 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould I use Synthetic Data for That? An Analysis of the Suitability of Synthetic Data for Data Sharing and Augmentation
Feb 03, 2026Recent advances in generative modelling have led many to see synthetic data as the go-to solution for a range of problems around data access, scarcity, and under-representation. In this paper, we study three prominent use cases: (1) Sharing synthetic data as a proxy for proprietary datasets to enable statistical analyses while protecting privacy, (2) Augmenting machine learning training sets with synthetic data to improve model performance, and (3) Augmenting datasets with synthetic data to reduce variance in statistical estimation. For each use case, we formalise the problem setting and study, through formal analysis and case studies, under which conditions synthetic data can achieve its intended objectives. We identify fundamental and practical limits that constrain when synthetic data can serve as an effective solution for a particular problem. Our analysis reveals that due to these limits many existing or envisioned use cases of synthetic data are a poor problem fit. Our formalisations and classification of synthetic data use cases enable decision makers to assess whether synthetic data is a suitable approach for their specific data availability problem.
A Manually Annotated Image-Caption Dataset for Detecting Children in the Wild
Jun 11, 2025


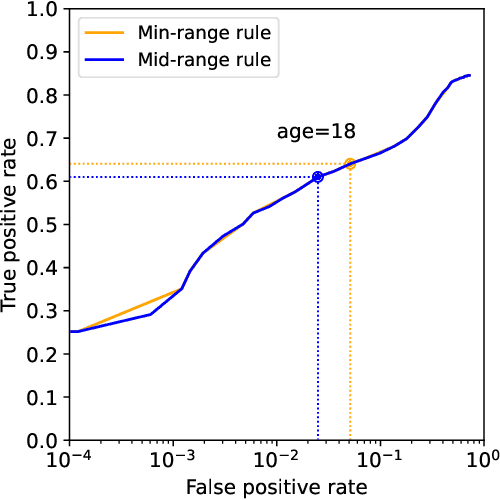
Platforms and the law regulate digital content depicting minors (defined as individuals under 18 years of age) differently from other types of content. Given the sheer amount of content that needs to be assessed, machine learning-based automation tools are commonly used to detect content depicting minors. To our knowledge, no dataset or benchmark currently exists for detecting these identification methods in a multi-modal environment. To fill this gap, we release the Image-Caption Children in the Wild Dataset (ICCWD), an image-caption dataset aimed at benchmarking tools that detect depictions of minors. Our dataset is richer than previous child image datasets, containing images of children in a variety of contexts, including fictional depictions and partially visible bodies. ICCWD contains 10,000 image-caption pairs manually labeled to indicate the presence or absence of a child in the image. To demonstrate the possible utility of our dataset, we use it to benchmark three different detectors, including a commercial age estimation system applied to images. Our results suggest that child detection is a challenging task, with the best method achieving a 75.3% true positive rate. We hope the release of our dataset will aid in the design of better minor detection methods in a wide range of scenarios.
Attack-Aware Noise Calibration for Differential Privacy
Jul 02, 2024Differential privacy (DP) is a widely used approach for mitigating privacy risks when training machine learning models on sensitive data. DP mechanisms add noise during training to limit the risk of information leakage. The scale of the added noise is critical, as it determines the trade-off between privacy and utility. The standard practice is to select the noise scale in terms of a privacy budget parameter $\epsilon$. This parameter is in turn interpreted in terms of operational attack risk, such as accuracy, or sensitivity and specificity of inference attacks against the privacy of the data. We demonstrate that this two-step procedure of first calibrating the noise scale to a privacy budget $\epsilon$, and then translating $\epsilon$ to attack risk leads to overly conservative risk assessments and unnecessarily low utility. We propose methods to directly calibrate the noise scale to a desired attack risk level, bypassing the intermediate step of choosing $\epsilon$. For a target attack risk, our approach significantly decreases noise scale, leading to increased utility at the same level of privacy. We empirically demonstrate that calibrating noise to attack sensitivity/specificity, rather than $\epsilon$, when training privacy-preserving ML models substantially improves model accuracy for the same risk level. Our work provides a principled and practical way to improve the utility of privacy-preserving ML without compromising on privacy.
