 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisDA 2022 Challenge: Domain Adaptation for Industrial Waste Sorting
Mar 26, 2023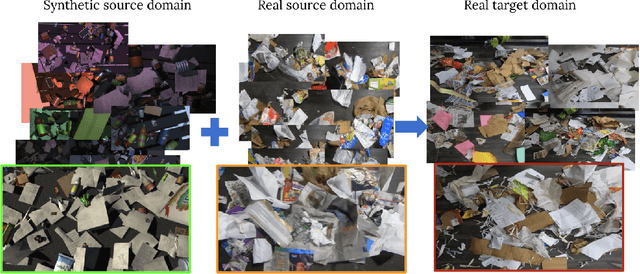
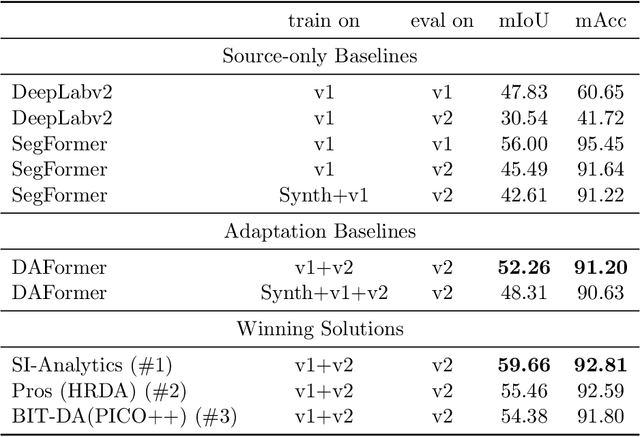
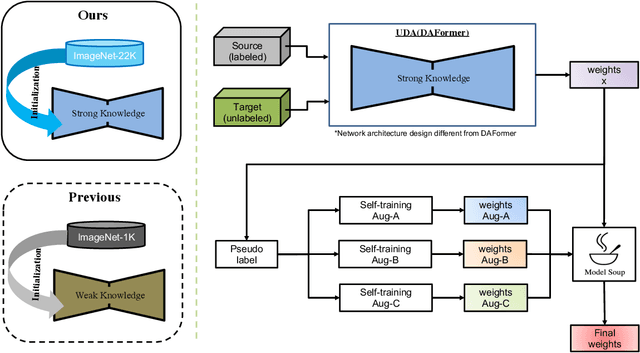

Label-efficient and reliable semantic segmentation is essential for many real-life applications, especially for industrial settings with high visual diversity, such as waste sorting. In industrial waste sorting, one of the biggest challenges is the extreme diversity of the input stream depending on factors like the location of the sorting facility, the equipment available in the facility, and the time of year, all of which significantly impact the composition and visual appearance of the waste stream. These changes in the data are called ``visual domains'', and label-efficient adaptation of models to such domains is needed for successful semantic segmentation of industrial waste. To test the abilities of computer vision models on this task, we present the VisDA 2022 Challenge on Domain Adaptation for Industrial Waste Sorting. Our challenge incorporates a fully-annotated waste sorting dataset, ZeroWaste, collected from two real material recovery facilities in different locations and seasons, as well as a novel procedurally generated synthetic waste sorting dataset, SynthWaste. In this competition, we aim to answer two questions: 1) can we leverage domain adaptation techniques to minimize the domain gap? and 2) can synthetic data augmentation improve performance on this task and help adapt to changing data distributions? The results of the competition show that industrial waste detection poses a real domain adaptation problem, that domain generalization techniques such as augmentations, ensembling, etc., improve the overall performance on the unlabeled target domain examples, and that leveraging synthetic data effectively remains an open problem. See https://ai.bu.edu/visda-2022/
ZeroWaste Dataset: Towards Automated Waste Recycling
Jun 04, 2021


