 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Promptware Kill Chain: How Prompt Injections Gradually Evolved Into a Multi-Step Malware
Jan 14, 2026The rapid adoption of large language model (LLM)-based systems -- from chatbots to autonomous agents capable of executing code and financial transactions -- has created a new attack surface that existing security frameworks inadequately address. The dominant framing of these threats as "prompt injection" -- a catch-all phrase for security failures in LLM-based systems -- obscures a more complex reality: Attacks on LLM-based systems increasingly involve multi-step sequences that mirror traditional malware campaigns. In this paper, we propose that attacks targeting LLM-based applications constitute a distinct class of malware, which we term \textit{promptware}, and introduce a five-step kill chain model for analyzing these threats. The framework comprises Initial Access (prompt injection), Privilege Escalation (jailbreaking), Persistence (memory and retrieval poisoning), Lateral Movement (cross-system and cross-user propagation), and Actions on Objective (ranging from data exfiltration to unauthorized transactions). By mapping recent attacks to this structure, we demonstrate that LLM-related attacks follow systematic sequences analogous to traditional malware campaigns. The promptware kill chain offers security practitioners a structured methodology for threat modeling and provides a common vocabulary for researchers across AI safety and cybersecurity to address a rapidly evolving threat landscape.
Machine Learning Featurizations for AI Hacking of Political Systems
Oct 08, 2021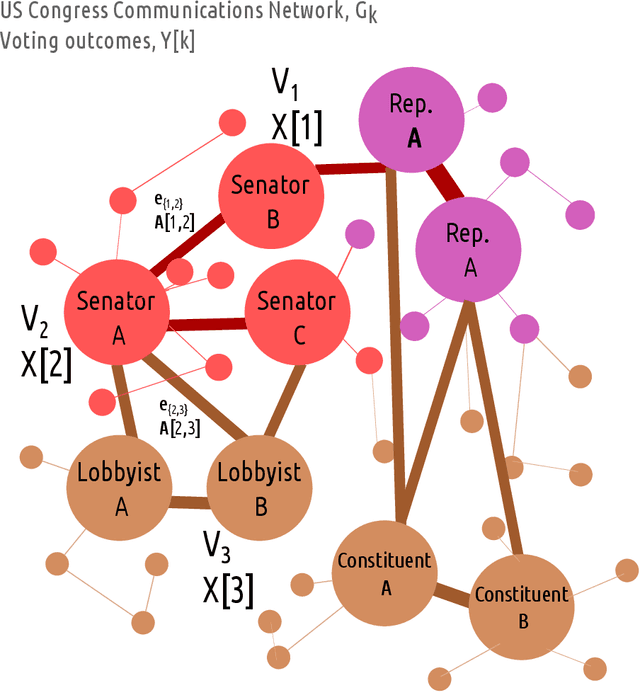
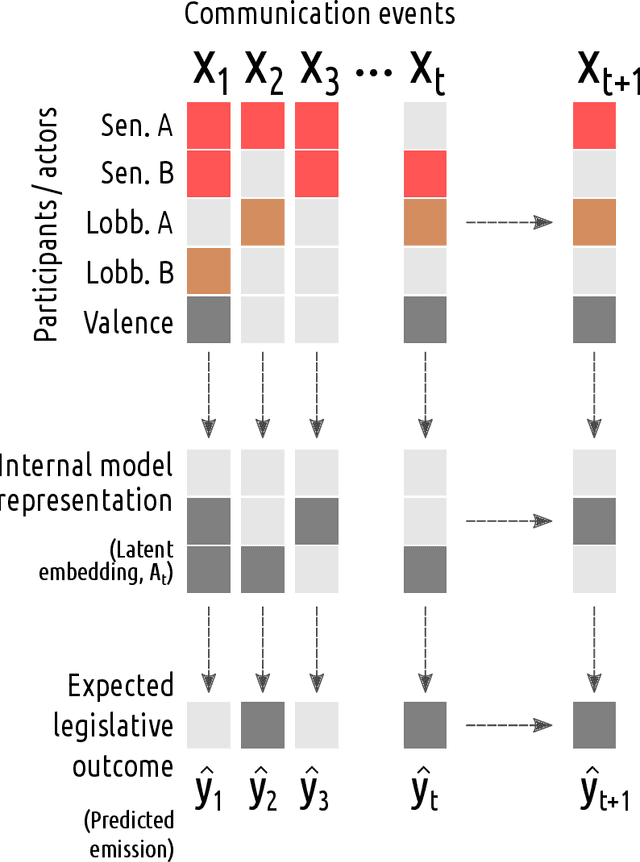
What would the inputs be to a machine whose output is the destabilization of a robust democracy, or whose emanations could disrupt the political power of nations? In the recent essay "The Coming AI Hackers," Schneier (2021) proposed a future application of artificial intelligences to discover, manipulate, and exploit vulnerabilities of social, economic, and political systems at speeds far greater than humans' ability to recognize and respond to such threats. This work advances the concept by applying to it theory from machine learning, hypothesizing some possible "featurization" (input specification and transformation) frameworks for AI hacking. Focusing on the political domain, we develop graph and sequence data representations that would enable the application of a range of deep learning models to predict attributes and outcomes of political systems. We explore possible data models, datasets, predictive tasks, and actionable applications associated with each framework. We speculate about the likely practical impact and feasibility of such models, and conclude by discussing their ethical implications.
