 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher-Order Domain Generalization in Magnetic Resonance-Based Assessment of Alzheimer's Disease
Jan 04, 2026Despite progress in deep learning for Alzheimer's disease (AD) diagnostics, models trained on structural magnetic resonance imaging (sMRI) often do not perform well when applied to new cohorts due to domain shifts from varying scanners, protocols and patient demographics. AD, the primary driver of dementia, manifests through progressive cognitive and neuroanatomical changes like atrophy and ventricular expansion, making robust, generalizable classification essential for real-world use. While convolutional neural networks and transformers have advanced feature extraction via attention and fusion techniques, single-domain generalization (SDG) remains underexplored yet critical, given the fragmented nature of AD datasets. To bridge this gap, we introduce Extended MixStyle (EM), a framework for blending higher-order feature moments (skewness and kurtosis) to mimic diverse distributional variations. Trained on sMRI data from the National Alzheimer's Coordinating Center (NACC; n=4,647) to differentiate persons with normal cognition (NC) from those with mild cognitive impairment (MCI) or AD and tested on three unseen cohorts (total n=3,126), EM yields enhanced cross-domain performance, improving macro-F1 on average by 2.4 percentage points over state-of-the-art SDG benchmarks, underscoring its promise for invariant, reliable AD detection in heterogeneous real-world settings. The source code will be made available upon acceptance at https://github.com/zobia111/Extended-Mixstyle.
VisDA 2022 Challenge: Domain Adaptation for Industrial Waste Sorting
Mar 26, 2023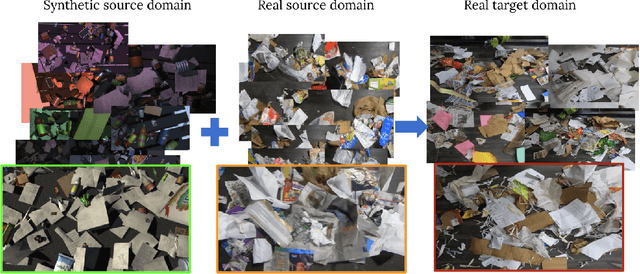
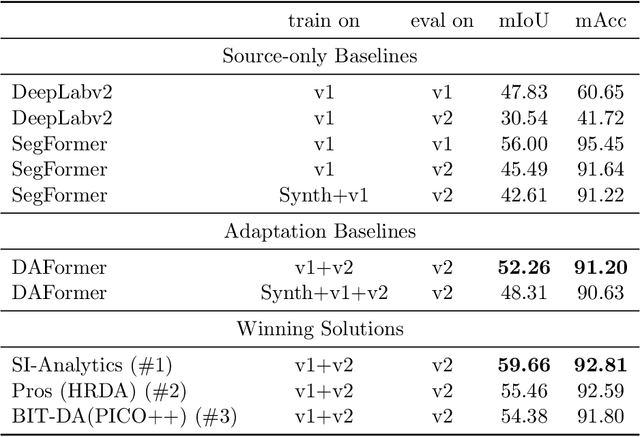
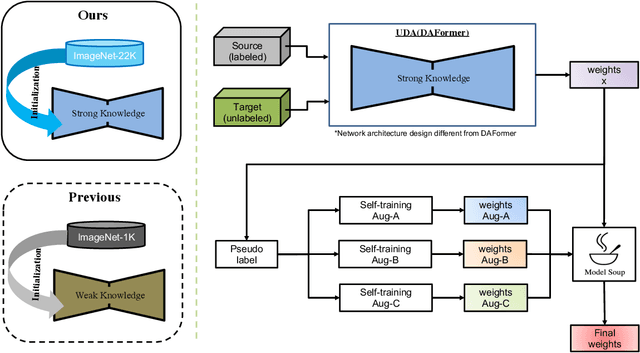

Label-efficient and reliable semantic segmentation is essential for many real-life applications, especially for industrial settings with high visual diversity, such as waste sorting. In industrial waste sorting, one of the biggest challenges is the extreme diversity of the input stream depending on factors like the location of the sorting facility, the equipment available in the facility, and the time of year, all of which significantly impact the composition and visual appearance of the waste stream. These changes in the data are called ``visual domains'', and label-efficient adaptation of models to such domains is needed for successful semantic segmentation of industrial waste. To test the abilities of computer vision models on this task, we present the VisDA 2022 Challenge on Domain Adaptation for Industrial Waste Sorting. Our challenge incorporates a fully-annotated waste sorting dataset, ZeroWaste, collected from two real material recovery facilities in different locations and seasons, as well as a novel procedurally generated synthetic waste sorting dataset, SynthWaste. In this competition, we aim to answer two questions: 1) can we leverage domain adaptation techniques to minimize the domain gap? and 2) can synthetic data augmentation improve performance on this task and help adapt to changing data distributions? The results of the competition show that industrial waste detection poses a real domain adaptation problem, that domain generalization techniques such as augmentations, ensembling, etc., improve the overall performance on the unlabeled target domain examples, and that leveraging synthetic data effectively remains an open problem. See https://ai.bu.edu/visda-2022/