SINBAD: Saliency-informed detection of breakage caused by ad blocking
May 08, 2024
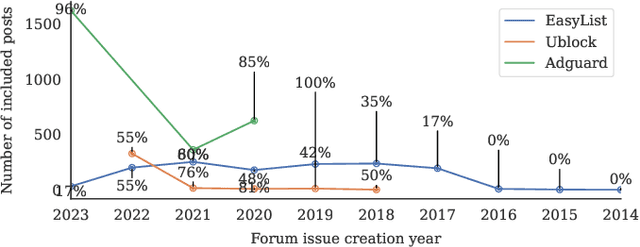
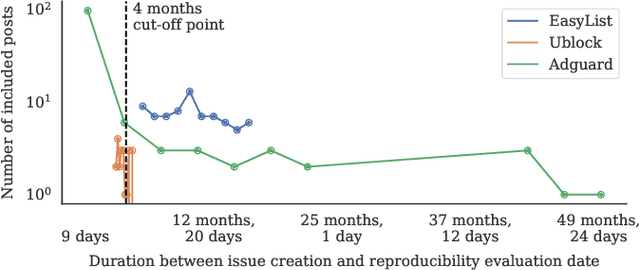
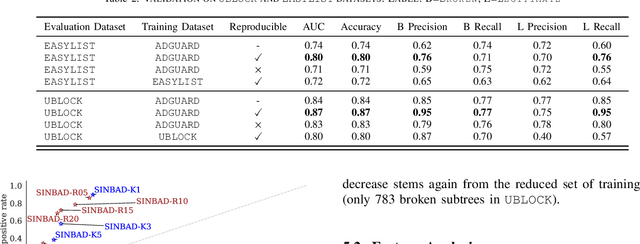
Privacy-enhancing blocking tools based on filter-list rules tend to break legitimate functionality. Filter-list maintainers could benefit from automated breakage detection tools that allow them to proactively fix problematic rules before deploying them to millions of users. We introduce SINBAD, an automated breakage detector that improves the accuracy over the state of the art by 20%, and is the first to detect dynamic breakage and breakage caused by style-oriented filter rules. The success of SINBAD is rooted in three innovations: (1) the use of user-reported breakage issues in forums that enable the creation of a high-quality dataset for training in which only breakage that users perceive as an issue is included; (2) the use of 'web saliency' to automatically identify user-relevant regions of a website on which to prioritize automated interactions aimed at triggering breakage; and (3) the analysis of webpages via subtrees which enables fine-grained identification of problematic filter rules.
Neural Exec: Learning (and Learning from) Execution Triggers for Prompt Injection Attacks
Mar 06, 2024

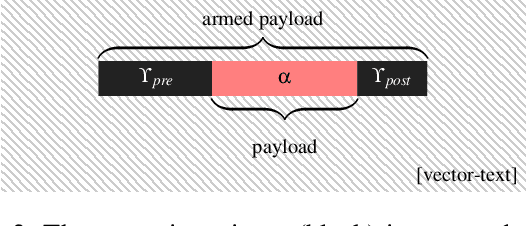

We introduce a new family of prompt injection attacks, termed Neural Exec. Unlike known attacks that rely on handcrafted strings (e.g., "Ignore previous instructions and..."), we show that it is possible to conceptualize the creation of execution triggers as a differentiable search problem and use learning-based methods to autonomously generate them. Our results demonstrate that a motivated adversary can forge triggers that are not only drastically more effective than current handcrafted ones but also exhibit inherent flexibility in shape, properties, and functionality. In this direction, we show that an attacker can design and generate Neural Execs capable of persisting through multi-stage preprocessing pipelines, such as in the case of Retrieval-Augmented Generation (RAG)-based applications. More critically, our findings show that attackers can produce triggers that deviate markedly in form and shape from any known attack, sidestepping existing blacklist-based detection and sanitation approaches.
On the Conflict of Robustness and Learning in Collaborative Machine Learning
Feb 21, 2024Collaborative Machine Learning (CML) allows participants to jointly train a machine learning model while keeping their training data private. In scenarios where privacy is a strong requirement, such as health-related applications, safety is also a primary concern. This means that privacy-preserving CML processes must produce models that output correct and reliable decisions \emph{even in the presence of potentially untrusted participants}. In response to this issue, researchers propose to use \textit{robust aggregators} that rely on metrics which help filter out malicious contributions that could compromise the training process. In this work, we formalize the landscape of robust aggregators in the literature. Our formalization allows us to show that existing robust aggregators cannot fulfill their goal: either they use distance-based metrics that cannot accurately identify targeted malicious updates; or propose methods whose success is in direct conflict with the ability of CML participants to learn from others and therefore cannot eliminate the risk of manipulation without preventing learning.
