 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fundamental Limits of Least-Privilege Learning
Feb 19, 2024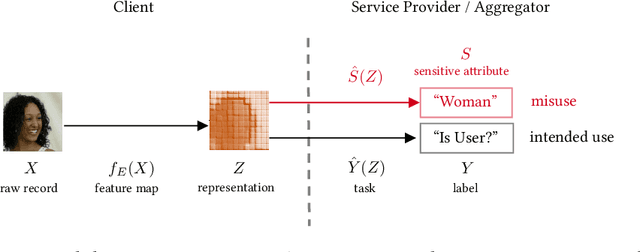

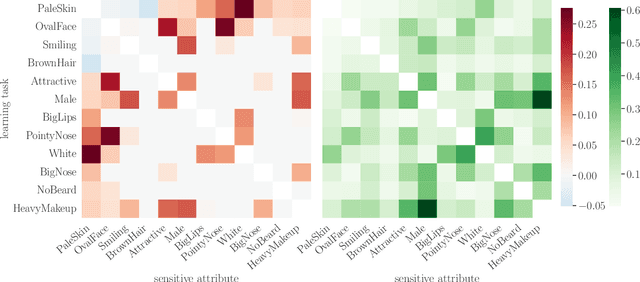

The promise of least-privilege learning -- to find feature representations that are useful for a learning task but prevent inference of any sensitive information unrelated to this task -- is highly appealing. However, so far this concept has only been stated informally. It thus remains an open question whether and how we can achieve this goal. In this work, we provide the first formalisation of the least-privilege principle for machine learning and characterise its feasibility. We prove that there is a fundamental trade-off between a representation's utility for a given task and its leakage beyond the intended task: it is not possible to learn representations that have high utility for the intended task but, at the same time prevent inference of any attribute other than the task label itself. This trade-off holds regardless of the technique used to learn the feature mappings that produce these representations. We empirically validate this result for a wide range of learning techniques, model architectures, and datasets.