 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb Artifact Attacks Disrupt Vision Language Models
Mar 17, 2025Vision-language models (VLMs) (e.g., CLIP, LLaVA) are trained on large-scale, lightly curated web datasets, leading them to learn unintended correlations between semantic concepts and unrelated visual signals. These associations degrade model accuracy by causing predictions to rely on incidental patterns rather than genuine visual understanding. Prior work has weaponized these correlations as an attack vector to manipulate model predictions, such as inserting a deceiving class text onto the image in a typographic attack. These attacks succeed due to VLMs' text-heavy bias-a result of captions that echo visible words rather than describing content. However, this attack has focused solely on text that matches the target class exactly, overlooking a broader range of correlations, including non-matching text and graphical symbols, which arise from the abundance of branding content in web-scale data. To address this gap, we introduce artifact-based attacks: a novel class of manipulations that mislead models using both non-matching text and graphical elements. Unlike typographic attacks, these artifacts are not predefined, making them harder to defend against but also more challenging to find. We address this by framing artifact attacks as a search problem and demonstrate their effectiveness across five datasets, with some artifacts reinforcing each other to reach 100% attack success rates. These attacks transfer across models with up to 90% effectiveness, making it possible to attack unseen models. To defend against these attacks, we extend prior work's artifact aware prompting to the graphical setting. We see a moderate reduction of success rates of up to 15% relative to standard prompts, suggesting a promising direction for enhancing model robustness.
OP-LoRA: The Blessing of Dimensionality
Dec 13, 2024



Low-rank adapters enable fine-tuning of large models with only a small number of parameters, thus reducing storage costs and minimizing the risk of catastrophic forgetting. However, they often pose optimization challenges, with poor convergence. To overcome these challenges, we introduce an over-parameterized approach that accelerates training without increasing inference costs. This method reparameterizes low-rank adaptation by employing a separate MLP and learned embedding for each layer. The learned embedding is input to the MLP, which generates the adapter parameters. Such overparamaterization has been shown to implicitly function as an adaptive learning rate and momentum, accelerating optimization. At inference time, the MLP can be discarded, leaving behind a standard low-rank adapter. To study the effect of MLP overparameterization on a small yet difficult proxy task, we implement it for matrix factorization, and find it achieves faster convergence and lower final loss. Extending this approach to larger-scale tasks, we observe consistent performance gains across domains. We achieve improvements in vision-language tasks and especially notable increases in image generation, with CMMD scores improving by up to 15 points.
Is Large-Scale Pretraining the Secret to Good Domain Generalization?
Dec 03, 2024Multi-Source Domain Generalization (DG) is the task of training on multiple source domains and achieving high classification performance on unseen target domains. Recent methods combine robust features from web-scale pretrained backbones with new features learned from source data, and this has dramatically improved benchmark results. However, it remains unclear if DG finetuning methods are becoming better over time, or if improved benchmark performance is simply an artifact of stronger pre-training. Prior studies have shown that perceptual similarity to pre-training data correlates with zero-shot performance, but we find the effect limited in the DG setting. Instead, we posit that having perceptually similar data in pretraining is not enough; and that it is how well these data were learned that determines performance. This leads us to introduce the Alignment Hypothesis, which states that the final DG performance will be high if and only if alignment of image and class label text embeddings is high. Our experiments confirm the Alignment Hypothesis is true, and we use it as an analysis tool of existing DG methods evaluated on DomainBed datasets by splitting evaluation data into In-pretraining (IP) and Out-of-pretraining (OOP). We show that all evaluated DG methods struggle on DomainBed-OOP, while recent methods excel on DomainBed-IP. Put together, our findings highlight the need for DG methods which can generalize beyond pretraining alignment.
SLANT: Spurious Logo ANalysis Toolkit
Jun 03, 2024


