 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHAMMI-75: pre-training multi-channel models with heterogeneous microscopy images
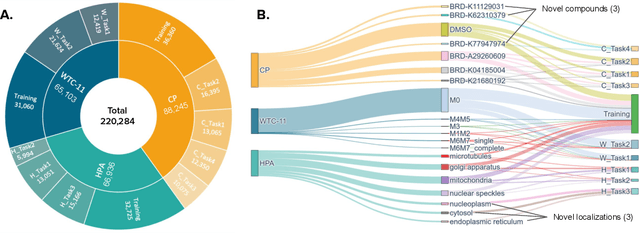
Dec 23, 2025Quantifying cell morphology using images and machine learning has proven to be a powerful tool to study the response of cells to treatments. However, models used to quantify cellular morphology are typically trained with a single microscopy imaging type. This results in specialized models that cannot be reused across biological studies because the technical specifications do not match (e.g., different number of channels), or because the target experimental conditions are out of distribution. Here, we present CHAMMI-75, an open access dataset of heterogeneous, multi-channel microscopy images from 75 diverse biological studies. We curated this resource from publicly available sources to investigate cellular morphology models that are channel-adaptive and can process any microscopy image type. Our experiments show that training with CHAMMI-75 can improve performance in multi-channel bioimaging tasks primarily because of its high diversity in microscopy modalities. This work paves the way to create the next generation of cellular morphology models for biological studies.
AutoEdit: Automatic Hyperparameter Tuning for Image Editing
Sep 18, 2025Recent advances in diffusion models have revolutionized text-guided image editing, yet existing editing methods face critical challenges in hyperparameter identification. To get the reasonable editing performance, these methods often require the user to brute-force tune multiple interdependent hyperparameters, such as inversion timesteps and attention modification, \textit{etc.} This process incurs high computational costs due to the huge hyperparameter search space. We consider searching optimal editing's hyperparameters as a sequential decision-making task within the diffusion denoising process. Specifically, we propose a reinforcement learning framework, which establishes a Markov Decision Process that dynamically adjusts hyperparameters across denoising steps, integrating editing objectives into a reward function. The method achieves time efficiency through proximal policy optimization while maintaining optimal hyperparameter configurations. Experiments demonstrate significant reduction in search time and computational overhead compared to existing brute-force approaches, advancing the practical deployment of a diffusion-based image editing framework in the real world.
ChA-MAEViT: Unifying Channel-Aware Masked Autoencoders and Multi-Channel Vision Transformers for Improved Cross-Channel Learning
Mar 25, 2025Prior work using Masked Autoencoders (MAEs) typically relies on random patch masking based on the assumption that images have significant redundancies across different channels, allowing for the reconstruction of masked content using cross-channel correlations. However, this assumption does not hold in Multi-Channel Imaging (MCI), where channels may provide complementary information with minimal feature overlap. Thus, these MAEs primarily learn local structures within individual channels from patch reconstruction, failing to fully leverage cross-channel interactions and limiting their MCI effectiveness. In this paper, we present ChA-MAEViT, an MAE-based method that enhances feature learning across MCI channels via four key strategies: (1) dynamic channel-patch masking, which compels the model to reconstruct missing channels in addition to masked patches, thereby enhancing cross-channel dependencies and improving robustness to varying channel configurations; (2) memory tokens, which serve as long-term memory aids to promote information sharing across channels, addressing the challenges of reconstructing structurally diverse channels; (3) hybrid token fusion module, which merges fine-grained patch tokens with a global class token to capture richer representations; and (4) Channel-Aware Decoder, a lightweight decoder utilizes channel tokens to effectively reconstruct image patches. Experiments on satellite and microscopy datasets, CHAMMI, JUMP-CP, and So2Sat, show that ChA-MAEViT significantly outperforms state-of-the-art MCI-ViTs by 3.0-21.5%, highlighting the importance of cross-channel interactions in MCI.
