 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Choosing the $μ$ Parameter in Gaussian Differential Privacy
Jun 08, 2026Recent work argues for using Gaussian differential privacy (GDP) to report the privacy guarantees in privacy-preserving machine learning. We provide principled mappings from pure-DP $\varepsilon$ to GDP $μ$ by matching the worst-case success of a strong-adversary membership inference attack in terms of three metrics: multiplicative advantage at fixed FPR, precision at fixed recall, and the standard privacy profile. We tabulate $μ$ values across a useful range of parameters and recommend $μ\approx \varepsilon/5$ as a conservative general-purpose conversion.
Tight Auditing of Differential Privacy in MST and AIM
Apr 20, 2026State-of-the-art Differentially Private (DP) synthetic data generators such as MST and AIM are widely used, yet tightly auditing their privacy guarantees remains challenging. We introduce a Gaussian Differential Privacy (GDP)-based auditing framework that measures privacy via the full false-positive/false-negative tradeoff. Applied to MST and AIM under worst-case settings, our method provides the first tight audits in the strong-privacy regime. For $(ε,δ)=(1,10^{-2})$, we obtain $μ_{emp}\approx0.43$ vs. implied $μ=0.45$, showing a small theory-practice gap. Our code is publicly available: https://github.com/sassoftware/dpmm.
Should I use Synthetic Data for That? An Analysis of the Suitability of Synthetic Data for Data Sharing and Augmentation
Feb 03, 2026Recent advances in generative modelling have led many to see synthetic data as the go-to solution for a range of problems around data access, scarcity, and under-representation. In this paper, we study three prominent use cases: (1) Sharing synthetic data as a proxy for proprietary datasets to enable statistical analyses while protecting privacy, (2) Augmenting machine learning training sets with synthetic data to improve model performance, and (3) Augmenting datasets with synthetic data to reduce variance in statistical estimation. For each use case, we formalise the problem setting and study, through formal analysis and case studies, under which conditions synthetic data can achieve its intended objectives. We identify fundamental and practical limits that constrain when synthetic data can serve as an effective solution for a particular problem. Our analysis reveals that due to these limits many existing or envisioned use cases of synthetic data are a poor problem fit. Our formalisations and classification of synthetic data use cases enable decision makers to assess whether synthetic data is a suitable approach for their specific data availability problem.
Unifying Re-Identification, Attribute Inference, and Data Reconstruction Risks in Differential Privacy
Jul 09, 2025Differentially private (DP) mechanisms are difficult to interpret and calibrate because existing methods for mapping standard privacy parameters to concrete privacy risks -- re-identification, attribute inference, and data reconstruction -- are both overly pessimistic and inconsistent. In this work, we use the hypothesis-testing interpretation of DP ($f$-DP), and determine that bounds on attack success can take the same unified form across re-identification, attribute inference, and data reconstruction risks. Our unified bounds are (1) consistent across a multitude of attack settings, and (2) tunable, enabling practitioners to evaluate risk with respect to arbitrary (including worst-case) levels of baseline risk. Empirically, our results are tighter than prior methods using $\varepsilon$-DP, R\'enyi DP, and concentrated DP. As a result, calibrating noise using our bounds can reduce the required noise by 20% at the same risk level, which yields, e.g., more than 15pp accuracy increase in a text classification task. Overall, this unifying perspective provides a principled framework for interpreting and calibrating the degree of protection in DP against specific levels of re-identification, attribute inference, or data reconstruction risk.
Statistical Inference for Responsiveness Verification
Jul 02, 2025Many safety failures in machine learning arise when models are used to assign predictions to people (often in settings like lending, hiring, or content moderation) without accounting for how individuals can change their inputs. In this work, we introduce a formal validation procedure for the responsiveness of predictions with respect to interventions on their features. Our procedure frames responsiveness as a type of sensitivity analysis in which practitioners control a set of changes by specifying constraints over interventions and distributions over downstream effects. We describe how to estimate responsiveness for the predictions of any model and any dataset using only black-box access, and how to use these estimates to support tasks such as falsification and failure probability estimation. We develop algorithms that construct these estimates by generating a uniform sample of reachable points, and demonstrate how they can promote safety in real-world applications such as recidivism prediction, organ transplant prioritization, and content moderation.