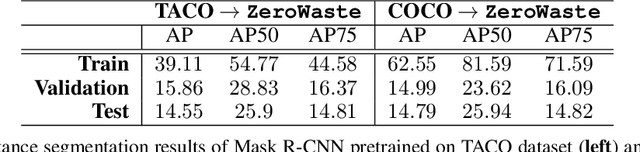
Less than 35% of recyclable waste is being actually recycled in the US, which leads to increased soil and sea pollution and is one of the major concerns of environmental researchers as well as the common public. At the heart of the problem is the inefficiencies of the waste sorting process (separating paper, plastic, metal, glass, etc.) due to the extremely complex and cluttered nature of the waste stream. Automated waste detection strategies have a great potential to enable more efficient, reliable and safer waste sorting practices, but the literature lacks comprehensive datasets and methodology for the industrial waste sorting solutions. In this paper, we take a step towards computer-aided waste detection and present the first in-the-wild industrial-grade waste detection and segmentation dataset, ZeroWaste. This dataset contains over1800fully segmented video frames collected from a real waste sorting plant along with waste material labels for training and evaluation of the segmentation methods, as well as over6000unlabeled frames that can be further used for semi-supervised and self-supervised learning techniques. ZeroWaste also provides frames of the conveyor belt before and after the sorting process, comprising a novel setup that can be used for weakly-supervised segmentation. We present baselines for fully-, semi- and weakly-supervised segmentation methods. Our experimental results demonstrate that state-of-the-art segmentation methods struggle to correctly detect and classify target objects which suggests the challenging nature of our proposed in-the-wild dataset. We believe that ZeroWastewill catalyze research in object detection and semantic segmentation in extreme clutter as well as applications in the recycling domain. Our project page can be found athttp://ai.bu.edu/zerowaste/.
ECNNs: Ensemble Learning Methods for Improving Planar Grasp Quality Estimation
May 01, 2021
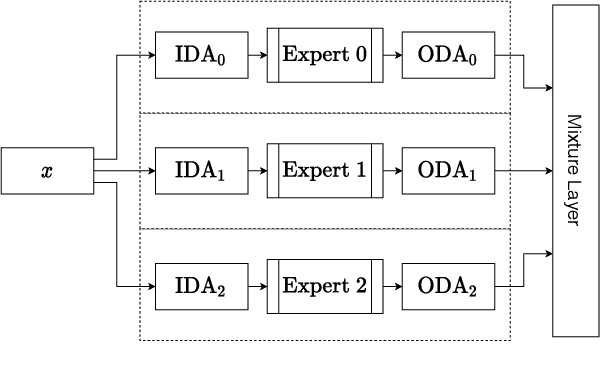
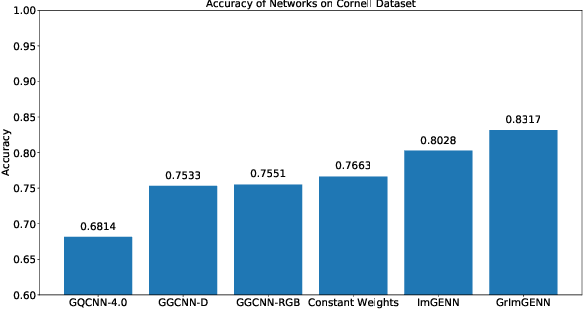

We present an ensemble learning methodology that combines multiple existing robotic grasp synthesis algorithms and obtain a success rate that is significantly better than the individual algorithms. The methodology treats the grasping algorithms as "experts" providing grasp "opinions". An Ensemble Convolutional Neural Network (ECNN) is trained using a Mixture of Experts (MOE) model that integrates these opinions and determines the final grasping decision. The ECNN introduces minimal computational cost overhead, and the network can virtually run as fast as the slowest expert. We test this architecture using open-source algorithms in the literature by adopting GQCNN 4.0, GGCNN and a custom variation of GGCNN as experts and obtained a 6% increase in the grasp success on the Cornell Dataset compared to the best-performing individual algorithm. The performance of the method is also demonstrated using a Franka Emika Panda arm.