Personalized Large Vision-Language Models
Dec 23, 2024



The personalization model has gained significant attention in image generation yet remains underexplored for large vision-language models (LVLMs). Beyond generic ones, with personalization, LVLMs handle interactive dialogues using referential concepts (e.g., ``Mike and Susan are talking.'') instead of the generic form (e.g., ``a boy and a girl are talking.''), making the conversation more customizable and referentially friendly. In addition, PLVM is equipped to continuously add new concepts during a dialogue without incurring additional costs, which significantly enhances the practicality. PLVM proposes Aligner, a pre-trained visual encoder to align referential concepts with the queried images. During the dialogues, it extracts features of reference images with these corresponding concepts and recognizes them in the queried image, enabling personalization. We note that the computational cost and parameter count of the Aligner are negligible within the entire framework. With comprehensive qualitative and quantitative analyses, we reveal the effectiveness and superiority of PLVM.
Leveraging Large Language Models for Suicide Detection on Social Media with Limited Labels
Oct 06, 2024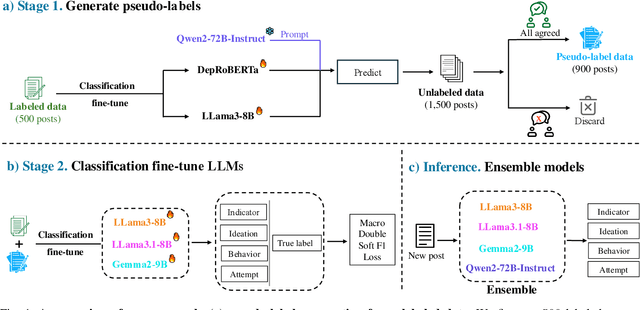
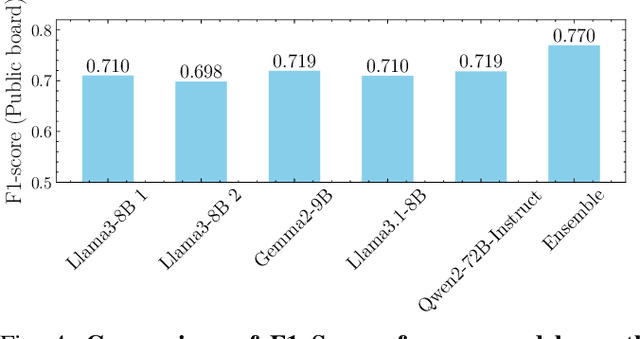
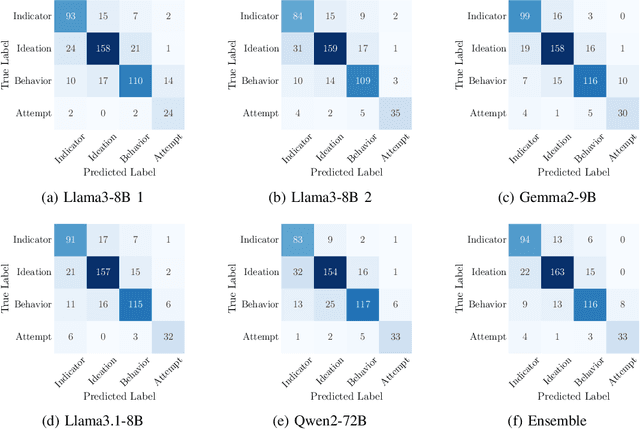
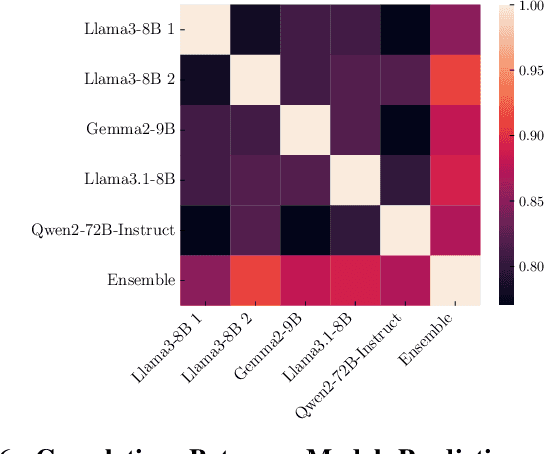
The increasing frequency of suicidal thoughts highlights the importance of early detection and intervention. Social media platforms, where users often share personal experiences and seek help, could be utilized to identify individuals at risk. However, the large volume of daily posts makes manual review impractical. This paper explores the use of Large Language Models (LLMs) to automatically detect suicidal content in text-based social media posts. We propose a novel method for generating pseudo-labels for unlabeled data by prompting LLMs, along with traditional classification fine-tuning techniques to enhance label accuracy. To create a strong suicide detection model, we develop an ensemble approach involving prompting with Qwen2-72B-Instruct, and using fine-tuned models such as Llama3-8B, Llama3.1-8B, and Gemma2-9B. We evaluate our approach on the dataset of the Suicide Ideation Detection on Social Media Challenge, a track of the IEEE Big Data 2024 Big Data Cup. Additionally, we conduct a comprehensive analysis to assess the impact of different models and fine-tuning strategies on detection performance. Experimental results show that the ensemble model significantly improves the detection accuracy, by 5% points compared with the individual models. It achieves a weight F1 score of 0.770 on the public test set, and 0.731 on the private test set, providing a promising solution for identifying suicidal content in social media. Our analysis shows that the choice of LLMs affects the prompting performance, with larger models providing better accuracy. Our code and checkpoints are publicly available at https://github.com/khanhvynguyen/Suicide_Detection_LLMs.