$(\varepsilon, δ)$ Considered Harmful: Best Practices for Reporting Differential Privacy Guarantees
Mar 13, 2025Current practices for reporting the level of differential privacy (DP) guarantees for machine learning (ML) algorithms provide an incomplete and potentially misleading picture of the guarantees and make it difficult to compare privacy levels across different settings. We argue for using Gaussian differential privacy (GDP) as the primary means of communicating DP guarantees in ML, with the full privacy profile as a secondary option in case GDP is too inaccurate. Unlike other widely used alternatives, GDP has only one parameter, which ensures easy comparability of guarantees, and it can accurately capture the full privacy profile of many important ML applications. To support our claims, we investigate the privacy profiles of state-of-the-art DP large-scale image classification, and the TopDown algorithm for the U.S. Decennial Census, observing that GDP fits the profiles remarkably well in all three cases. Although GDP is ideal for reporting the final guarantees, other formalisms (e.g., privacy loss random variables) are needed for accurate privacy accounting. We show that such intermediate representations can be efficiently converted to GDP with minimal loss in tightness.
Attack-Aware Noise Calibration for Differential Privacy
Jul 02, 2024Differential privacy (DP) is a widely used approach for mitigating privacy risks when training machine learning models on sensitive data. DP mechanisms add noise during training to limit the risk of information leakage. The scale of the added noise is critical, as it determines the trade-off between privacy and utility. The standard practice is to select the noise scale in terms of a privacy budget parameter $\epsilon$. This parameter is in turn interpreted in terms of operational attack risk, such as accuracy, or sensitivity and specificity of inference attacks against the privacy of the data. We demonstrate that this two-step procedure of first calibrating the noise scale to a privacy budget $\epsilon$, and then translating $\epsilon$ to attack risk leads to overly conservative risk assessments and unnecessarily low utility. We propose methods to directly calibrate the noise scale to a desired attack risk level, bypassing the intermediate step of choosing $\epsilon$. For a target attack risk, our approach significantly decreases noise scale, leading to increased utility at the same level of privacy. We empirically demonstrate that calibrating noise to attack sensitivity/specificity, rather than $\epsilon$, when training privacy-preserving ML models substantially improves model accuracy for the same risk level. Our work provides a principled and practical way to improve the utility of privacy-preserving ML without compromising on privacy.
The Fundamental Limits of Least-Privilege Learning
Feb 19, 2024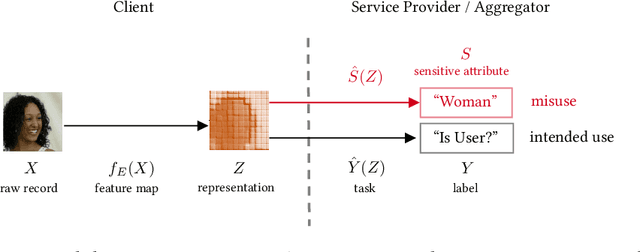

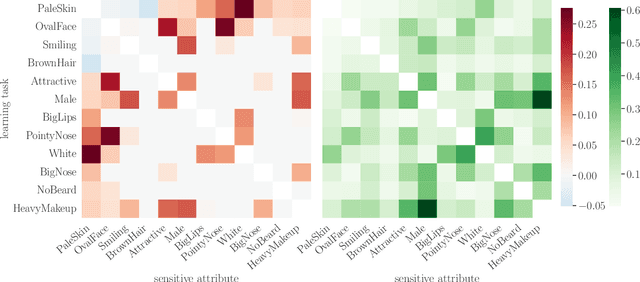

The promise of least-privilege learning -- to find feature representations that are useful for a learning task but prevent inference of any sensitive information unrelated to this task -- is highly appealing. However, so far this concept has only been stated informally. It thus remains an open question whether and how we can achieve this goal. In this work, we provide the first formalisation of the least-privilege principle for machine learning and characterise its feasibility. We prove that there is a fundamental trade-off between a representation's utility for a given task and its leakage beyond the intended task: it is not possible to learn representations that have high utility for the intended task but, at the same time prevent inference of any attribute other than the task label itself. This trade-off holds regardless of the technique used to learn the feature mappings that produce these representations. We empirically validate this result for a wide range of learning techniques, model architectures, and datasets.
Prediction without Preclusion: Recourse Verification with Reachable Sets
Aug 24, 2023



Machine learning models are often used to decide who will receive a loan, a job interview, or a public benefit. Standard techniques to build these models use features about people but overlook their actionability. In turn, models can assign predictions that are fixed, meaning that consumers who are denied loans, interviews, or benefits may be permanently locked out from access to credit, employment, or assistance. In this work, we introduce a formal testing procedure to flag models that assign fixed predictions that we call recourse verification. We develop machinery to reliably determine if a given model can provide recourse to its decision subjects from a set of user-specified actionability constraints. We demonstrate how our tools can ensure recourse and adversarial robustness in real-world datasets and use them to study the infeasibility of recourse in real-world lending datasets. Our results highlight how models can inadvertently assign fixed predictions that permanently bar access, and we provide tools to design algorithms that account for actionability when developing models.