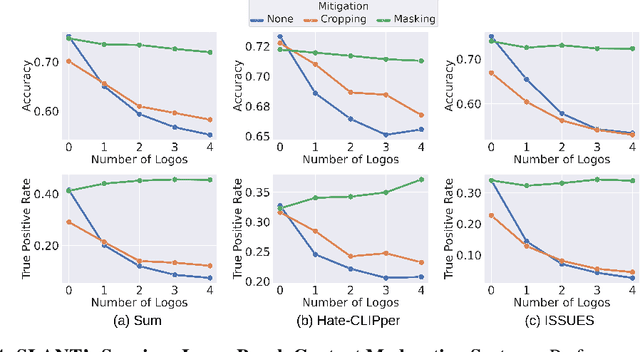
Online content is filled with logos, from ads and social media posts to website branding and product placements. Consequently, these logos are prevalent in the extensive web-scraped datasets used to pretrain Vision-Language Models, which are used for a wide array of tasks (content moderation, object classification). While these models have been shown to learn harmful correlations in various tasks, whether these correlations include logos remains understudied. Understanding this is especially important due to logos often being used by public-facing entities like brands and government agencies. To that end, we develop SLANT: A Spurious Logo ANalysis Toolkit. Our key finding is that some logos indeed lead to spurious incorrect predictions, for example, adding the Adidas logo to a photo of a person causes a model classify the person as greedy. SLANT contains a semi-automatic mechanism for mining such "spurious" logos. The mechanism consists of a comprehensive logo bank, CC12M-LogoBank, and an algorithm that searches the bank for logos that VLMs spuriously correlate with a user-provided downstream recognition target. We uncover various seemingly harmless logos that VL models correlate 1) with negative human adjectives 2) with the concept of `harmlessness'; causing models to misclassify harmful online content as harmless, and 3) with user-provided object concepts; causing lower recognition accuracy on ImageNet zero-shot classification. Furthermore, SLANT's logos can be seen as effective attacks against foundational models; an attacker could place a spurious logo on harmful content, causing the model to misclassify it as harmless. This threat is alarming considering the simplicity of logo attacks, increasing the attack surface of VL models. As a defense, we include in our Toolkit two effective mitigation strategies that seamlessly integrate with zero-shot inference of foundation models.
CLAMP: Contrastive LAnguage Model Prompt-tuning
Dec 04, 2023

