 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSex Trouble: Common pitfalls in incorporating sex/gender in medical machine learning and how to avoid them
Paper and Code
Mar 15, 2022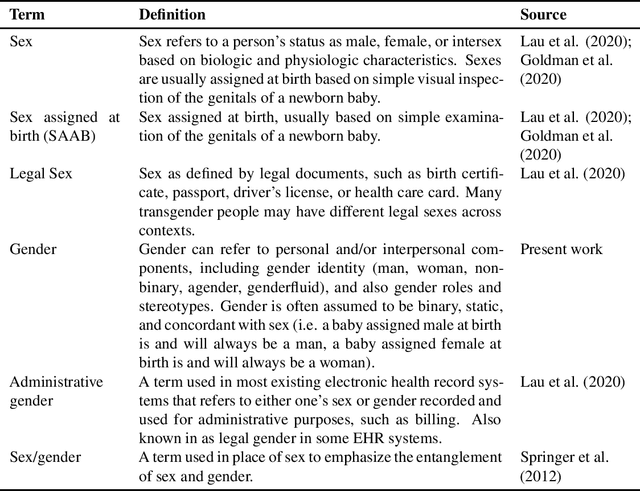
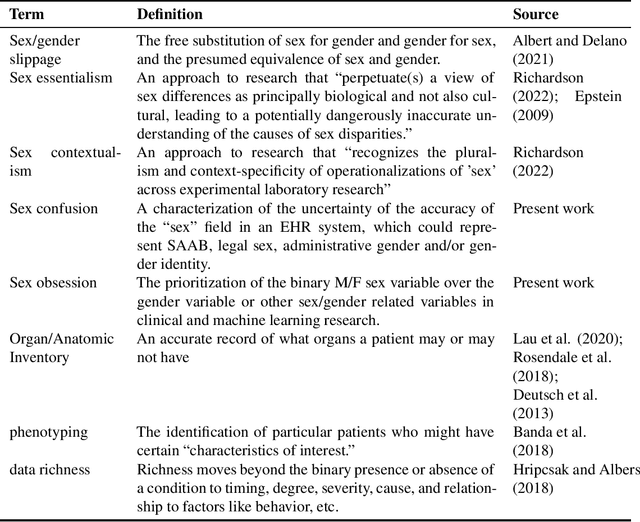
False assumptions about sex and gender are deeply embedded in the medical system, including that they are binary, static, and concordant. Machine learning researchers must understand the nature of these assumptions in order to avoid perpetuating them. In this perspectives piece, we identify three common mistakes that researchers make when dealing with sex/gender data: "sex confusion", the failure to identity what sex in a dataset does or doesn't mean; "sex obsession", the belief that sex, specifically sex assigned at birth, is the relevant variable for most applications; and "sex/gender slippage", the conflation of sex and gender even in contexts where only one or the other is known. We then discuss how these pitfalls show up in machine learning studies based on electronic health record data, which is commonly used for everything from retrospective analysis of patient outcomes to the development of algorithms to predict risk and administer care. Finally, we offer a series of recommendations about how machine learning researchers can produce both research and algorithms that more carefully engage with questions of sex/gender, better serving all patients, including transgender people.