The Fundamental Limits of Least-Privilege Learning
Feb 19, 2024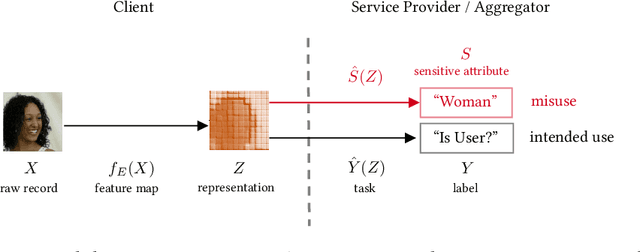

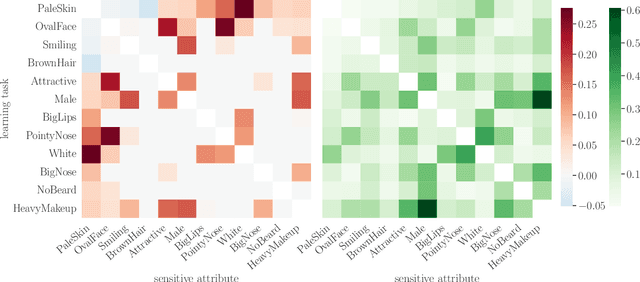

The promise of least-privilege learning -- to find feature representations that are useful for a learning task but prevent inference of any sensitive information unrelated to this task -- is highly appealing. However, so far this concept has only been stated informally. It thus remains an open question whether and how we can achieve this goal. In this work, we provide the first formalisation of the least-privilege principle for machine learning and characterise its feasibility. We prove that there is a fundamental trade-off between a representation's utility for a given task and its leakage beyond the intended task: it is not possible to learn representations that have high utility for the intended task but, at the same time prevent inference of any attribute other than the task label itself. This trade-off holds regardless of the technique used to learn the feature mappings that produce these representations. We empirically validate this result for a wide range of learning techniques, model architectures, and datasets.
Transferable Adversarial Robustness for Categorical Data via Universal Robust Embeddings
Jun 06, 2023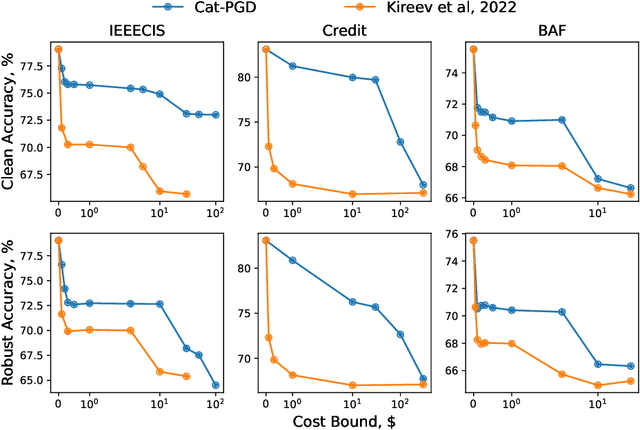
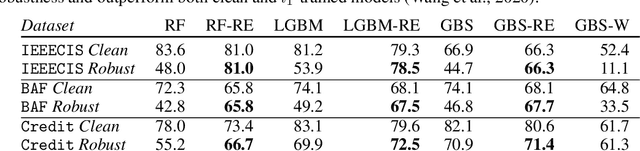
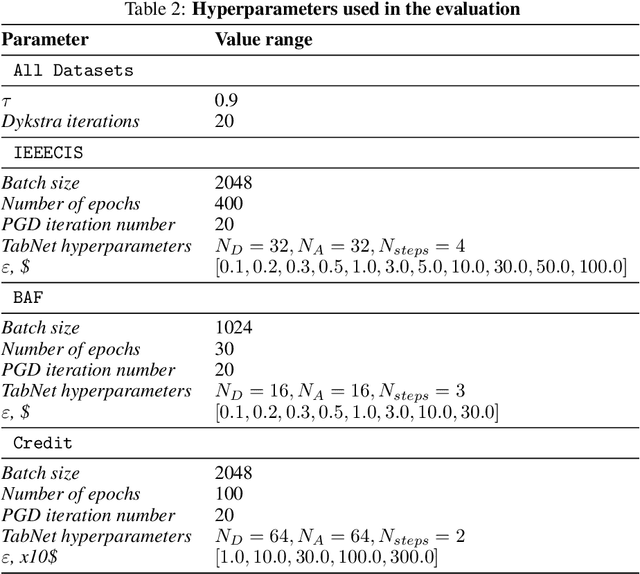
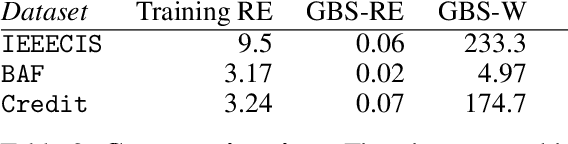
Research on adversarial robustness is primarily focused on image and text data. Yet, many scenarios in which lack of robustness can result in serious risks, such as fraud detection, medical diagnosis, or recommender systems often do not rely on images or text but instead on tabular data. Adversarial robustness in tabular data poses two serious challenges. First, tabular datasets often contain categorical features, and therefore cannot be tackled