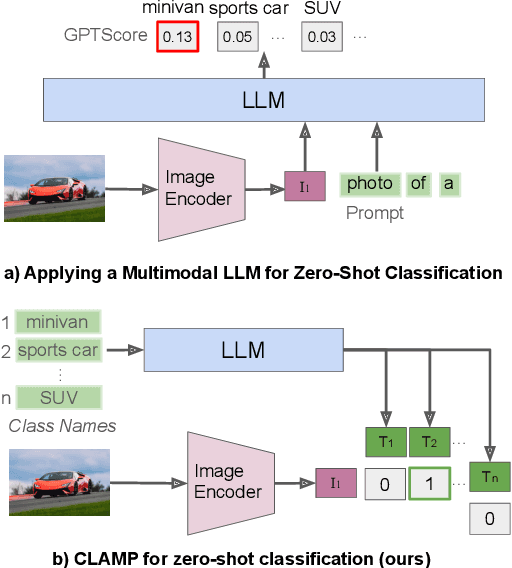

Large language models (LLMs) have emerged as powerful general-purpose interfaces for many machine learning problems. Recent work has adapted LLMs to generative visual tasks like image captioning, visual question answering, and visual chat, using a relatively small amount of instruction-tuning data. In this paper, we explore whether modern LLMs can also be adapted to classifying an image into a set of categories. First, we evaluate multimodal LLMs that are tuned for generative tasks on zero-shot image classification and find that their performance is far below that of specialized models like CLIP. We then propose an approach for light fine-tuning of LLMs using the same contrastive image-caption matching objective as CLIP. Our results show that LLMs can, indeed, achieve good image classification performance when adapted this way. Our approach beats state-of-the-art mLLMs by 13% and slightly outperforms contrastive learning with a custom text model, while also retaining the LLM's generative abilities. LLM initialization appears to particularly help classification in domains under-represented in the visual pre-training data.
Learning to Compose SuperWeights for Neural Parameter Allocation Search
Dec 03, 2023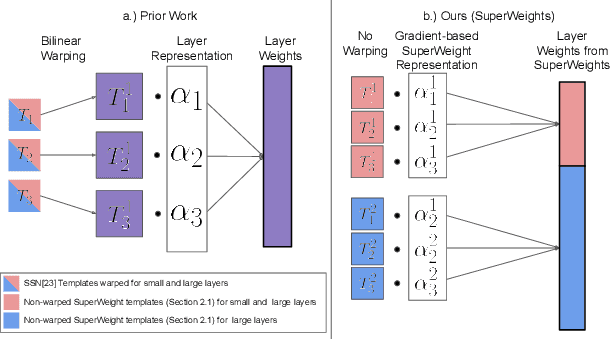
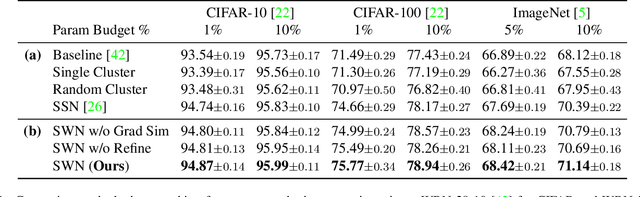
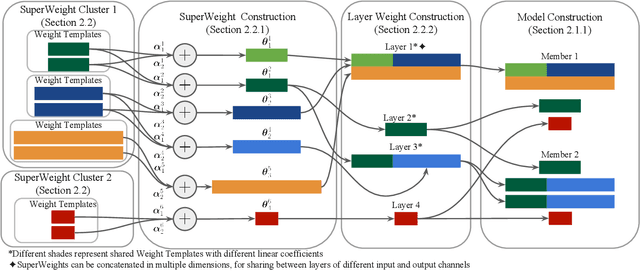
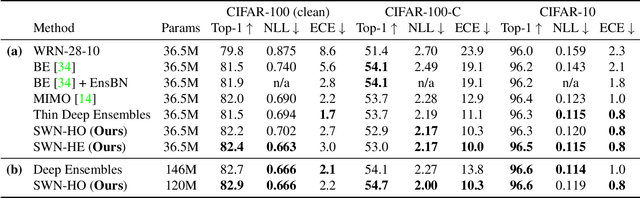
Neural parameter allocation search (NPAS) automates parameter sharing by obtaining weights for a network given an arbitrary, fixed parameter budget. Prior work has two major drawbacks we aim to address. First, there is a disconnect in the sharing pattern between the search and training steps, where weights are warped for layers of different sizes during the search to measure similarity, but not during training, resulting in reduced performance. To address this, we generate layer weights by learning to compose sets of SuperWeights, which represent a group of trainable parameters. These SuperWeights are created to be large enough so they can be used to represent any layer in the network, but small enough that they are computationally efficient. The second drawback we address is the method of measuring similarity between shared parameters. Whereas prior work compared the weights themselves, we argue this does not take into account the amount of conflict between the shared weights. Instead, we use gradient information to identify layers with shared weights that wish to diverge from each other. We demonstrate that our SuperWeight Networks consistently boost performance over the state-of-the-art on the ImageNet and CIFAR datasets in the NPAS setting. We further show that our approach can generate parameters for many network architectures using the same set of weights. This enables us to support tasks like efficient ensembling and anytime prediction, outperforming fully-parameterized ensembles with 17% fewer parameters.
MixtureGrowth: Growing Neural Networks by Recombining Learned Parameters
Nov 07, 2023



Most deep neural networks are trained under fixed network architectures and require retraining when the architecture changes. If expanding the network's size is needed, it is necessary to retrain from scratch, which is expensive. To avoid this, one can grow from a small network by adding random weights over time to gradually achieve the target network size. However, this naive approach falls short in practice as it brings too much noise to the growing process. Prior work tackled this issue by leveraging the already learned weights and training data for generating new weights through conducting a computationally expensive analysis step. In this paper, we introduce MixtureGrowth, a new approach to growing networks that circumvents the initialization overhead in prior work. Before growing, each layer in our model is generated with a linear combination of parameter templates. Newly grown layer weights are generated by using a new linear combination of existing templates for a layer. On one hand, these templates are already trained for the task, providing a strong initialization. On the other, the new coefficients provide flexibility for the added layer weights to learn something new. We show that our approach boosts top-1 accuracy over the state-of-the-art by 2-2.5% on CIFAR-100 and ImageNet datasets, while achieving comparable performance with fewer FLOPs to a larger network trained from scratch. Code is available at https://github.com/chaudatascience/mixturegrowth.
ERM++: An Improved Baseline for Domain Generalization
Apr 04, 2023



