 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Compose SuperWeights for Neural Parameter Allocation Search
Dec 03, 2023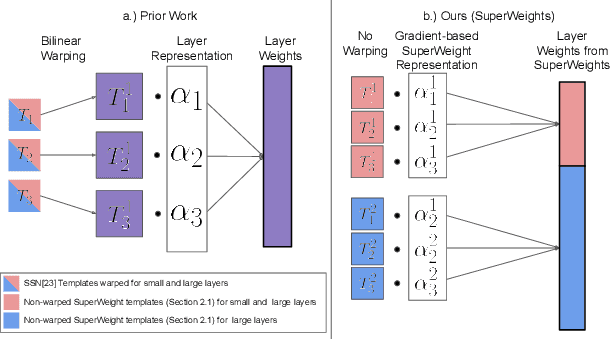
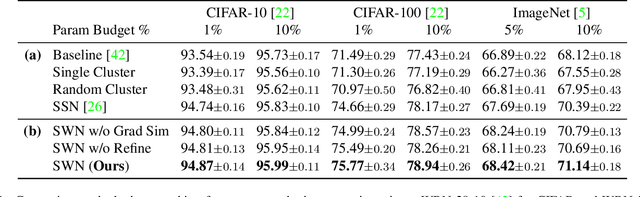
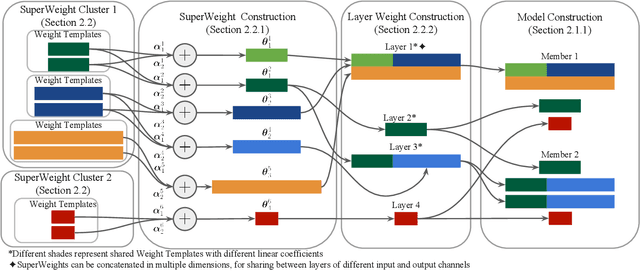
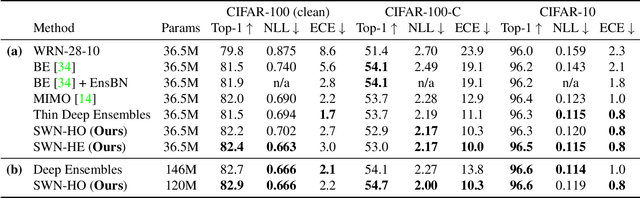
Neural parameter allocation search (NPAS) automates parameter sharing by obtaining weights for a network given an arbitrary, fixed parameter budget. Prior work has two major drawbacks we aim to address. First, there is a disconnect in the sharing pattern between the search and training steps, where weights are warped for layers of different sizes during the search to measure similarity, but not during training, resulting in reduced performance. To address this, we generate layer weights by learning to compose sets of SuperWeights, which represent a group of trainable parameters. These SuperWeights are created to be large enough so they can be used to represent any layer in the network, but small enough that they are computationally efficient. The second drawback we address is the method of measuring similarity between shared parameters. Whereas prior work compared the weights themselves, we argue this does not take into account the amount of conflict between the shared weights. Instead, we use gradient information to identify layers with shared weights that wish to diverge from each other. We demonstrate that our SuperWeight Networks consistently boost performance over the state-of-the-art on the ImageNet and CIFAR datasets in the NPAS setting. We further show that our approach can generate parameters for many network architectures using the same set of weights. This enables us to support tasks like efficient ensembling and anytime prediction, outperforming fully-parameterized ensembles with 17% fewer parameters.
MixtureGrowth: Growing Neural Networks by Recombining Learned Parameters
Nov 07, 2023



Most deep neural networks are trained under fixed network architectures and require retraining when the architecture changes. If expanding the network's size is needed, it is necessary to retrain from scratch, which is expensive. To avoid this, one can grow from a small network by adding random weights over time to gradually achieve the target network size. However, this naive approach falls short in practice as it brings too much noise to the growing process. Prior work tackled this issue by leveraging the already learned weights and training data for generating new weights through conducting a computationally expensive analysis step. In this paper, we introduce MixtureGrowth, a new approach to growing networks that circumvents the initialization overhead in prior work. Before growing, each layer in our model is generated with a linear combination of parameter templates. Newly grown layer weights are generated by using a new linear combination of existing templates for a layer. On one hand, these templates are already trained for the task, providing a strong initialization. On the other, the new coefficients provide flexibility for the added layer weights to learn something new. We show that our approach boosts top-1 accuracy over the state-of-the-art by 2-2.5% on CIFAR-100 and ImageNet datasets, while achieving comparable performance with fewer FLOPs to a larger network trained from scratch. Code is available at https://github.com/chaudatascience/mixturegrowth.
