 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIFT: Gradient-aware Immunization of diffusion models against malicious Fine-Tuning with safe concepts retention
Jul 18, 2025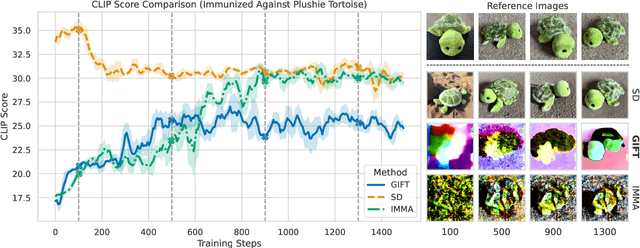
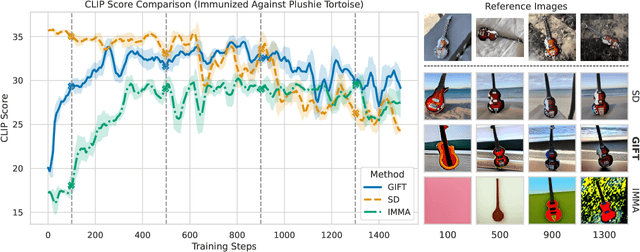
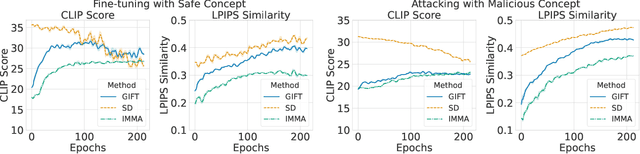
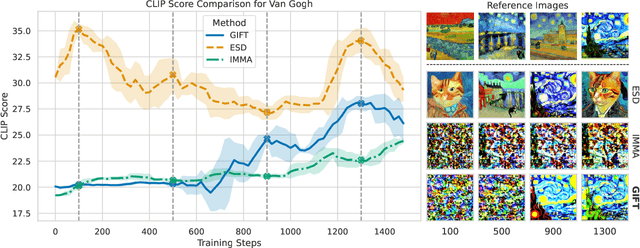
We present GIFT: a {G}radient-aware {I}mmunization technique to defend diffusion models against malicious {F}ine-{T}uning while preserving their ability to generate safe content. Existing safety mechanisms like safety checkers are easily bypassed, and concept erasure methods fail under adversarial fine-tuning. GIFT addresses this by framing immunization as a bi-level optimization problem: the upper-level objective degrades the model's ability to represent harmful concepts using representation noising and maximization, while the lower-level objective preserves performance on safe data. GIFT achieves robust resistance to malicious fine-tuning while maintaining safe generative quality. Experimental results show that our method significantly impairs the model's ability to re-learn harmful concepts while maintaining performance on safe content, offering a promising direction for creating inherently safer generative models resistant to adversarial fine-tuning attacks.
ViSTA: Visual Storytelling using Multi-modal Adapters for Text-to-Image Diffusion Models
Jun 13, 2025Text-to-image diffusion models have achieved remarkable success, yet generating coherent image sequences for visual storytelling remains challenging. A key challenge is effectively leveraging all previous text-image pairs, referred to as history text-image pairs, which provide contextual information for maintaining consistency across frames. Existing auto-regressive methods condition on all past image-text pairs but require extensive training, while training-free subject-specific approaches ensure consistency but lack adaptability to narrative prompts. To address these limitations, we propose a multi-modal history adapter for text-to-image diffusion models, \textbf{ViSTA}. It consists of (1) a multi-modal history fusion module to extract relevant history features and (2) a history adapter to condition the generation on the extracted relevant features. We also introduce a salient history selection strategy during inference, where the most salient history text-image pair is selected, improving the quality of the conditioning. Furthermore, we propose to employ a Visual Question Answering-based metric TIFA to assess text-image alignment in visual storytelling, providing a more targeted and interpretable assessment of generated images. Evaluated on the StorySalon and FlintStonesSV dataset, our proposed ViSTA model is not only consistent across different frames, but also well-aligned with the narrative text descriptions.
A Manually Annotated Image-Caption Dataset for Detecting Children in the Wild
Jun 11, 2025


