 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSex Trouble: Common pitfalls in incorporating sex/gender in medical machine learning and how to avoid them
Mar 15, 2022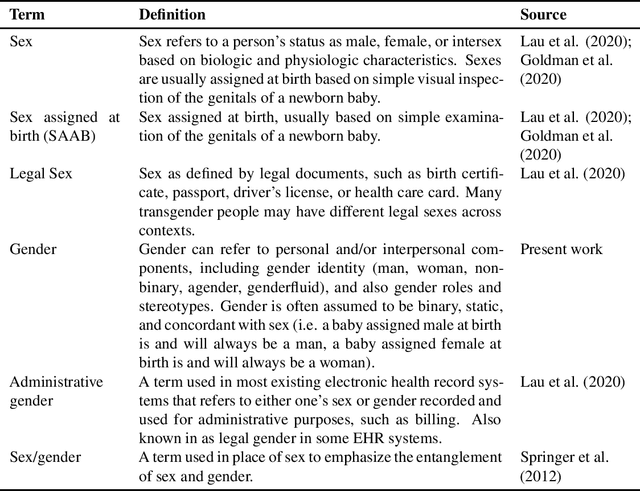
False assumptions about sex and gender are deeply embedded in the medical system, including that they are binary, static, and concordant. Machine learning researchers must understand the nature of these assumptions in order to avoid perpetuating them. In this perspectives piece, we identify three common mistakes that researchers make when dealing with sex/gender data: "sex confusion", the failure to identity what sex in a dataset does or doesn't mean; "sex obsession", the belief that sex, specifically sex assigned at birth, is the relevant variable for most applications; and "sex/gender slippage", the conflation of sex and gender even in contexts where only one or the other is known. We then discuss how these pitfalls show up in machine learning studies based on electronic health record data, which is commonly used for everything from retrospective analysis of patient outcomes to the development of algorithms to predict risk and administer care. Finally, we offer a series of recommendations about how machine learning researchers can produce both research and algorithms that more carefully engage with questions of sex/gender, better serving all patients, including transgender people.
Adversarial for Good? How the Adversarial ML Community's Values Impede Socially Beneficial Uses of Attacks
Jul 11, 2021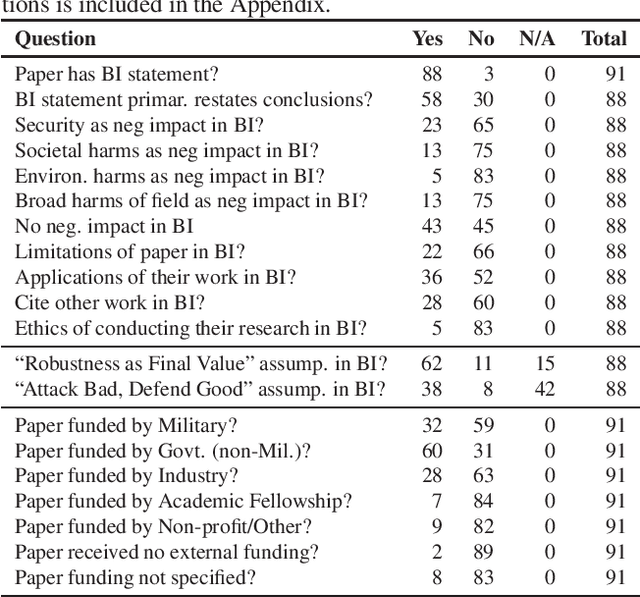
Attacks from adversarial machine learning (ML) have the potential to be used "for good": they can be used to run counter to the existing power structures within ML, creating breathing space for those who would otherwise be the targets of surveillance and control. But most research on adversarial ML has not engaged in developing tools for resistance against ML systems. Why? In this paper, we review the broader impact statements that adversarial ML researchers wrote as part of their NeurIPS 2020 papers and assess the assumptions that authors have about the goals of their work. We also collect information about how authors view their work's impact more generally. We find that most adversarial ML researchers at NeurIPS hold two fundamental assumptions that will make it difficult for them to consider socially beneficial uses of attacks: (1) it is desirable to make systems robust, independent of context, and (2) attackers of systems are normatively bad and defenders of systems are normatively good. That is, despite their expressed and supposed neutrality, most adversarial ML researchers believe that the goal of their work is to secure systems, making it difficult to conceptualize and build tools for disrupting the status quo.
