional Models: Multi-Task Learning and Knowledge Transfer with Modular Networks
Jul 23, 2021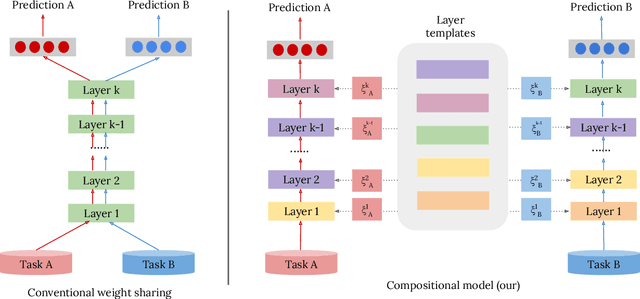
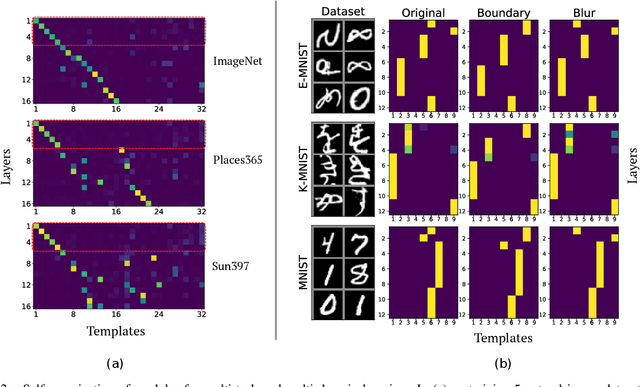

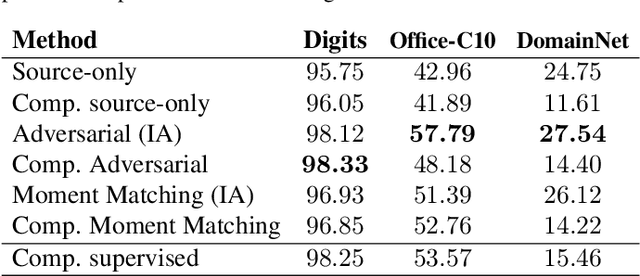
Conditional computation and modular networks have been recently proposed for multitask learning and other problems as a way to decompose problem solving into multiple reusable computational blocks. We propose a new approach for learning modular networks based on the isometric version of ResNet with all residual blocks having the same configuration and the same number of parameters. This architectural choice allows adding, removing and changing the order of residual blocks. In our method, the modules can be invoked repeatedly and allow knowledge transfer to novel tasks by adjusting the order of computation. This allows soft weight sharing between tasks with only a small increase in the number of parameters. We show that our method leads to interpretable self-organization of modules in case of multi-task learning, transfer learning and domain adaptation while achieving competitive results on those tasks. From practical perspective, our approach allows to: (a) reuse existing modules for learning new task by adjusting the computation order, (b) use it for unsupervised multi-source domain adaptation to illustrate that adaptation to unseen data can be achieved by only manipulating the order of pretrained modules, (c) show how our approach can be used to increase accuracy of existing architectures for image classification tasks such as ImageNet, without any parameter increase, by reusing the same block multiple times.
ZeroWaste Dataset: Towards Automated Waste Recycling
Jun 04, 2021


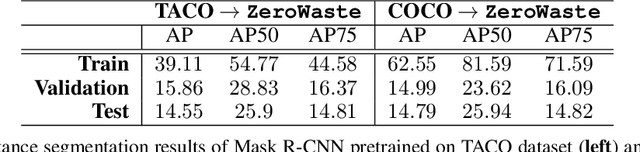
Less than 35% of recyclable waste is being actually recycled in the US, which leads to increased soil and sea pollution and is one of the major concerns of environmental researchers as well as the common public. At the heart of the problem is the inefficiencies of the waste sorting process (separating paper, plastic, metal, glass, etc.) due to the extremely complex and cluttered nature of the waste stream. Automated waste detection strategies have a great potential to enable more efficient, reliable and safer waste sorting practices, but the literature lacks comprehensive datasets and methodology for the industrial waste sorting solutions. In this paper, we take a step towards computer-aided waste detection and present the first in-the-wild industrial-grade waste detection and segmentation dataset, ZeroWaste. This dataset contains over1800fully segmented video frames collected from a real waste sorting plant along with waste material labels for training and evaluation of the segmentation methods, as well as over6000unlabeled frames that can be further used for semi-supervised and self-supervised learning techniques. ZeroWaste also provides frames of the conveyor belt before and after the sorting process, comprising a novel setup that can be used for weakly-supervised segmentation. We present baselines for fully-, semi- and weakly-supervised segmentation methods. Our experimental results demonstrate that state-of-the-art segmentation methods struggle to correctly detect and classify target objects which suggests the challenging nature of our proposed in-the-wild dataset. We believe that ZeroWastewill catalyze research in object detection and semantic segmentation in extreme clutter as well as applications in the recycling domain. Our project page can be found athttp://ai.bu.edu/zerowaste/.