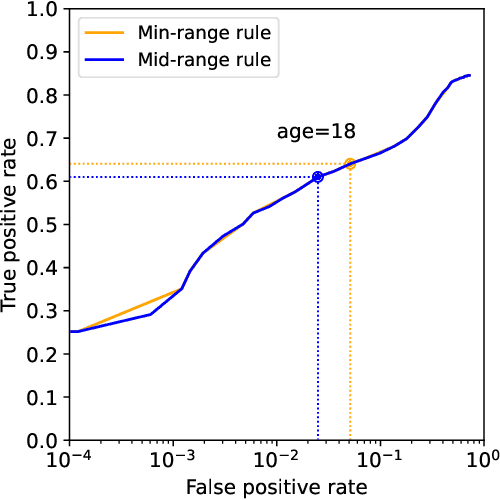
Platforms and the law regulate digital content depicting minors (defined as individuals under 18 years of age) differently from other types of content. Given the sheer amount of content that needs to be assessed, machine learning-based automation tools are commonly used to detect content depicting minors. To our knowledge, no dataset or benchmark currently exists for detecting these identification methods in a multi-modal environment. To fill this gap, we release the Image-Caption Children in the Wild Dataset (ICCWD), an image-caption dataset aimed at benchmarking tools that detect depictions of minors. Our dataset is richer than previous child image datasets, containing images of children in a variety of contexts, including fictional depictions and partially visible bodies. ICCWD contains 10,000 image-caption pairs manually labeled to indicate the presence or absence of a child in the image. To demonstrate the possible utility of our dataset, we use it to benchmark three different detectors, including a commercial age estimation system applied to images. Our results suggest that child detection is a challenging task, with the best method achieving a 75.3% true positive rate. We hope the release of our dataset will aid in the design of better minor detection methods in a wide range of scenarios.
GenEAva: Generating Cartoon Avatars with Fine-Grained Facial Expressions from Realistic Diffusion-based Faces
Apr 10, 2025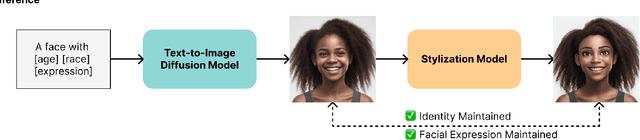


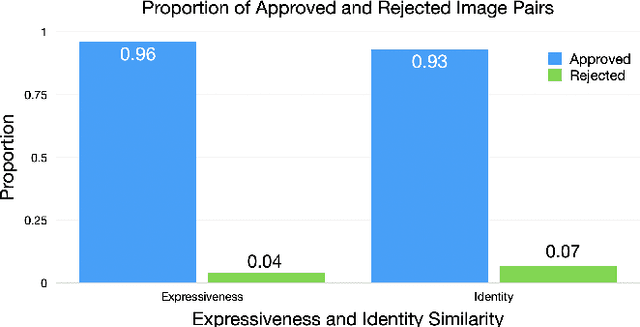
Cartoon avatars have been widely used in various applications, including social media, online tutoring, and gaming. However, existing cartoon avatar datasets and generation methods struggle to present highly expressive avatars with fine-grained facial expressions and are often inspired from real-world identities, raising privacy concerns. To address these challenges, we propose a novel framework, GenEAva, for generating high-quality cartoon avatars with fine-grained facial expressions. Our approach fine-tunes a state-of-the-art text-to-image diffusion model to synthesize highly detailed and expressive facial expressions. We then incorporate a stylization model that transforms these realistic faces into cartoon avatars while preserving both identity and expression. Leveraging this framework, we introduce the first expressive cartoon avatar dataset, GenEAva 1.0, specifically designed to capture 135 fine-grained facial expressions, featuring 13,230 expressive cartoon avatars with a balanced distribution across genders, racial groups, and age ranges. We demonstrate that our fine-tuned model generates more expressive faces than the state-of-the-art text-to-image diffusion model SDXL. We also verify that the cartoon avatars generated by our framework do not include memorized identities from fine-tuning data. The proposed framework and dataset provide a diverse and expressive benchmark for future research in cartoon avatar generation.
D-Feat Occlusions: Diffusion Features for Robustness to Partial Visual Occlusions in Object Recognition
Apr 08, 2025Applications of diffusion models for visual tasks have been quite noteworthy. This paper targets making classification models more robust to occlusions for the task of object recognition by proposing a pipeline that utilizes a frozen diffusion model. Diffusion features have demonstrated success in image generation and image completion while understanding image context. Occlusion can be posed as an image completion problem by deeming the pixels of the occluder to be `missing.' We hypothesize that such features can help hallucinate object visual features behind occluding objects, and hence we propose using them to enable models to become more occlusion robust. We design experiments to include input-based augmentations as well as feature-based augmentations. Input-based augmentations involve finetuning on images where the occluder pixels are inpainted, and feature-based augmentations involve augmenting classification features with intermediate diffusion features. We demonstrate that our proposed use of diffusion-based features results in models that are more robust to partial object occlusions for both Transformers and ConvNets on ImageNet with simulated occlusions. We also propose a dataset that encompasses real-world occlusions and demonstrate that our method is more robust to partial object occlusions.
FaithFill: Faithful Inpainting for Object Completion Using a Single Reference Image
Jun 12, 2024
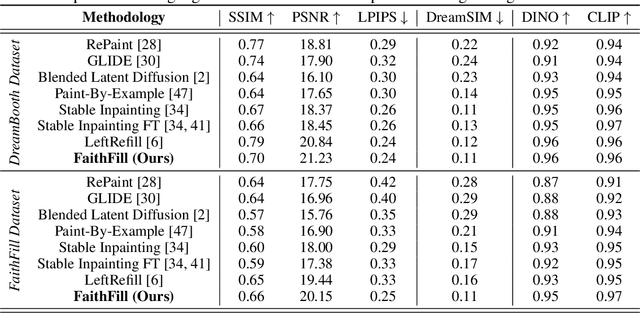
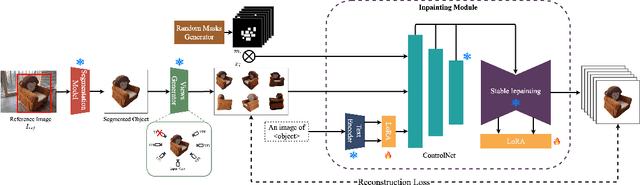