Multi-source Domain Generalization (DG) measures a classifier's ability to generalize to new distributions of data it was not trained on, given several training domains. While several multi-source DG methods have been proposed, they incur additional complexity during training by using domain labels. Recent work has shown that a well-tuned Empirical Risk Minimization (ERM) training procedure, that is simply minimizing the empirical risk on the source domains, can outperform most existing DG methods. We identify several key candidate techniques to further improve ERM performance, such as better utilization of training data, model parameter selection, and weight-space regularization. We call the resulting method ERM++, and show it significantly improves the performance of DG on five multi-source datasets by over 5% compared to standard ERM, and beats state-of-the-art despite being less computationally expensive. Additionally, we demonstrate the efficacy of ERM++ on the WILDS-FMOW dataset, a challenging DG benchmark. We hope that ERM++ becomes a strong baseline for future DG research. Code is released at https://github.com/piotr-teterwak/erm_plusplus.
Mind the Backbone: Minimizing Backbone Distortion for Robust Object Detection
Mar 26, 2023



Building object detectors that are robust to domain shifts is critical for real-world applications. Prior approaches fine-tune a pre-trained backbone and risk overfitting it to in-distribution (ID) data and distorting features useful for out-of-distribution (OOD) generalization. We propose to use Relative Gradient Norm (RGN) as a way to measure the vulnerability of a backbone to feature distortion, and show that high RGN is indeed correlated with lower OOD performance. Our analysis of RGN yields interesting findings: some backbones lose OOD robustness during fine-tuning, but others gain robustness because their architecture prevents the parameters from changing too much from the initial model. Given these findings, we present recipes to boost OOD robustness for both types of backbones. Specifically, we investigate regularization and architectural choices for minimizing gradient updates so as to prevent the tuned backbone from losing generalizable features. Our proposed techniques complement each other and show substantial improvements over baselines on diverse architectures and datasets.
VisDA 2022 Challenge: Domain Adaptation for Industrial Waste Sorting
Mar 26, 2023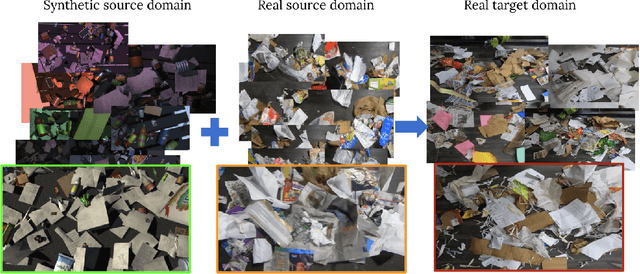
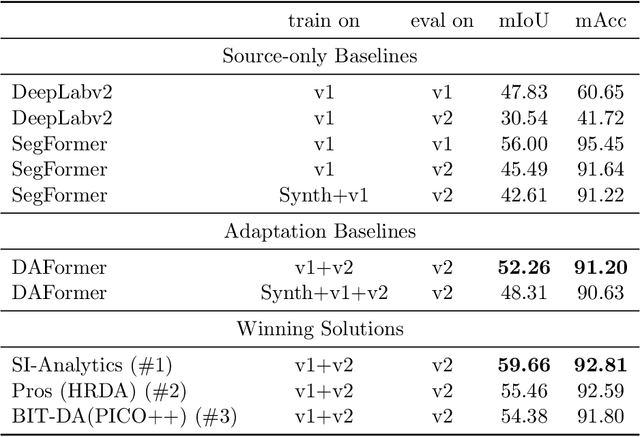

Label-efficient and reliable semantic segmentation is essential for many real-life applications, especially for industrial settings with high visual diversity, such as waste sorting. In industrial waste sorting, one of the biggest challenges is the extreme diversity of the input stream depending on factors like the location of the sorting facility, the equipment available in the facility, and the time of year, all of which significantly impact the composition and visual appearance of the waste stream. These changes in the data are called ``visual domains'', and label-efficient adaptation of models to such domains is needed for successful semantic segmentation of industrial waste. To test the abilities of computer vision models on this task, we present the VisDA 2022 Challenge on Domain Adaptation for Industrial Waste Sorting. Our challenge incorporates a fully-annotated waste sorting dataset, ZeroWaste, collected from two real material recovery facilities in different locations and seasons, as well as a novel procedurally generated synthetic waste sorting dataset, SynthWaste. In this competition, we aim to answer two questions: 1) can we leverage domain adaptation techniques to minimize the domain gap? and 2) can synthetic data augmentation improve performance on this task and help adapt to changing data distributions? The results of the competition show that industrial waste detection poses a real domain adaptation problem, that domain generalization techniques such as augmentations, ensembling, etc., improve the overall performance on the unlabeled target domain examples, and that leveraging synthetic data effectively remains an open problem. See https://ai.bu.edu/visda-2022/