Legal Risks of Adversarial Machine Learning Research
Jun 29, 2020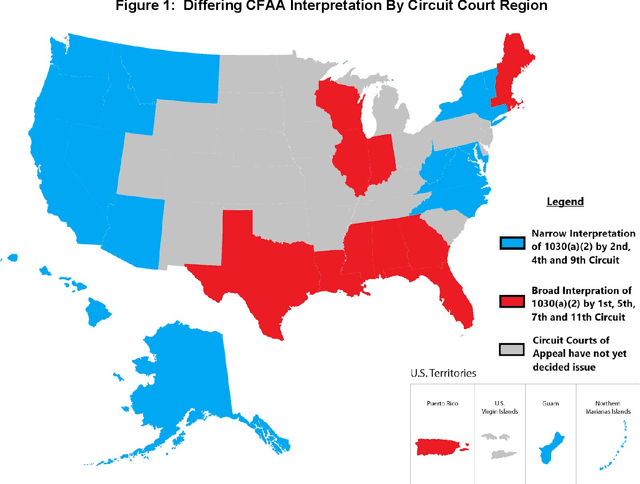
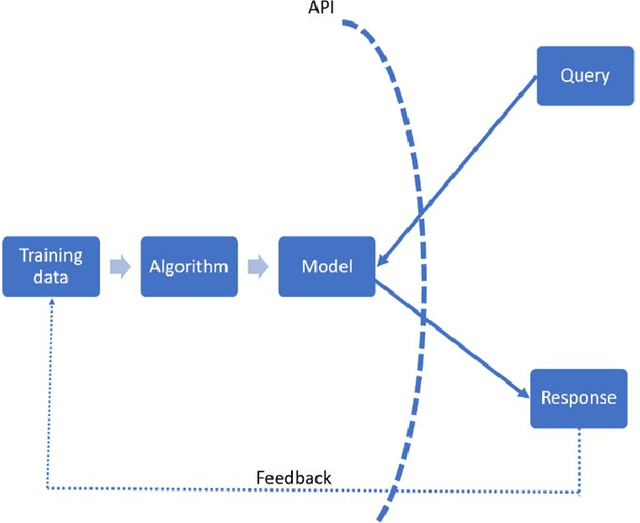

Adversarial Machine Learning is booming with ML researchers increasingly targeting commercial ML systems such as those used in Facebook, Tesla, Microsoft, IBM, Google to demonstrate vulnerabilities. In this paper, we ask, "What are the potential legal risks to adversarial ML researchers when they attack ML systems?" Studying or testing the security of any operational system potentially runs afoul the Computer Fraud and Abuse Act (CFAA), the primary United States federal statute that creates liability for hacking. We claim that Adversarial ML research is likely no different. Our analysis show that because there is a split in how CFAA is interpreted, aspects of adversarial ML attacks, such as model inversion, membership inference, model stealing, reprogramming the ML system and poisoning attacks, may be sanctioned in some jurisdictions and not penalized in others. We conclude with an analysis predicting how the US Supreme Court may resolve some present inconsistencies in the CFAA's application in Van Buren v. United States, an appeal expected to be decided in 2021. We argue that the court is likely to adopt a narrow construction of the CFAA, and that this will actually lead to better adversarial ML security outcomes in the long term.
Politics of Adversarial Machine Learning
Feb 19, 2020In addition to their security properties, adversarial machine-learning attacks and defenses have political dimensions. They enable or foreclose certain options for both the subjects of the machine learning systems and for those who deploy them, creating risks for civil liberties and human rights. In this paper, we draw on insights from science and technology studies, anthropology, and human rights literature, to inform how defenses against adversarial attacks can be used to suppress dissent and limit attempts to investigate machine learning systems. To make this concrete, we use real-world examples of how attacks such as perturbation, model inversion, or membership inference can be used for socially desirable ends. Although the predictions of this analysis may seem dire, there is hope. Efforts to address human rights concerns in the commercial spyware industry provide guidance for similar measures to ensure ML systems serve democratic, not authoritarian ends