directly with existing optimization procedures. Second, in the tabular domain, algorithms that are not based on deep networks are widely used and offer great performance, but algorithms to enhance robustness are tailored to neural networks (e.g. adversarial training). In this paper, we tackle both challenges. We present a method that allows us to train adversarially robust deep networks for tabular data and to transfer this robustness to other classifiers via universal robust embeddings tailored to categorical data. These embeddings, created using a bilevel alternating minimization framework, can be transferred to boosted trees or random forests making them robust without the need for adversarial training while preserving their high accuracy on tabular data. We show that our methods outperform existing techniques within a practical threat model suitable for tabular data.
Can Decentralized Learning be more robust than Federated Learning?
Mar 07, 2023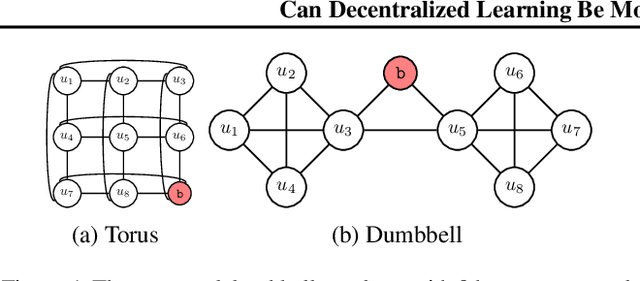
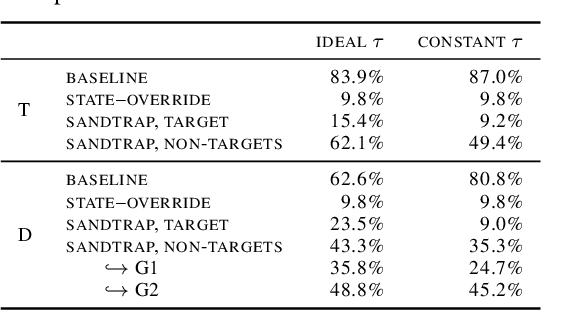
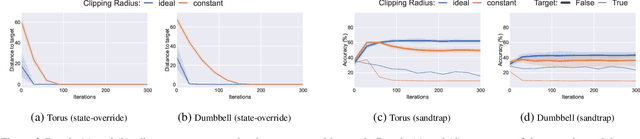
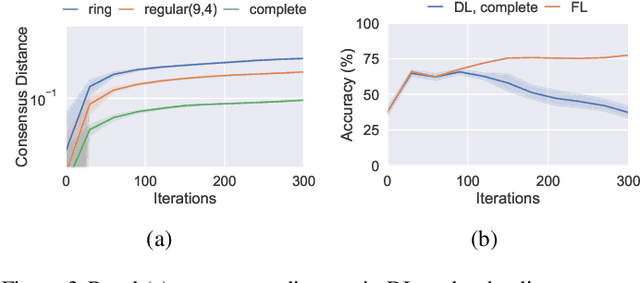
Decentralized Learning (DL) is a peer--to--peer learning approach that allows a group of users to jointly train a machine learning model. To ensure correctness, DL should be robust, i.e., Byzantine users must not be able to tamper with the result of the collaboration. In this paper, we introduce two \textit{new} attacks against DL where a Byzantine user can: make the network converge to an arbitrary model of their choice, and exclude an arbitrary user from the learning process. We demonstrate our attacks' efficiency against Self--Centered Clipping, the state--of--the--art robust DL protocol. Finally, we show that the capabilities decentralization grants to Byzantine users result in decentralized learning \emph{always} providing less robustness than federated learning.