We present FaithFill, a diffusion-based inpainting object completion approach for realistic generation of missing object parts. Typically, multiple reference images are needed to achieve such realistic generation, otherwise the generation would not faithfully preserve shape, texture, color, and background. In this work, we propose a pipeline that utilizes only a single input reference image -having varying lighting, background, object pose, and/or viewpoint. The singular reference image is used to generate multiple views of the object to be inpainted. We demonstrate that FaithFill produces faithful generation of the object's missing parts, together with background/scene preservation, from a single reference image. This is demonstrated through standard similarity metrics, human judgement, and GPT evaluation. Our results are presented on the DreamBooth dataset, and a novel proposed dataset.
Lasagna: Layered Score Distillation for Disentangled Object Relighting
Nov 30, 2023



Professional artists, photographers, and other visual content creators use object relighting to establish their photo's desired effect. Unfortunately, manual tools that allow relighting have a steep learning curve and are difficult to master. Although generative editing methods now enable some forms of image editing, relighting is still beyond today's capabilities; existing methods struggle to keep other aspects of the image -- colors, shapes, and textures -- consistent after the edit. We propose Lasagna, a method that enables intuitive text-guided relighting control. Lasagna learns a lighting prior by using score distillation sampling to distill the prior of a diffusion model, which has been finetuned on synthetic relighting data. To train Lasagna, we curate a new synthetic dataset ReLiT, which contains 3D object assets re-lit from multiple light source locations. Despite training on synthetic images, quantitative results show that Lasagna relights real-world images while preserving other aspects of the input image, outperforming state-of-the-art text-guided image editing methods. Lasagna enables realistic and controlled results on natural images and digital art pieces and is preferred by humans over other methods in over 91% of cases. Finally, we demonstrate the versatility of our learning objective by extending it to allow colorization, another form of image editing.
Hardwiring ViT Patch Selectivity into CNNs using Patch Mixing
Jun 30, 2023