Arbitrary Decisions are a Hidden Cost of Differentially-Private Training
Feb 28, 2023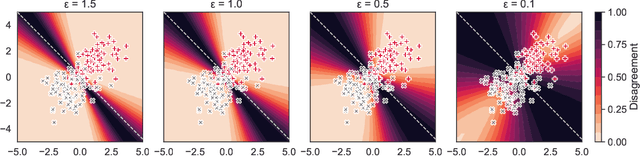
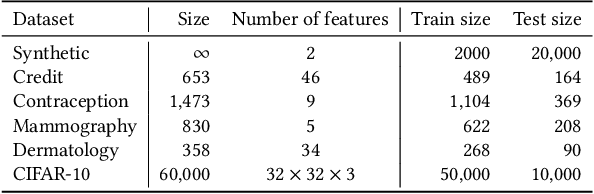
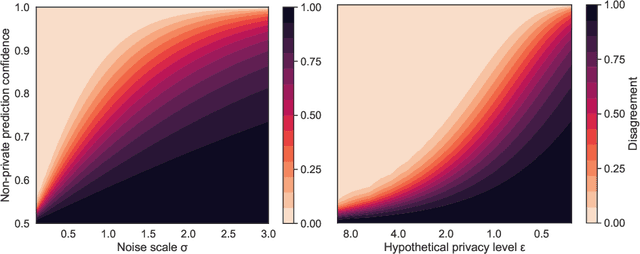
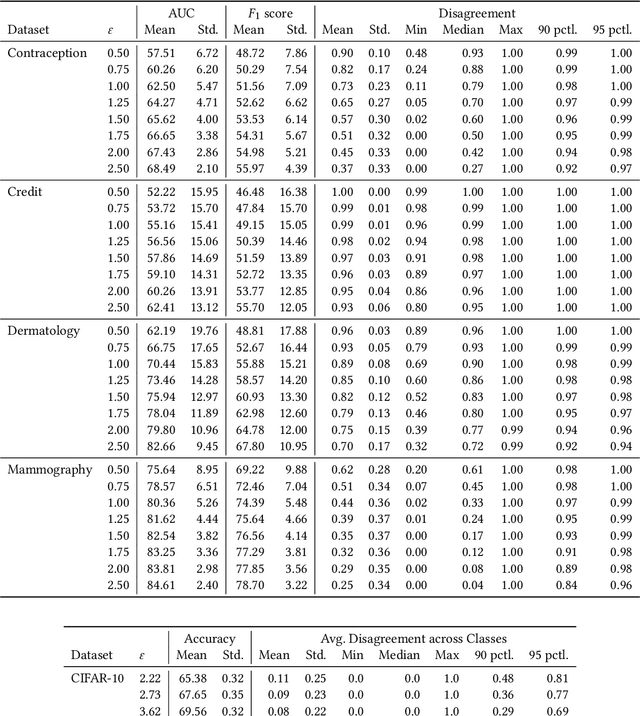
Mechanisms used in privacy-preserving machine learning often aim to guarantee differential privacy (DP) during model training. Practical DP-ensuring training methods use randomization when fitting model parameters to privacy-sensitive data (e.g., adding Gaussian noise to clipped gradients). We demonstrate that such randomization incurs predictive multiplicity: for a given input example, the output predicted by equally-private models depends on the randomness used in training. Thus, for a given input, the predicted output can vary drastically if a model is re-trained, even if the same training dataset is used. The predictive-multiplicity cost of DP training has not been studied, and is currently neither audited for nor communicated to model designers and stakeholders. We derive a bound on the number of re-trainings required to estimate predictive multiplicity reliably. We analyze -- both theoretically and through extensive experiments -- the predictive-multiplicity cost of three DP-ensuring algorithms: output perturbation, objective perturbation, and DP-SGD. We demonstrate that the degree of predictive multiplicity rises as the level of privacy increases, and is unevenly distributed across individuals and demographic groups in the data. Because randomness used to ensure DP during training explains predictions for some examples, our results highlight a fundamental challenge to the justifiability of decisions supported by differentially-private models in high-stakes settings. We conclude that practitioners should audit the predictive multiplicity of their DP-ensuring algorithms before deploying them in applications of individual-level consequence.