 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobin Hood and Matthew Effects -- Differential Privacy Has Disparate Impact on Synthetic Data
Oct 01, 2021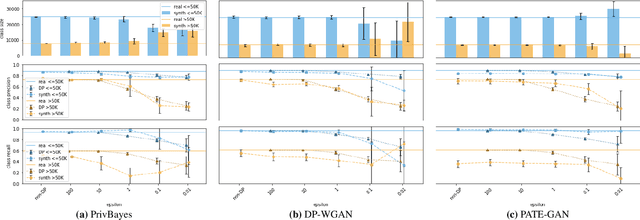
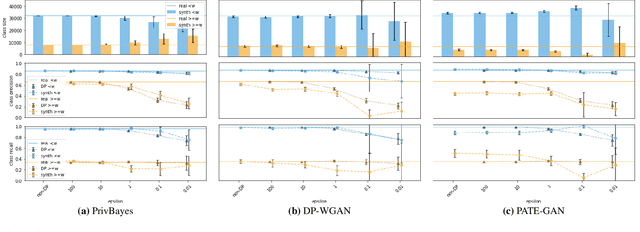
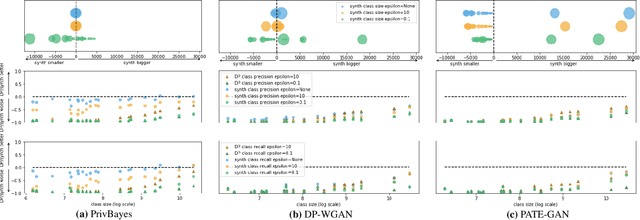
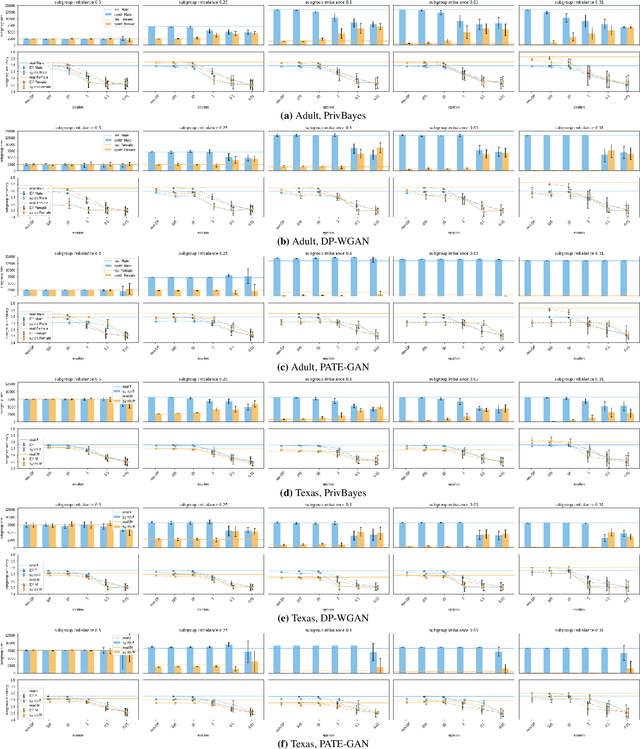
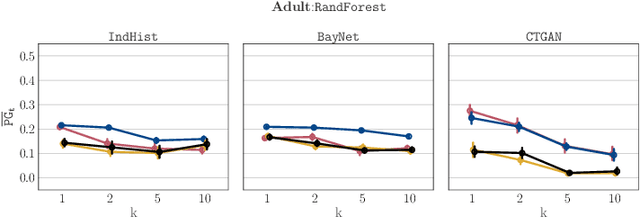
Generative models trained using Differential Privacy (DP) are increasingly used to produce and share synthetic data in a privacy-friendly manner. In this paper, we set out to analyze the impact of DP on these models vis-a-vis underrepresented classes and subgroups of data. We do so from two angles: 1) the size of classes and subgroups in the synthetic data, and 2) classification accuracy on them. We also evaluate the effect of various levels of imbalance and privacy budgets. Our experiments, conducted using three state-of-the-art DP models (PrivBayes, DP-WGAN, and PATE-GAN), show that DP results in opposite size distributions in the generated synthetic data. More precisely, it affects the gap between the majority and minority classes and subgroups, either reducing it (a "Robin Hood" effect) or increasing it ("Matthew" effect). However, both of these size shifts lead to similar disparate impacts on a classifier's accuracy, affecting disproportionately more the underrepresented subparts of the data. As a result, we call for caution when analyzing or training a model on synthetic data, or risk treating different subpopulations unevenly, which might also lead to unreliable conclusions.