The Prompt Report: A Systematic Survey of Prompting Techniques
Jun 06, 2024Generative Artificial Intelligence (GenAI) systems are being increasingly deployed across all parts of industry and research settings. Developers and end users interact with these systems through the use of prompting or prompt engineering. While prompting is a widespread and highly researched concept, there exists conflicting terminology and a poor ontological understanding of what constitutes a prompt due to the area's nascency. This paper establishes a structured understanding of prompts, by assembling a taxonomy of prompting techniques and analyzing their use. We present a comprehensive vocabulary of 33 vocabulary terms, a taxonomy of 58 text-only prompting techniques, and 40 techniques for other modalities. We further present a meta-analysis of the entire literature on natural language prefix-prompting.
Enhancing Feature Diversity Boosts Channel-Adaptive Vision Transformers
May 26, 2024



Multi-Channel Imaging (MCI) contains an array of challenges for encoding useful feature representations not present in traditional images. For example, images from two different satellites may both contain RGB channels, but the remaining channels can be different for each imaging source. Thus, MCI models must support a variety of channel configurations at test time. Recent work has extended traditional visual encoders for MCI, such as Vision Transformers (ViT), by supplementing pixel information with an encoding representing the channel configuration. However, these methods treat each channel equally, i.e., they do not consider the unique properties of each channel type, which can result in needless and potentially harmful redundancies in the learned features. For example, if RGB channels are always present, the other channels can focus on extracting information that cannot be captured by the RGB channels. To this end, we propose DiChaViT, which aims to enhance the diversity in the learned features of MCI-ViT models. This is achieved through a novel channel sampling strategy that encourages the selection of more distinct channel sets for training. Additionally, we employ regularization and initialization techniques to increase the likelihood that new information is learned from each channel. Many of our improvements are architecture agnostic and could be incorporated into new architectures as they are developed. Experiments on both satellite and cell microscopy datasets, CHAMMI, JUMP-CP, and So2Sat, report DiChaViT yields a 1.5-5.0% gain over the state-of-the-art.