A needle-based deep-neural-network camera
Nov 14, 2020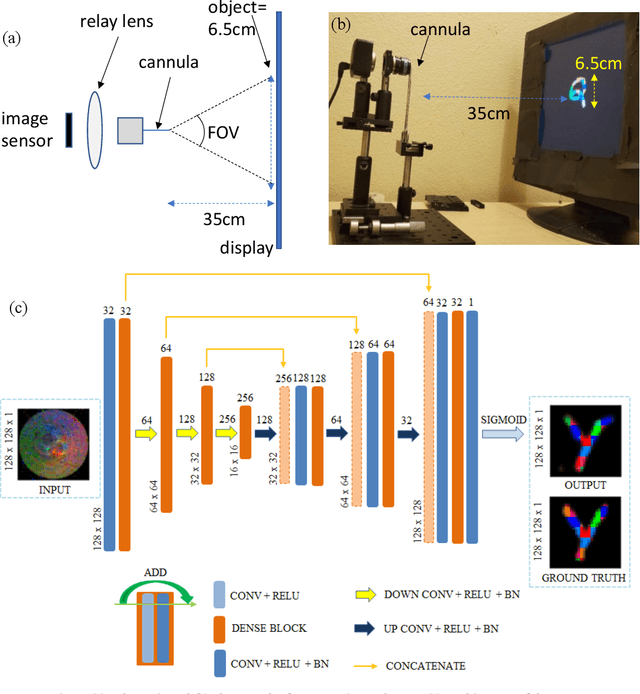

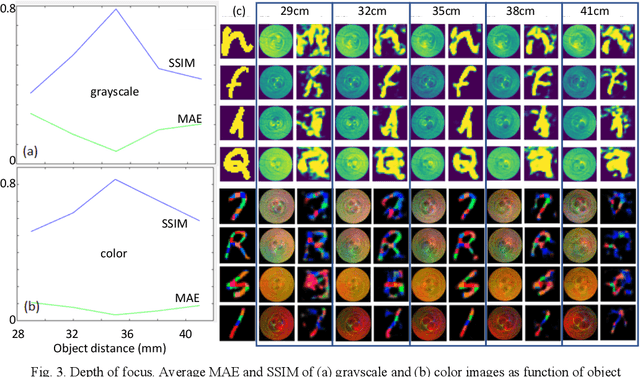
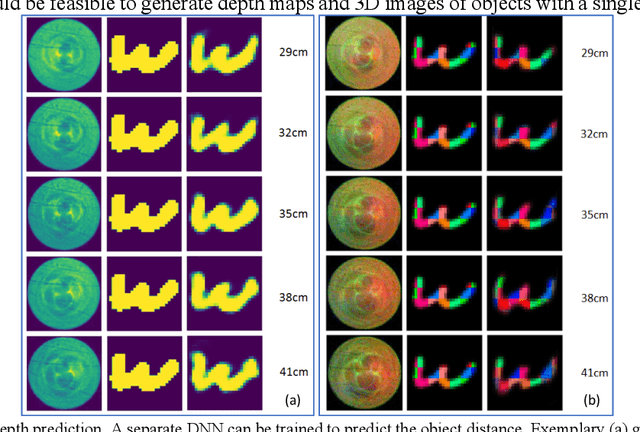
We experimentally demonstrate a camera whose primary optic is a cannula (diameter=0.22mm and length=12.5mm) that acts a lightpipe transporting light intensity from an object plane (35cm away) to its opposite end. Deep neural networks (DNNs) are used to reconstruct color and grayscale images with field of view of 180 and angular resolution of ~0.40. When trained on images with depth information, the DNN can create depth maps. Finally, we show DNN-based classification of the EMNIST dataset without and with image reconstructions. The former could be useful for imaging with enhanced privacy.
Classification of optics-free images with deep neural networks
Nov 10, 2020
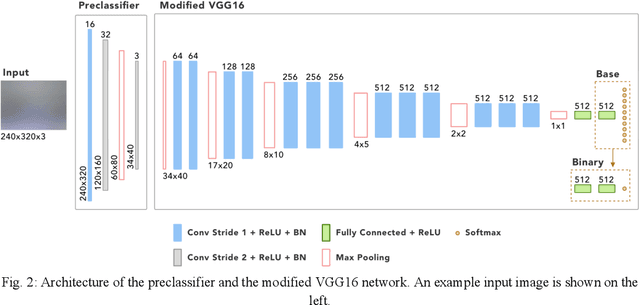
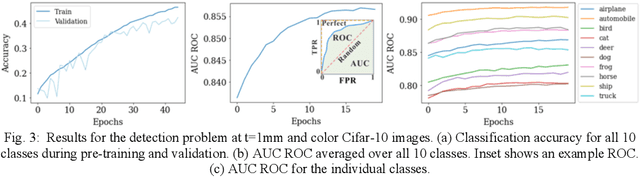
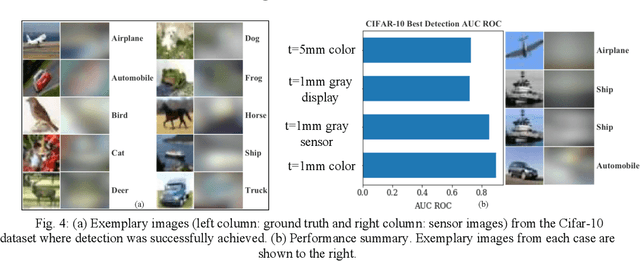
The thinnest possible camera is achieved by removing all optics, leaving only the image sensor. We train deep neural networks to perform multi-class detection and binary classification (with accuracy of 92%) on optics-free images without the need for anthropocentric image reconstructions. Inferencing from optics-free images has the potential for enhanced privacy and power efficiency.