Arbitrary Decisions are a Hidden Cost of Differentially-Private Training
Feb 28, 2023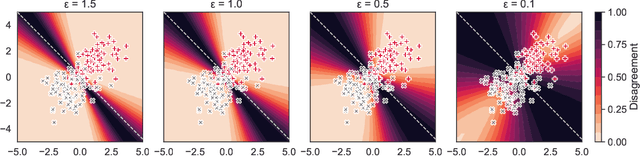
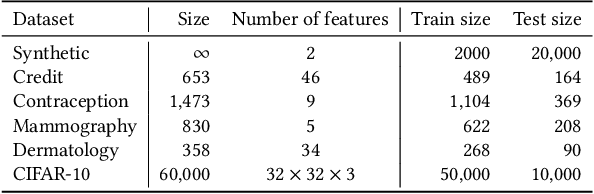
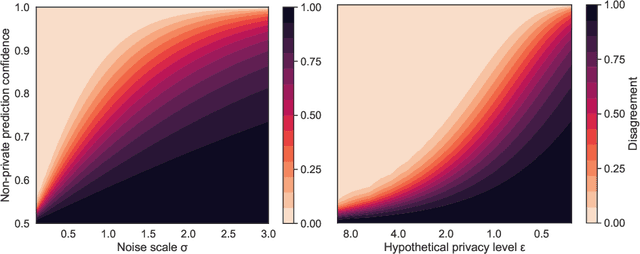
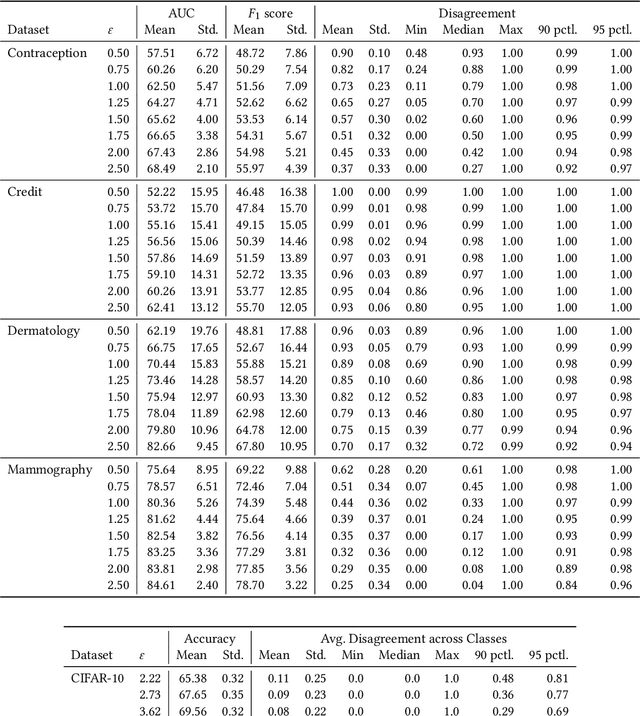
Mechanisms used in privacy-preserving machine learning often aim to guarantee differential privacy (DP) during model training. Practical DP-ensuring training methods use randomization when fitting model parameters to privacy-sensitive data (e.g., adding Gaussian noise to clipped gradients). We demonstrate that such randomization incurs predictive multiplicity: for a given input example, the output predicted by equally-private models depends on the randomness used in training. Thus, for a given input, the predicted output can vary drastically if a model is re-trained, even if the same training dataset is used. The predictive-multiplicity cost of DP training has not been studied, and is currently neither audited for nor communicated to model designers and stakeholders. We derive a bound on the number of re-trainings required to estimate predictive multiplicity reliably. We analyze -- both theoretically and through extensive experiments -- the predictive-multiplicity cost of three DP-ensuring algorithms: output perturbation, objective perturbation, and DP-SGD. We demonstrate that the degree of predictive multiplicity rises as the level of privacy increases, and is unevenly distributed across individuals and demographic groups in the data. Because randomness used to ensure DP during training explains predictions for some examples, our results highlight a fundamental challenge to the justifiability of decisions supported by differentially-private models in high-stakes settings. We conclude that practitioners should audit the predictive multiplicity of their DP-ensuring algorithms before deploying them in applications of individual-level consequence.