A Unified Framework for Connecting Noise Modeling to Boost Noise Detection
Nov 30, 2023



Noisy labels can impair model performance, making the study of learning with noisy labels an important topic. Two conventional approaches are noise modeling and noise detection. However, these two methods are typically studied independently, and there has been limited work on their collaboration. In this work, we explore the integration of these two approaches, proposing an interconnected structure with three crucial blocks: noise modeling, source knowledge identification, and enhanced noise detection using noise source-knowledge-integration methods. This collaboration structure offers advantages such as discriminating hard negatives and preserving genuinely clean labels that might be suspiciously noisy. Our experiments on four datasets, featuring three types of noise and different combinations of each block, demonstrate the efficacy of these components' collaboration. Our collaborative structure methods achieve up to a 10% increase in top-1 classification accuracy in synthesized noise datasets and 3-5% in real-world noisy datasets. The results also suggest that these components make distinct contributions to overall performance across various noise scenarios. These findings provide valuable insights for designing noisy label learning methods customized for specific noise scenarios in the future. Our code is accessible to the public.
MixtureGrowth: Growing Neural Networks by Recombining Learned Parameters
Nov 07, 2023



Most deep neural networks are trained under fixed network architectures and require retraining when the architecture changes. If expanding the network's size is needed, it is necessary to retrain from scratch, which is expensive. To avoid this, one can grow from a small network by adding random weights over time to gradually achieve the target network size. However, this naive approach falls short in practice as it brings too much noise to the growing process. Prior work tackled this issue by leveraging the already learned weights and training data for generating new weights through conducting a computationally expensive analysis step. In this paper, we introduce MixtureGrowth, a new approach to growing networks that circumvents the initialization overhead in prior work. Before growing, each layer in our model is generated with a linear combination of parameter templates. Newly grown layer weights are generated by using a new linear combination of existing templates for a layer. On one hand, these templates are already trained for the task, providing a strong initialization. On the other, the new coefficients provide flexibility for the added layer weights to learn something new. We show that our approach boosts top-1 accuracy over the state-of-the-art by 2-2.5% on CIFAR-100 and ImageNet datasets, while achieving comparable performance with fewer FLOPs to a larger network trained from scratch. Code is available at https://github.com/chaudatascience/mixturegrowth.
CHAMMI: A benchmark for channel-adaptive models in microscopy imaging
Oct 30, 2023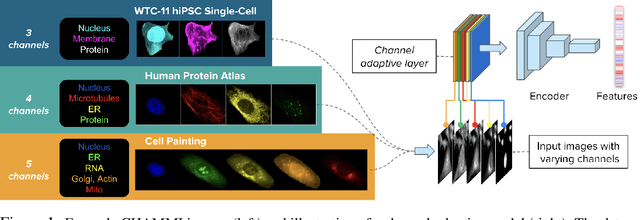
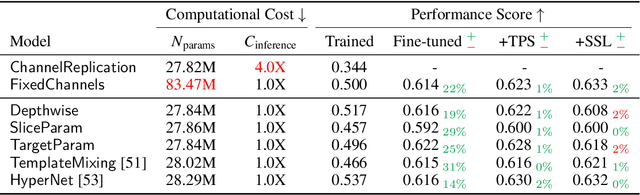

Most neural networks assume that input images have a fixed number of channels (three for RGB images). However, there are many settings where the number of channels may vary, such as microscopy images where the number of channels changes depending on instruments and experimental goals. Yet, there has not been a systemic attempt to create and evaluate neural networks that are invariant to the number and type of channels. As a result, trained models remain specific to individual studies and are hardly reusable for other microscopy settings. In this paper, we present a benchmark for investigating channel-adaptive models in microscopy imaging, which consists of 1) a dataset of varied-channel single-cell images, and 2) a biologically relevant evaluation framework. In addition, we adapted several existing techniques to create channel-adaptive models and compared their performance on this benchmark to fixed-channel, baseline models. We find that channel-adaptive models can generalize better to out-of-domain tasks and can be computationally efficient. We contribute a curated dataset (https://doi.org/10.5281/zenodo.7988357) and an evaluation API (https://github.com/broadinstitute/MorphEm.git) to facilitate objective comparisons in future research and applications.