Legal Risks of Adversarial Machine Learning Research
Jun 29, 2020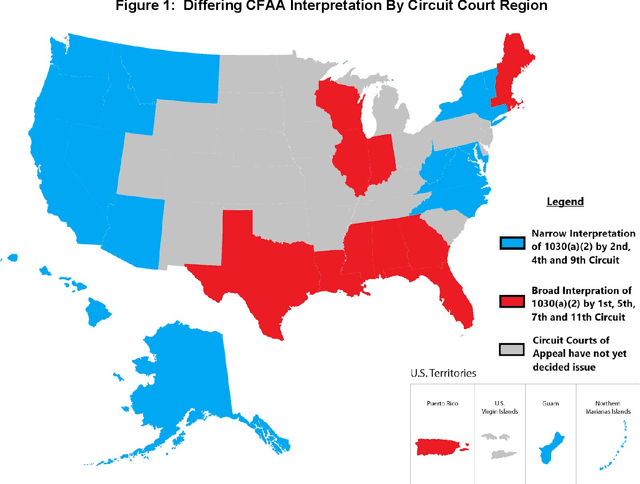

Adversarial Machine Learning is booming with ML researchers increasingly targeting commercial ML systems such as those used in Facebook, Tesla, Microsoft, IBM, Google to demonstrate vulnerabilities. In this paper, we ask, "What are the potential legal risks to adversarial ML researchers when they attack ML systems?" Studying or testing the security of any operational system potentially runs afoul the Computer Fraud and Abuse Act (CFAA), the primary United States federal statute that creates liability for hacking. We claim that Adversarial ML research is likely no different. Our analysis show that because there is a split in how CFAA is interpreted, aspects of adversarial ML attacks, such as model inversion, membership inference, model stealing, reprogramming the ML system and poisoning attacks, may be sanctioned in some jurisdictions and not penalized in others. We conclude with an analysis predicting how the US Supreme Court may resolve some present inconsistencies in the CFAA's application in Van Buren v. United States, an appeal expected to be decided in 2021. We argue that the court is likely to adopt a narrow construction of the CFAA, and that this will actually lead to better adversarial ML security outcomes in the long term.
Politics of Adversarial Machine Learning
Feb 19, 2020In addition to their security properties, adversarial machine-learning attacks and defenses have political dimensions. They enable or foreclose certain options for both the subjects of the machine learning systems and for those who deploy them, creating risks for civil liberties and human rights. In this paper, we draw on insights from science and technology studies, anthropology, and human rights literature, to inform how defenses against adversarial attacks can be used to suppress dissent and limit attempts to investigate machine learning systems. To make this concrete, we use real-world examples of how attacks such as perturbation, model inversion, or membership inference can be used for socially desirable ends. Although the predictions of this analysis may seem dire, there is hope. Efforts to address human rights concerns in the commercial spyware industry provide guidance for similar measures to ensure ML systems serve democratic, not authoritarian ends
Failure Modes in Machine Learning Systems
Nov 25, 2019In the last two years, more than 200 papers have been written on how machine learning (ML) systems can fail because of adversarial attacks on the algorithms and data; this number balloons if we were to incorporate papers covering non-adversarial failure modes. The spate of papers has made it difficult for ML practitioners, let alone engineers, lawyers, and policymakers, to keep up with the attacks against and defenses of ML systems. However, as these systems become more pervasive, the need to understand how they fail, whether by the hand of an adversary or due to the inherent design of a system, will only become more pressing. In order to equip software developers, security incident responders, lawyers, and policy makers with a common vernacular to talk about this problem, we developed a framework to classify failures into "Intentional failures" where the failure is caused by an active adversary attempting to subvert the system to attain her goals; and "Unintentional failures" where the failure is because an ML system produces an inherently unsafe outcome. After developing the initial version of the taxonomy last year, we worked with security and ML teams across Microsoft, 23 external partners, standards organization, and governments to understand how stakeholders would use our framework. Throughout the paper, we attempt to highlight how machine learning failure modes are meaningfully different from traditional software failures from a technology and policy perspective.
Law and Adversarial Machine Learning
Oct 26, 2018When machine learning systems fail because of adversarial manipulation, how should society expect the law to respond? Through scenarios grounded in adversarial ML literature, we explore how some aspects of computer crime, copyright, and tort law interface with perturbation, poisoning, model stealing and model inversion attacks to show how some attacks are more likely to result in liability than others. We end with a call for action to ML researchers to invest in transparent benchmarks of attacks and defenses; architect ML systems with forensics in mind and finally, think more about adversarial machine learning in the context of civil liberties. The paper is targeted towards ML researchers who have no legal background.