Measuring Utility and Privacy of Synthetic Genomic Data
Feb 05, 2021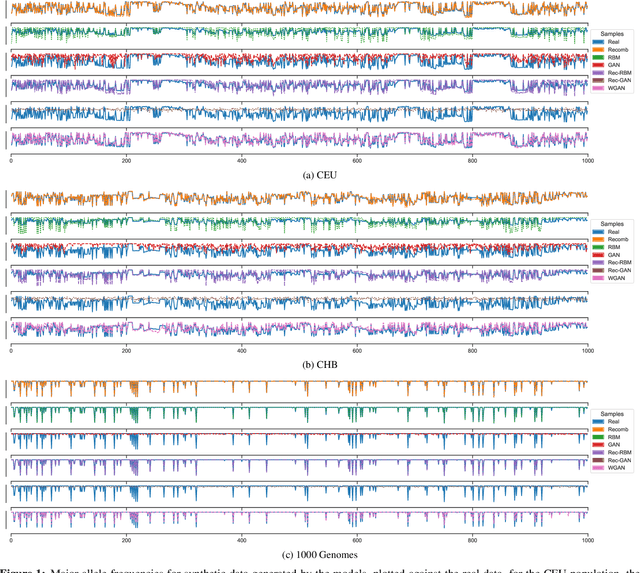


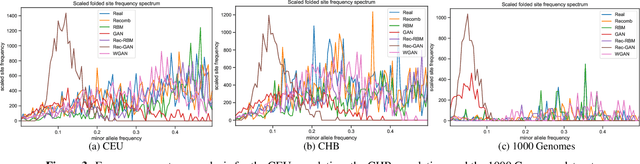
Genomic data provides researchers with an invaluable source of information to advance progress in biomedical research, personalized medicine, and drug development. At the same time, however, this data is extremely sensitive, which makes data sharing, and consequently availability, problematic if not outright impossible. As a result, organizations have begun to experiment with sharing synthetic data, which should mirror the real data's salient characteristics, without exposing it. In this paper, we provide the first evaluation of the utility and the privacy protection of five state-of-the-art models for generating synthetic genomic data. First, we assess the performance of the synthetic data on a number of common tasks, such as allele and population statistics as well as linkage disequilibrium and principal component analysis. Then, we study the susceptibility of the data to membership inference attacks, i.e., inferring whether a target record was part of the data used to train the model producing the synthetic dataset. Overall, there is no single approach for generating synthetic genomic data that performs well across the board. We show how the size and the nature of the training dataset matter, especially in the case of generative models. While some combinations of datasets and models produce synthetic data with distributions close to the real data, there often are target data points that are vulnerable to membership inference. Our measurement framework can be used by practitioners to assess the risks of deploying synthetic genomic data in the wild, and will serve as a benchmark tool for researchers and practitioners in the future.
Synthetic Data -- A Privacy Mirage
Dec 11, 2020
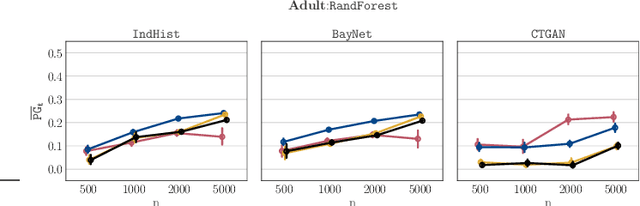
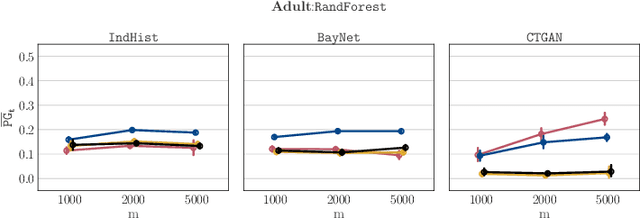
Synthetic datasets drawn from generative models have been advertised as a silver-bullet solution to privacy-preserving data publishing. In this work, we show through an extensive privacy evaluation that such claims do not match reality. First, synthetic data does not prevent attribute inference. Any data characteristics preserved by a generative model for the purpose of data analysis, can simultaneously be used by an adversary to reconstruct sensitive information about individuals. Second, synthetic data does not protect against linkage attacks. We demonstrate that high-dimensional synthetic datasets preserve much more information about the raw data than the features in the model's lower-dimensional approximation. This rich information can be exploited by an adversary even when models are trained under differential privacy. Moreover, we observe that some target records receive substantially less protection than others and that the more complex the generative model, the more difficult it is to predict which targets will remain vulnerable to inference attacks. Finally, we show why generative models are unlikely to ever become an appropriate solution to the problem of privacy-preserving data publishing.