 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegal Risks of Adversarial Machine Learning Research
Paper and Code
Jun 29, 2020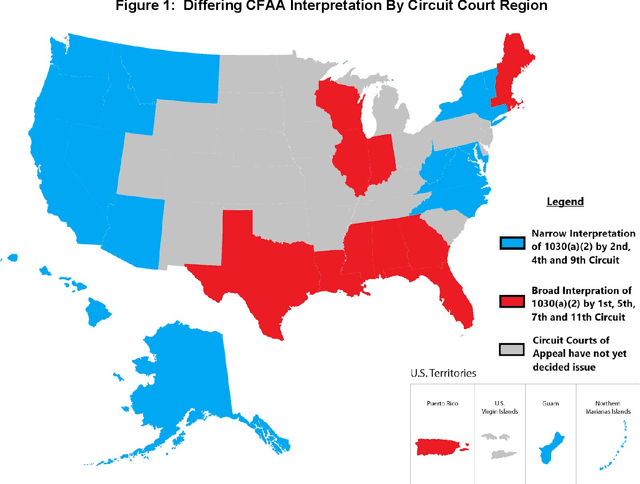
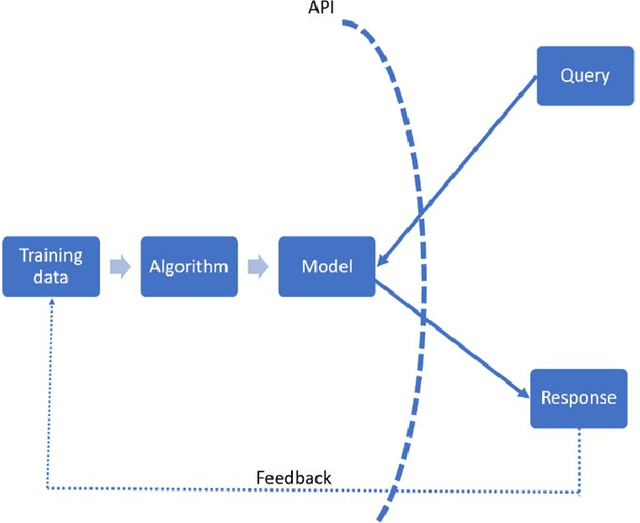

Adversarial Machine Learning is booming with ML researchers increasingly targeting commercial ML systems such as those used in Facebook, Tesla, Microsoft, IBM, Google to demonstrate vulnerabilities. In this paper, we ask, "What are the potential legal risks to adversarial ML researchers when they attack ML systems?" Studying or testing the security of any operational system potentially runs afoul the Computer Fraud and Abuse Act (CFAA), the primary United States federal statute that creates liability for hacking. We claim that Adversarial ML research is likely no different. Our analysis show that because there is a split in how CFAA is interpreted, aspects of adversarial ML attacks, such as model inversion, membership inference, model stealing, reprogramming the ML system and poisoning attacks, may be sanctioned in some jurisdictions and not penalized in others. We conclude with an analysis predicting how the US Supreme Court may resolve some present inconsistencies in the CFAA's application in Van Buren v. United States, an appeal expected to be decided in 2021. We argue that the court is likely to adopt a narrow construction of the CFAA, and that this will actually lead to better adversarial ML security outcomes in the long term.