Vision transformers (ViTs) have significantly changed the computer vision landscape and have periodically exhibited superior performance in vision tasks compared to convolutional neural networks (CNNs). Although the jury is still out on which model type is superior, each has unique inductive biases that shape their learning and generalization performance. For example, ViTs have interesting properties with respect to early layer non-local feature dependence, as well as self-attention mechanisms which enhance learning flexibility, enabling them to ignore out-of-context image information more effectively. We hypothesize that this power to ignore out-of-context information (which we name $\textit{patch selectivity}$), while integrating in-context information in a non-local manner in early layers, allows ViTs to more easily handle occlusion. In this study, our aim is to see whether we can have CNNs $\textit{simulate}$ this ability of patch selectivity by effectively hardwiring this inductive bias using Patch Mixing data augmentation, which consists of inserting patches from another image onto a training image and interpolating labels between the two image classes. Specifically, we use Patch Mixing to train state-of-the-art ViTs and CNNs, assessing its impact on their ability to ignore out-of-context patches and handle natural occlusions. We find that ViTs do not improve nor degrade when trained using Patch Mixing, but CNNs acquire new capabilities to ignore out-of-context information and improve on occlusion benchmarks, leaving us to conclude that this training method is a way of simulating in CNNs the abilities that ViTs already possess. We will release our Patch Mixing implementation and proposed datasets for public use. Project page: https://arielnlee.github.io/PatchMixing/
VisDA 2022 Challenge: Domain Adaptation for Industrial Waste Sorting
Mar 26, 2023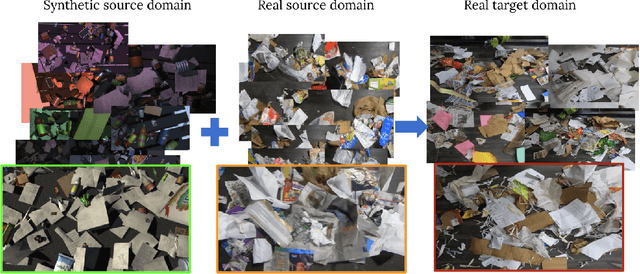
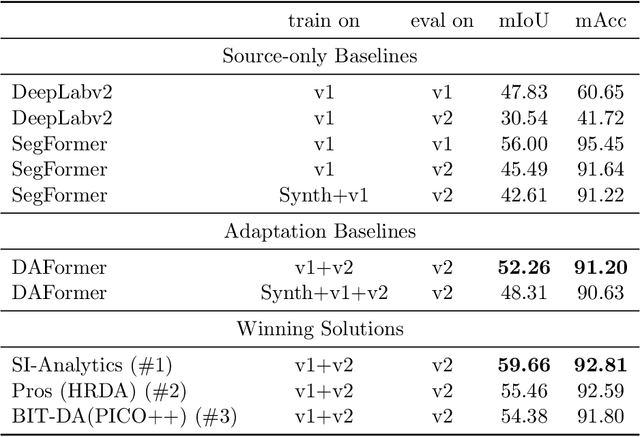

Label-efficient and reliable semantic segmentation is essential for many real-life applications, especially for industrial settings with high visual diversity, such as waste sorting. In industrial waste sorting, one of the biggest challenges is the extreme diversity of the input stream depending on factors like the location of the sorting facility, the equipment available in the facility, and the time of year, all of which significantly impact the composition and visual appearance of the waste stream. These changes in the data are called ``visual domains'', and label-efficient adaptation of models to such domains is needed for successful semantic segmentation of industrial waste. To test the abilities of computer vision models on this task, we present the VisDA 2022 Challenge on Domain Adaptation for Industrial Waste Sorting. Our challenge incorporates a fully-annotated waste sorting dataset, ZeroWaste, collected from two real material recovery facilities in different locations and seasons, as well as a novel procedurally generated synthetic waste sorting dataset, SynthWaste. In this competition, we aim to answer two questions: 1) can we leverage domain adaptation techniques to minimize the domain gap? and 2) can synthetic data augmentation improve performance on this task and help adapt to changing data distributions? The results of the competition show that industrial waste detection poses a real domain adaptation problem, that domain generalization techniques such as augmentations, ensembling, etc., improve the overall performance on the unlabeled target domain examples, and that leveraging synthetic data effectively remains an open problem. See https://ai.bu.edu/visda-2022/
Finding Differences Between Transformers and ConvNets Using Counterfactual Simulation Testing
Nov 29, 2022



Modern deep neural networks tend to be evaluated on static test sets. One shortcoming of this is the fact that these deep neural networks cannot be easily evaluated for robustness issues with respect to specific scene variations. For example, it is hard to study the robustness of these networks to variations of object scale, object pose, scene lighting and 3D occlusions. The main reason is that collecting real datasets with fine-grained naturalistic variations of sufficient scale can be extremely time-consuming and expensive. In this work, we present Counterfactual Simulation Testing, a counterfactual framework that allows us to study the robustness of neural networks with respect to some of these naturalistic variations by building realistic synthetic scenes that allow us to ask counterfactual questions to the models, ultimately providing answers to questions such as "Would your classification still be correct if the object were viewed from the top?" or "Would your classification still be correct if the object were partially occluded by another object?". Our method allows for a fair comparison of the robustness of recently released, state-of-the-art Convolutional Neural Networks and Vision Transformers, with respect to these naturalistic variations. We find evidence that ConvNext is more robust to pose and scale variations than Swin, that ConvNext generalizes better to our simulated domain and that Swin handles partial occlusion better than ConvNext. We also find that robustness for all networks improves with network scale and with data scale and variety. We release the Naturalistic Variation Object Dataset (NVD), a large simulated dataset of 272k images of everyday objects with naturalistic variations such as object pose, scale, viewpoint, lighting and occlusions. Project page: https://counterfactualsimulation.github.io