 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShould I use Synthetic Data for That? An Analysis of the Suitability of Synthetic Data for Data Sharing and Augmentation
Feb 03, 2026Recent advances in generative modelling have led many to see synthetic data as the go-to solution for a range of problems around data access, scarcity, and under-representation. In this paper, we study three prominent use cases: (1) Sharing synthetic data as a proxy for proprietary datasets to enable statistical analyses while protecting privacy, (2) Augmenting machine learning training sets with synthetic data to improve model performance, and (3) Augmenting datasets with synthetic data to reduce variance in statistical estimation. For each use case, we formalise the problem setting and study, through formal analysis and case studies, under which conditions synthetic data can achieve its intended objectives. We identify fundamental and practical limits that constrain when synthetic data can serve as an effective solution for a particular problem. Our analysis reveals that due to these limits many existing or envisioned use cases of synthetic data are a poor problem fit. Our formalisations and classification of synthetic data use cases enable decision makers to assess whether synthetic data is a suitable approach for their specific data availability problem.
The Fundamental Limits of Least-Privilege Learning
Feb 19, 2024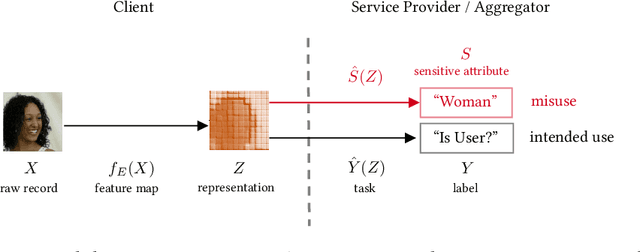

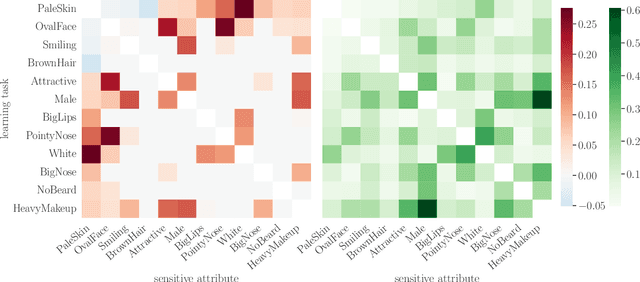

The promise of least-privilege learning -- to find feature representations that are useful for a learning task but prevent inference of any sensitive information unrelated to this task -- is highly appealing. However, so far this concept has only been stated informally. It thus remains an open question whether and how we can achieve this goal. In this work, we provide the first formalisation of the least-privilege principle for machine learning and characterise its feasibility. We prove that there is a fundamental trade-off between a representation's utility for a given task and its leakage beyond the intended task: it is not possible to learn representations that have high utility for the intended task but, at the same time prevent inference of any attribute other than the task label itself. This trade-off holds regardless of the technique used to learn the feature mappings that produce these representations. We empirically validate this result for a wide range of learning techniques, model architectures, and datasets.
Synthetic Data -- A Privacy Mirage
Dec 11, 2020
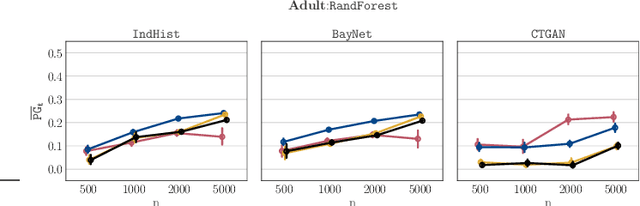
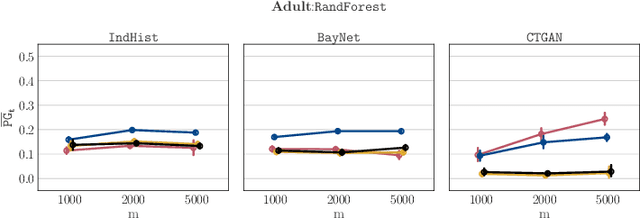
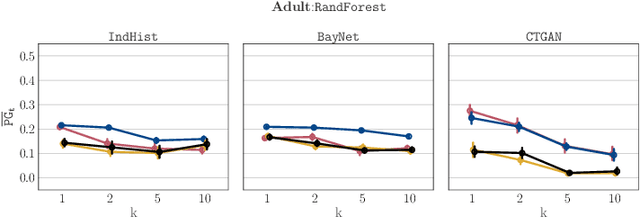
Synthetic datasets drawn from generative models have been advertised as a silver-bullet solution to privacy-preserving data publishing. In this work, we show through an extensive privacy evaluation that such claims do not match reality. First, synthetic data does not prevent attribute inference. Any data characteristics preserved by a generative model for the purpose of data analysis, can simultaneously be used by an adversary to reconstruct sensitive information about individuals. Second, synthetic data does not protect against linkage attacks. We demonstrate that high-dimensional synthetic datasets preserve much more information about the raw data than the features in the model's lower-dimensional approximation. This rich information can be exploited by an adversary even when models are trained under differential privacy. Moreover, we observe that some target records receive substantially less protection than others and that the more complex the generative model, the more difficult it is to predict which targets will remain vulnerable to inference attacks. Finally, we show why generative models are unlikely to ever become an appropriate solution to the problem of privacy-preserving data publishing.